1、String的基本特性
string :代表不可变的字符序列。简称:不可变性。
当对字符串重新赋值时,需要重写指定内存区域赋值,不能使用原有的 value进行赋值。
当对现有的字符串进行连接操作时,也需要重新指定内存区域赋值,不能使用原有的value进行赋值。
当调用 string 的 replace ( )方法修改指定字符或字符串时,也需要重新指定内存区域赋值,不能使用原有的value进行赋值。
通过字面量的方式(区别于 new )给一个字符串赋值,此时的字符串值声明在字符串常量池中。
例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public class StringTest { @Test public void test () { String s1 = "abc" ; String s2 = "abc" ; s1 = "hello" ; System.out.println(s1 == s2); System.out.println(s1); System.out.println(s2); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public class StringExer { String str = new String ("good" ); char [] ch = {'t' , 'e' , 's' , 't' }; public void change (String str, char ch[]) { str = "test ok" ; ch[0 ] = 'b' ; } public static void main (String[] args) { StringExer ex = new StringExer (); ex.change(ex.str, ex.ch); System.out.println(ex.str); System.out.println(ex.ch); } }
字符串常量池中是不会存储相同内容的字符串的。
string 的 string Pool 是一个固定大小的 Hashtable ,默认位大小长度是 1009 。如果放进String Pool 的String 非常多,就会造成 Hash 冲突严重,从而导致链表会很长,而链表长了后直接会造成的影响就是当调用 string.intern 时性能会大幅下降。
使用-XX : StringTableSize 可设置StringTable的长度,可通过”jinfo -flag StringTableSize 进程号“查看大小。 在 jdk6 中 StringTable 是固定的,就是 1009 的长度,所以如果常量池中的宇符串过多就会导致效率下降很快。StringTable的设置没要求。
在jdk7中StringTable的长度默认值是60013。StringTable的设置没要求。
在jdk8中StringTable的长度最小值是1009,默认值是60013,设置低于1009时会报错。
2、String的内存分配
在 Java 语言中有 8 种基本数据类型和一种比较特殊的类型 String 。这些类型为了使它们在运行过程中速度更快、更节省内存,都提供了一种常量池的概念。
8 种基本数据类型的常最池都是系统协调的, String 类型的常量池比较特殊。它的主要使用方法有两种。
直接使用双引号声明出来的 string 对象会直接存储在常量池中。
可以使用 string 提供的 intern方法。
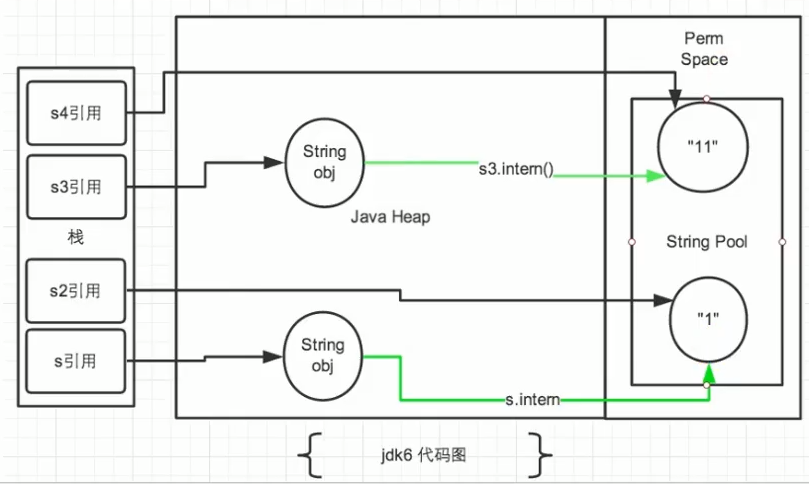
Java6 及以前,字符串常量池存放在永久代。
Java7 中 oracle 的工程师对字符串池的逻辑做了很大的改变,即将字符串常量池的位置调整到 Java 堆内。
所有的字符串都保存在堆( Heap )中,和其他普通对象一样,这样可以让你在进行调优应用时仅需要调整堆大小就可以了。
字符串常量池概念原本使用得比较多,但是这个改动使得我们有足够的理由让我们重新考虑在 Java7 中使用string.intern()。
Java8元空间,字符串常量池在堆。
例子1:
1 2 3 4 5 6 7 8 9 10 11 public class StringTest { public static void main (String[] args) { Set<String> set = new HashSet <String>(); short i = 0 ; while (true ){ set.add(String.valueOf(i++).intern()); } } }
jvm参数设置为:-XX:MetaspaceSize=6m -XX:MaxMetaspaceSize=6m -Xms6m -Xmx6m
报错如下,说明jdk8中的字符串常量池的确在堆中。
1 2 3 4 5 6 Exception in thread "main" java.lang.OutOfMemoryError: Java heap space at java.util.HashMap.resize(HashMap.java:704) at java.util.HashMap.putVal(HashMap.java:663) at java.util.HashMap.put(HashMap.java:612) at java.util.HashSet.add(HashSet.java:220) at com.company.java07.StringTest3.main(StringTest3.java:24)
例子2:
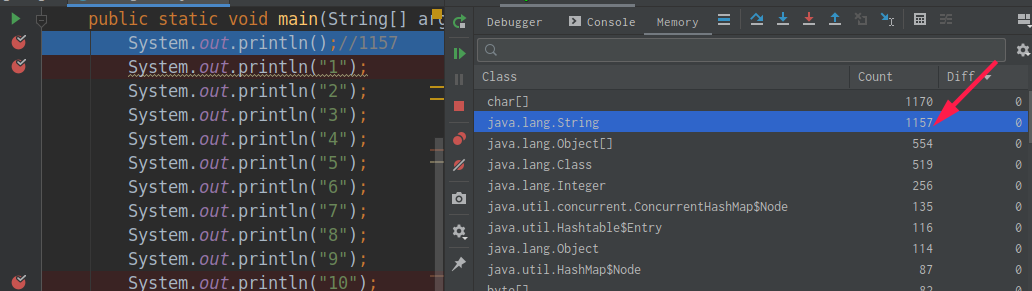
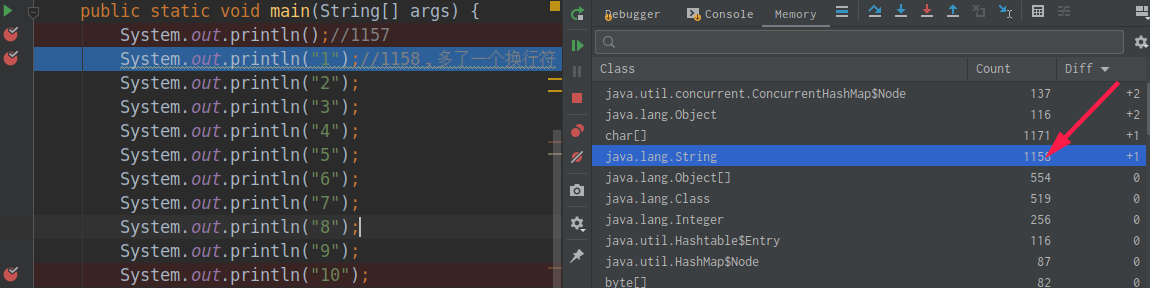
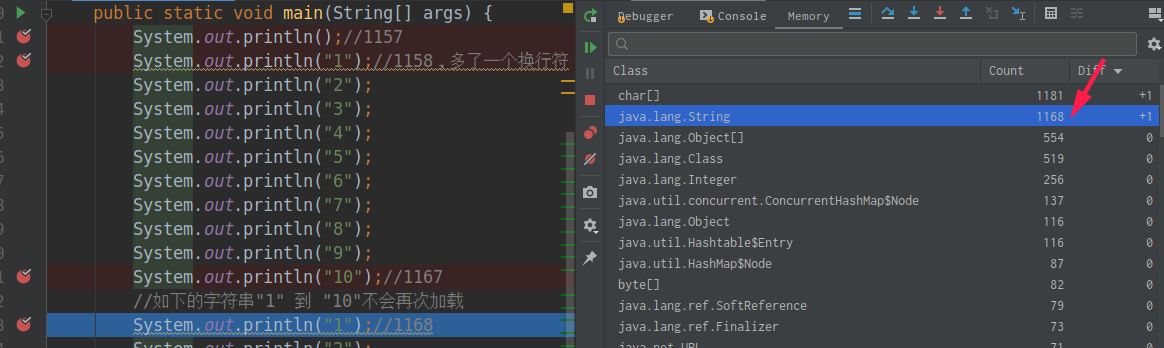
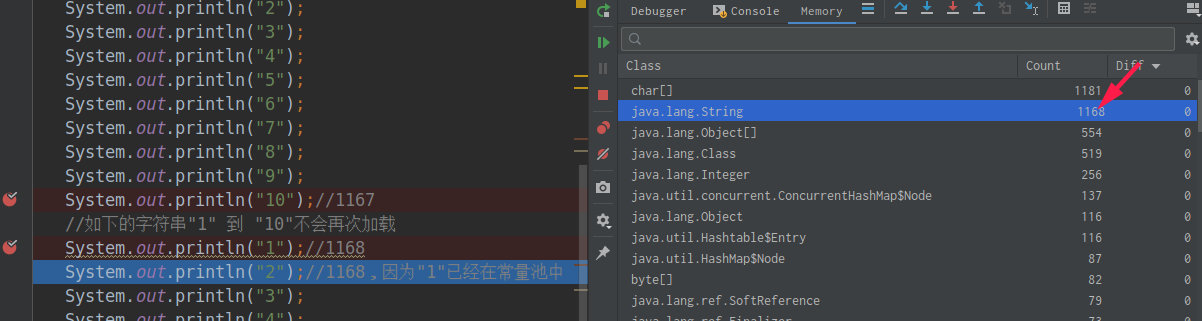
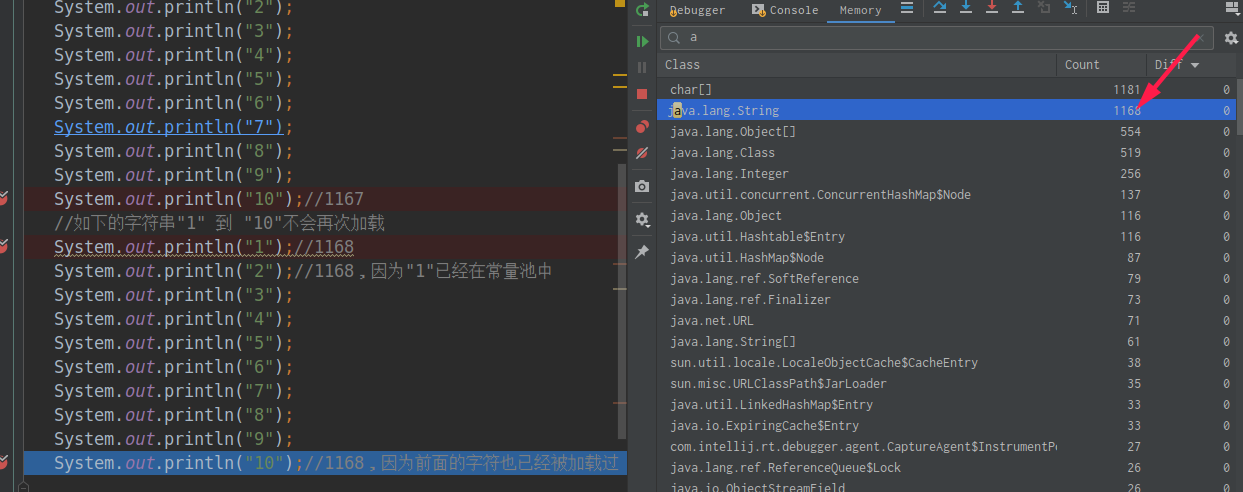
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public class StringTest { public static void main (String[] args) { System.out.println(); System.out.println("1" ); System.out.println("2" ); System.out.println("3" ); System.out.println("4" ); System.out.println("5" ); System.out.println("6" ); System.out.println("7" ); System.out.println("8" ); System.out.println("9" ); System.out.println("10" ); System.out.println("1" ); System.out.println("2" ); System.out.println("3" ); System.out.println("4" ); System.out.println("5" ); System.out.println("6" ); System.out.println("7" ); System.out.println("8" ); System.out.println("9" ); System.out.println("10" ); } }
例子3:
1 2 3 4 5 6 7 8 9 10 11 12 13 class Memory { public static void main (String[] args) { int i = 1 ; Object obj = new Object (); Memory mem = new Memory (); mem.foo(obj); } private void foo (Object param) { String str = param.toString(); System.out.println(str); } }
3、字符串拼接操作
常量与常量的拼接结果在常量池,原理是编译期优化。
常量池中不会存在相同内容的常量。
只要其中有一个是变量,结果就在堆中(不在堆里的字符串常量池里)。变量拼接的原理是StringBuilder。
如果拼接的结果调用intern方法,则主动将常童池中还没有的字符串对象放入池中,并返回此对象地址。
例子1:
1 2 3 4 5 6 7 8 9 10 11 12 @Test public void test () { String s1 = "a" + "b" + "c" ; String s2 = "abc" ; System.out.println(s1 == s2); System.out.println(s1.equals(s2)); }
例子2:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 @Test public void test () { String s1 = "javaEE" ; String s2 = "hadoop" ; String s3 = "javaEEhadoop" ; String s4 = "javaEE" + "hadoop" ; String s5 = s1 + "hadoop" ; String s6 = "javaEE" + s2; String s7 = s1 + s2; System.out.println(s3 == s4); System.out.println(s3 == s5); System.out.println(s3 == s6); System.out.println(s3 == s7); System.out.println(s5 == s6); System.out.println(s5 == s7); System.out.println(s6 == s7); String s8 = s6.intern(); System.out.println(s3 == s8); }
例子3:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 @Test public void test () { String s1 = "a" ; String s2 = "b" ; String s3 = "ab" ; String s4 = s1 + s2; System.out.println(s3 == s4); }
其中,s1 + s2的执行细节(可通过字节码文件验证):
① StringBuilder s = new StringBuilder();(变量s是临时定义的,且在jdk5.0之后使用的是StringBuilder,在jdk5.0之前使用的是StringBuffer)
② s.append(“a”)
③ s.append(“b”)
④ s.toString() –> 约等于 new String(“ab”)
例子4:
1 2 3 4 5 6 7 8 @Test public void test () { final String s1 = "a" ; final String s2 = "b" ; String s3 = "ab" ; String s4 = s1 + s2; System.out.println(s3 == s4); }
字符串拼接操作不一定使用的是StringBuilder:如果拼接符号左右两边都是字符串常量或常量引用,则仍然使用编译期优化,即非StringBuilder的方式。
针对于final修饰类、方法、基本数据类型、引用数据类型的量的结构时,能使用上final的时候建议使用。(因为在类加载时就确定值了)
例子5:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 @Test public void test () { long start = System.currentTimeMillis(); method2(100000 ); long end = System.currentTimeMillis(); System.out.println("花费的时间为:" + (end - start)); } public void method1 (int highLevel) { String src = "" ; for (int i = 0 ;i < highLevel;i++){ src = src + "a" ; } } public void method2 (int highLevel) { StringBuilder src = new StringBuilder (); for (int i = 0 ; i < highLevel; i++) { src.append("a" ); } }
通过对比发现:通过StringBuilder的append()的方式添加字符串的效率要远高于使用String的字符串拼接方式!
① StringBuilder的append()的方式:自始至终中只创建过一个StringBuilder的对象,而使用String的字符串拼接方式:创建过多个StringBuilder和String的对象。
② 使用String的字符串拼接方式:内存中由于创建了较多的StringBuilder和String的对象,内存占用更大;如果进行GC,需要花费额外的时间。
在实际开发中,如果基本确定要前前后后添加的字符串长度不高于某个限定值highLevel的情况下,建议使用构造器实例化:StringBuilder s = new StringBuilder(highLevel);//new char[highLevel]。
例子6:
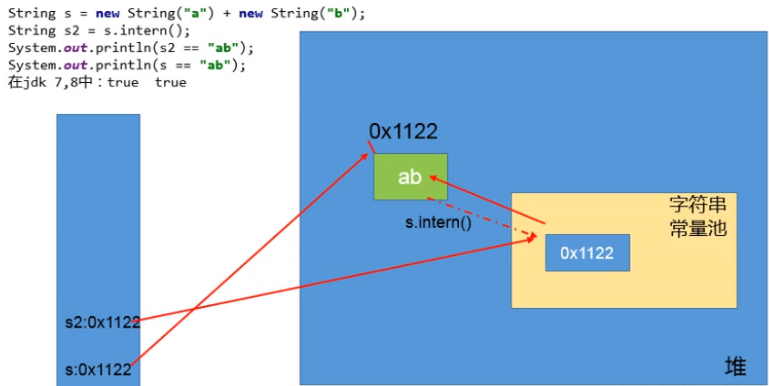
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 public class StringNewTest { public static void main (String[] args) { String str = new String ("ab" ); String str = new String ("a" ) + new String ("b" ); } }
4、intern的使用
如果不是用双引号声明的 string 对象,可以使用 string 提供的 intern 方法: intern 方法会从字符串常量池中查询当前字符串是否存在,若不存在就会将当前字符串放入常量池中。
也就是说,如果在任意字符串上调用 string.intern 方法,那么其返回结果所指向的那个类实例,必须和直接以常量形式出现的字符串实例完全相同。因此,下列表达式的值必定是 true :
( “ a “ + “ b “ + “ c “ ) . intern ( ) = = “ abc “
通俗点讲, Interned string 就是确保字符串在内存里只有一份拷贝,这样可以节约内存空间,加快字符串操作任务的执行速度。注意,这个值会被存放在字符串内部池 ( String Intern Pool)。
例子:
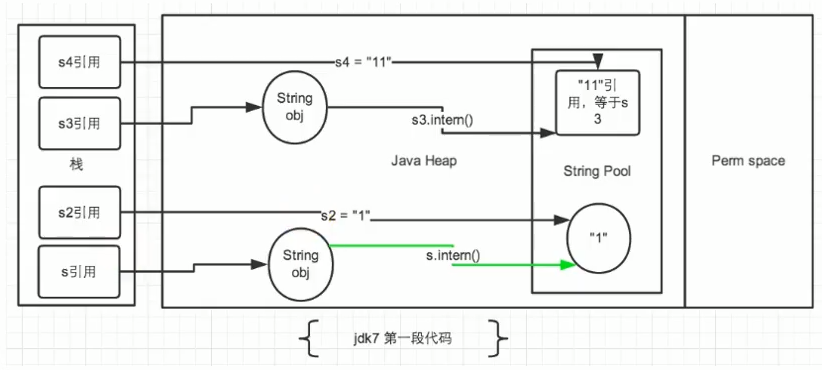
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public class StringIntern { public static void main (String[] args) { String s = new String ("1" ); s.intern(); String s2 = "1" ; System.out.println(s == s2); String s3 = new String ("1" ) + new String ("1" ); s3.intern(); String s4 = "11" ; System.out.println(s3 == s4); } }
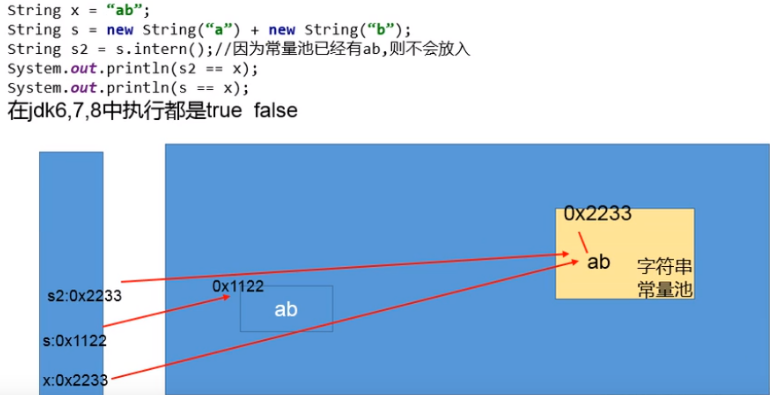
对比:
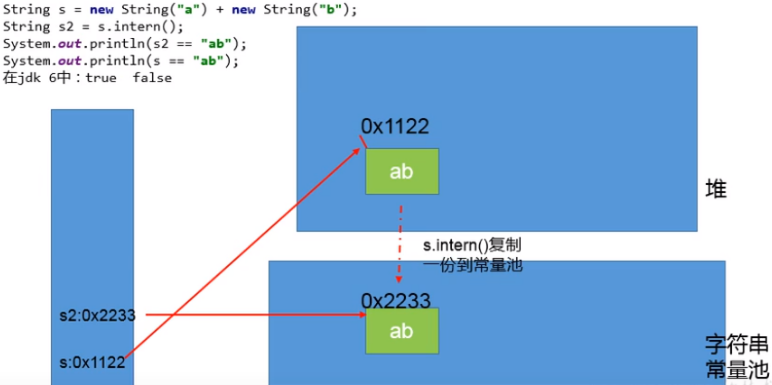
1 2 3 4 5 6 7 8 9 10 public class StringIntern { public static void main (String[] args) { String s3 = new String ("1" ) + new String ("1" ); String s5 = s3.intern(); String s4 = "11" ; System.out.println(s3 == s4); System.out.println(s5 == s4); } }
总结:
jdk1.6 中,将这个字符串对象尝试放入串池。
如果串池中有,则并不会放入。返回已有的串池中的对象地址。
如果没有,会把此对象复制一份,放入串池,并返回串池中的对象地址。
jdk1.7 起,将这个字符串对象尝试放入串池。
如果串池中有,则并不会放入。返回已有的串池中的对象地址。
如果没有,则会把对象的引用地址复制一份,放入串池,并返回串池中的引用地址。
5、StringTable的垃圾回收 1 2 3 4 5 6 7 8 public class StringGCTest { public static void main (String[] args) { for (int j = 0 ; j < 100000 ; j++) { String.valueOf(j).intern(); } } }
JVM参数设置为:-Xms15m -Xmx15m -XX:+PrintStringTableStatistics -XX:+PrintGCDetails
从控制台打印信息可知发生了垃圾回收。
1 2 3 4 5 6 7 8 9 10 11 [GC (Allocation Failure) [PSYoungGen: 4096K->432K(4608K)] 4096K->440K(15872K), 0.0026018 secs] [Times: user=0.01 sys=0.00, real=0.00 secs] StringTable statistics: Number of buckets : 60013 = 480104 bytes, avg 8.000 Number of entries : 49343 = 1184232 bytes, avg 24.000 Number of literals : 49343 = 2772216 bytes, avg 56.183 Total footprint : = 4436552 bytes Average bucket size : 0.822 Variance of bucket size : 0.643 Std. dev. of bucket size: 0.802 Maximum bucket size : 5