浅堆和深堆
1、浅堆
浅堆(Shallow Heap)是指一个对象所消耗的内存。在32位系统中,一个对象引用会占据4个字节,一个int类型会占据4个字节,long型变量会占据8个字节,每个对象头需要占用8个字节。根据堆快照格式不同,对象的大小可能会向8字节进行对齐。
- 对象头 = 标记部分 + 原始对象引用。
- 标记部分包括hashcode、gc分代年龄、锁状态标志、线程持有锁、偏向线程锁id,偏向时间戳,这一部分在32位机器上为4byte,64位机器上为8byte。
- 原始对象引用是对象的指针、通过这个指针找到对象的实例、该数据可以压缩,这一部分在32位机器上为4byte,64位机器上为8byte,如果开启了压缩(UseCompreddedOops),大小为4byte,jdk8默认开启压缩。
- 一个对象头大小(64位) =12byte(压缩)或16byte(未压缩)
以String为例:2个int值共占8字节,对象引用占用4字节,对象头8字节,合计20字节,向8字节对齐,故占24字节。(jdk7中)
- 这24字节为String对象的浅堆大小。它与String的value实际取值无关,无论字符串长度如何,浅堆大小始终是24字节。
2、深堆
保留集(Retained Set):象A的保留集指当对象A被垃圾回收后,可以被释放的所有的对象集合(包括对象A本身),即对象A的保留集可以被认为是只能通过对A被直接或间接访问到的所有对象的集合。通俗地说,就是指仅被对象A所持有的对象的集合。
深堆(Retained Heap):深堆是指对象的保留集中所有的对象的浅堆大小之和。
注意:浅堆指对象本身占用的内存,不包括其内部引用对象的大小。一个对象的深堆指只能通过该对象访问到的(直接或间接)所有对象的浅堆之和,即对象被回收后,可以释放的真实空间。
另外一个常用的概念是对象的实际大小。这里,对象的实际大小定义为一个对象所能触及的所有对象的浅堆大小之和,也就是通常意义上我们说的对象大小。与深堆相比,似乎这个在日常开发中更为直观和被人接受,但实际上,这个概念和垃圾回收无关。
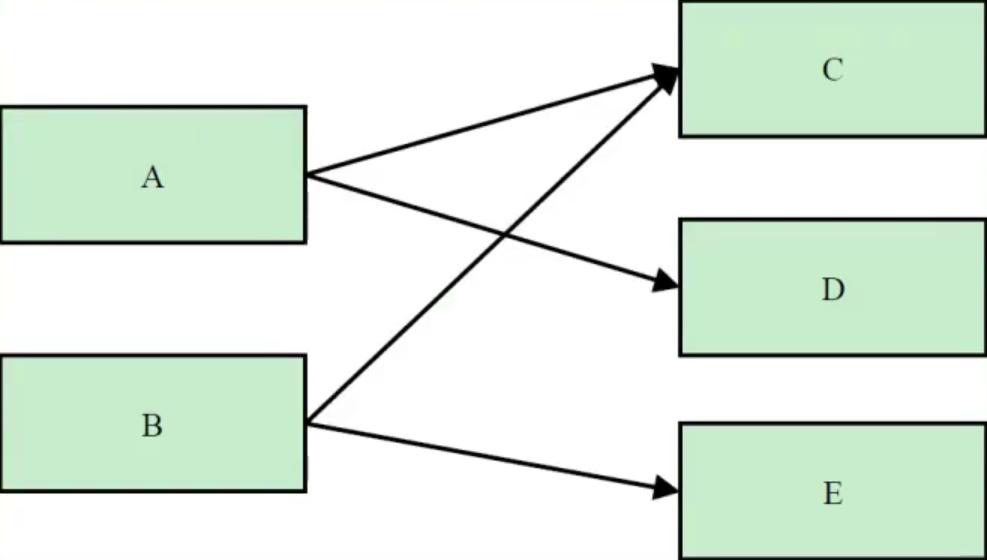
下图显示了一个简单的对象引用关系图,对象A引用了C和D,对象B引用了C和E。那么对象A的浅堆大小只是A本身,不含C和D,而A的实际大小为A、C、D三者之和。而A的深堆大小为A与D之和,由于对象C还可以通过对象B访问到,因此不在对象A的深堆范围内。
![]()
3、实际案例分析
测试代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98/**
* 虚拟机参数:-XX:+HeapDumpBeforeFullGC -XX:HeapDumpPath=e:\matlog\student.hprof
*/
public class StudentTrace {
static List<WebPage> webpages = new ArrayList<WebPage>();
public static void createWebPages() {
for (int i = 0; i < 100; i++) {
WebPage wp = new WebPage();
wp.setUrl("http://www." + Integer.toString(i) + ".com");
wp.setContent(Integer.toString(i));
webpages.add(wp);
}
}
public static void main(String[] args) {
createWebPages();//创建了100个网页
//创建3个学生对象
Student st3 = new Student(3, "Tom");
Student st5 = new Student(5, "Jerry");
Student st7 = new Student(7, "Lily");
for (int i = 0; i < webpages.size(); i++) {
if (i % st3.getId() == 0)
st3.visit(webpages.get(i));
if (i % st5.getId() == 0)
st5.visit(webpages.get(i));
if (i % st7.getId() == 0)
st7.visit(webpages.get(i));
}
webpages.clear();
System.gc();
}
}
class Student {
private int id;
private String name;
private List<WebPage> history = new ArrayList<>();
public Student(int id, String name) {
super();
this.id = id;
this.name = name;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public List<WebPage> getHistory() {
return history;
}
public void setHistory(List<WebPage> history) {
this.history = history;
}
public void visit(WebPage wp) {
if (wp != null) {
history.add(wp);
}
}
}
class WebPage {
private String url;
private String content;
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
}运行程序后,会在相应目录下生成dump文件。
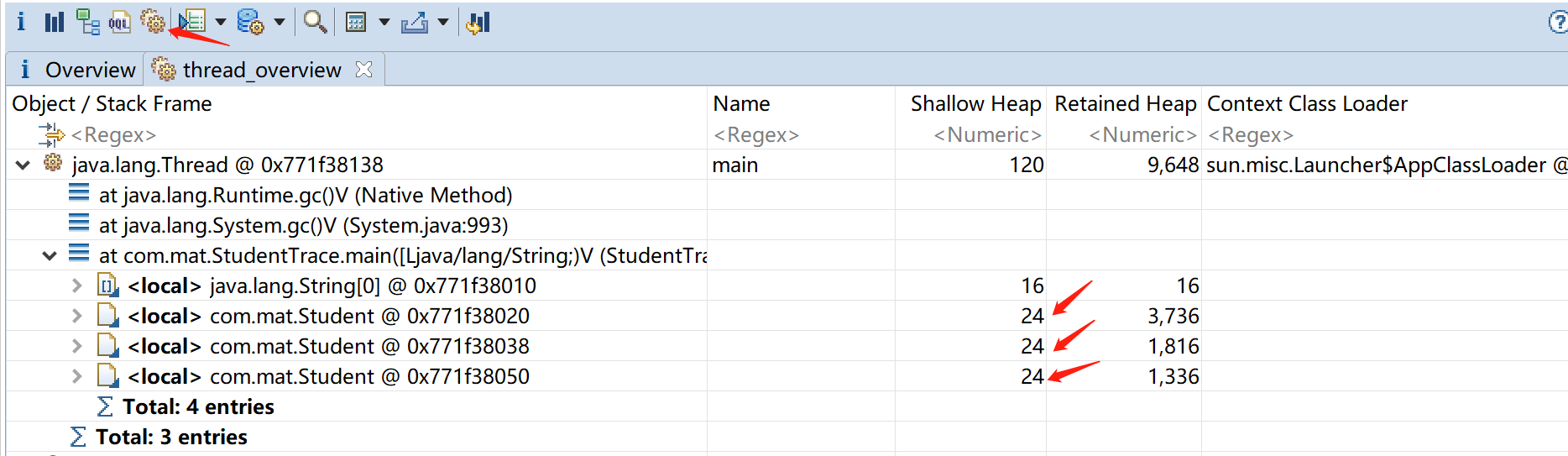
使用MemoryAnalyzer分析工具打开,查看该程序的线程信息,能发现main函数中有三个student对象且浅堆(Shallow Heap)都占24个字节(id、name和history的引用各占4个字节,以及加上student对象头标记部分的8个字节,即3*4+8=20,最后向8字节对齐,故占24字节)
![]()
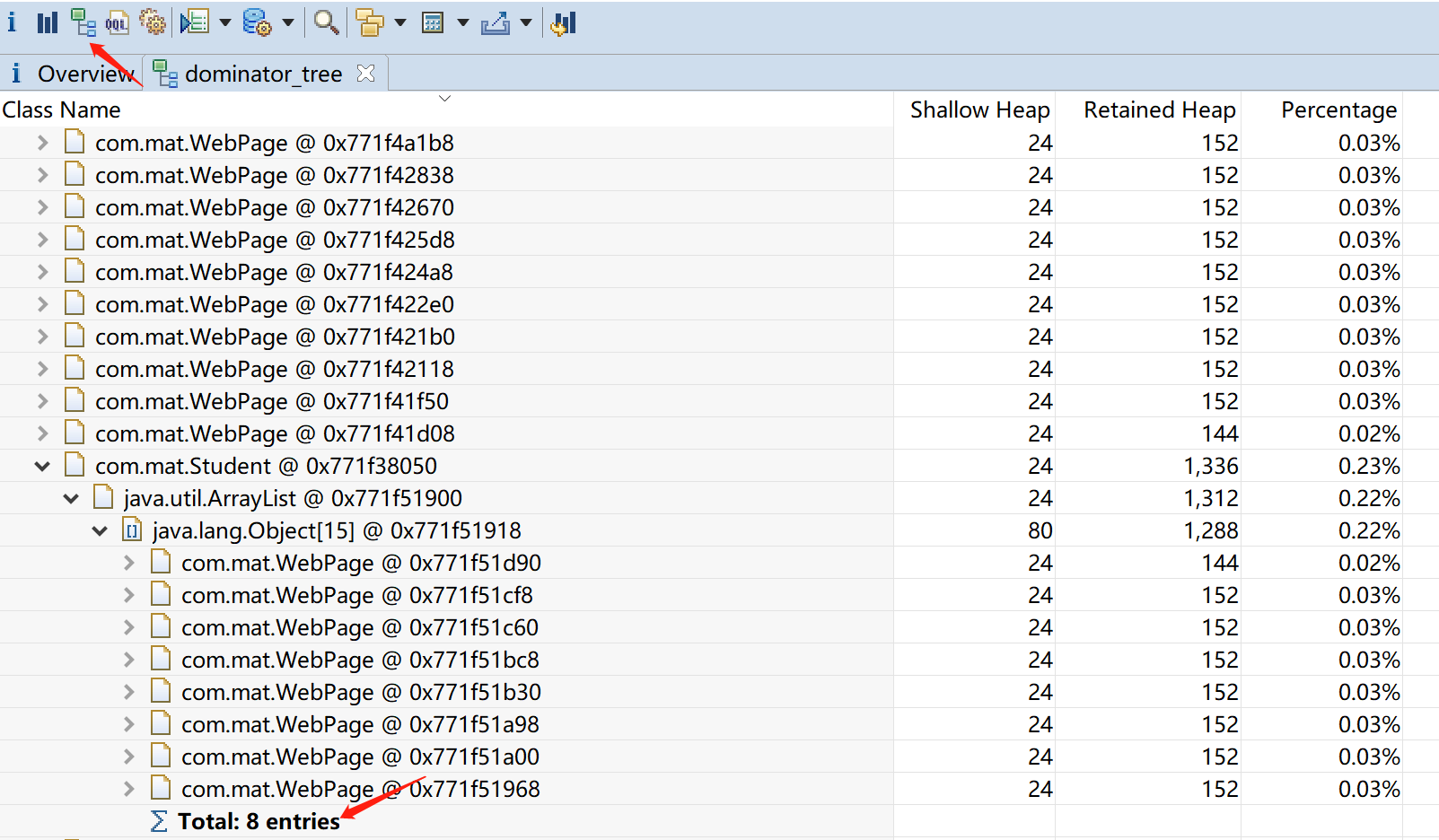
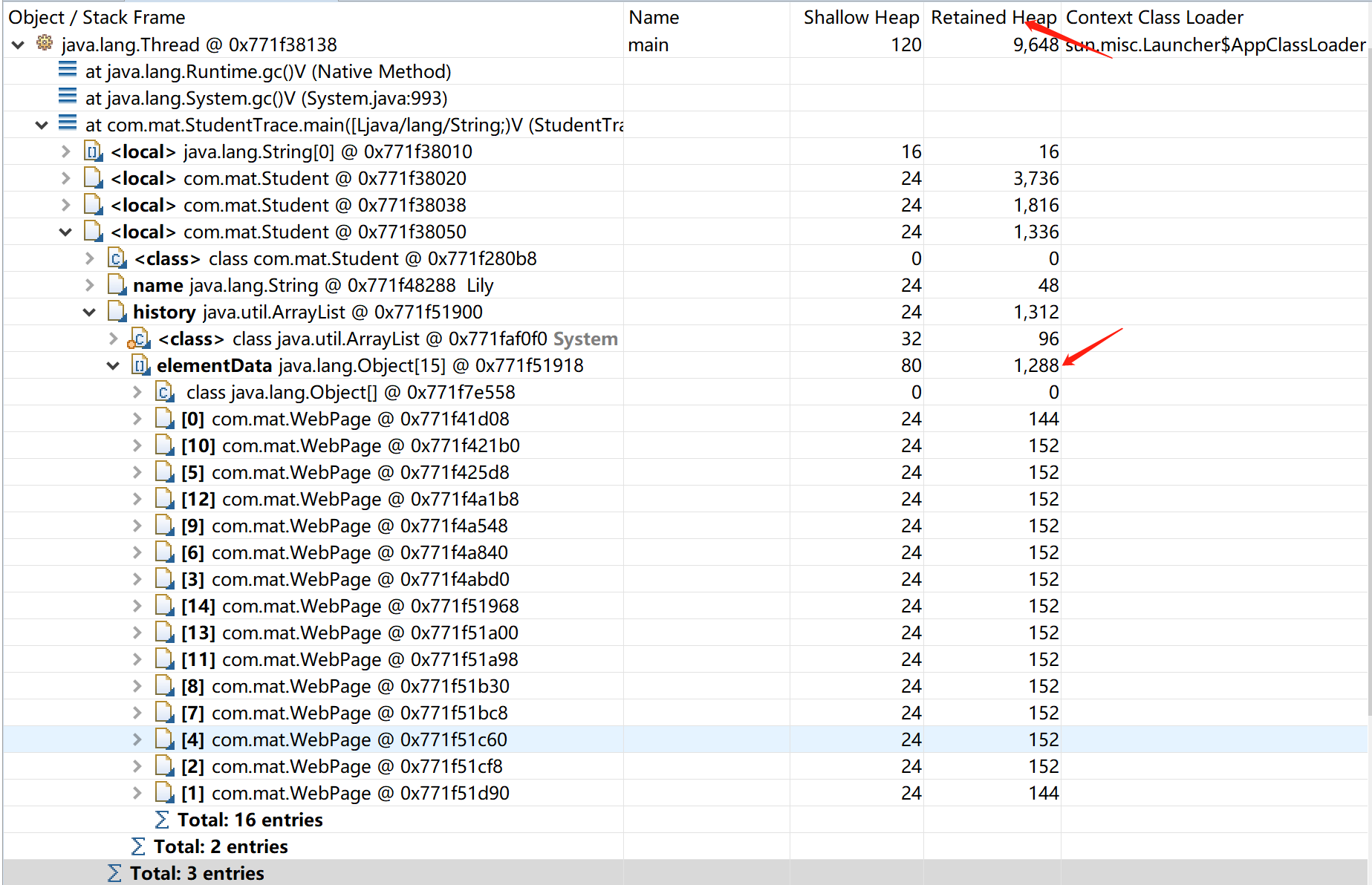
进一步分析每个student的深堆(Retained Heap)大小,这里以第三个Student对象的history属性为例:
![]()
- 能回收的数组引用的对象总字节数有:8*152=1216(排除掉另外满足”能被7、5同时整除,以及能被7、3同时整除的数”的7个对象分别是”0、21、42、63、84、35、70”,所以能回收的一共是15-7=8个对象)
- elementData数组本身能回收的总字节数有:15个elementData元素*4+8字节的数组对象头+4字节的数组长度=60+8+4=72
- 综上1216+72=1288(字节)
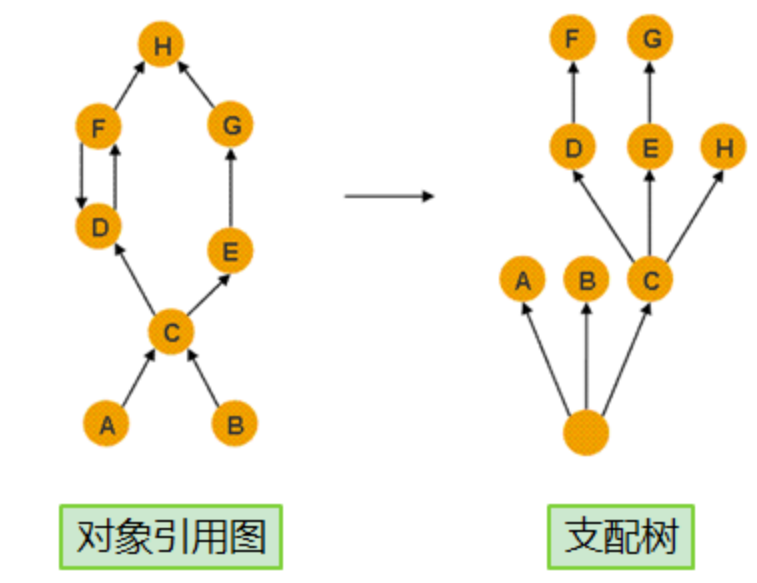
4、支配树
MAT提供了一个称为支配树(Dominator Tree)的对象图。支配树体现了对象实例间的支配关系。在对象引用图中,所有指向对象B的路径都经过对象A,则认为对象A支配对象B。如果对象A是离对象B最近的一个支配对象,则认为对象A为对象B的直接支配者。支配树是基于对象间的引用图所建立的,它有以下基本性质:
- 对象A的子树(所有被对象A支配的对象集合)表示对象A的保留集(retained set),即深堆。
- 如果对象A支配对象B,那么对象A的直接支配者也支配对象B。
- 支配树的边与对象引用图的边不直接对应。
如下图所示:左图表示对象引用图,右图表示左图所对应的支配树。对象A和B由根对象直接支配,由于在到对象C的路径中,可以经过A,也可以经过B,因此对象C的直接支配者也是根对象。对象F与对象D相互引用,因为到对象F的所有路径必然经过对象D,因此,对象D是对象F的直接支配者。而到对象D的所有路径中,必然经过对象C,即使是从对象F到对象D的引用,从根节点出发,也是经过对象c的,所以,对象D的直接支配者为对象C。
![]()
有了支配树的概念后,可以在MAT中验证刚才分析的第三个Student对象中的数组实际上只能回收8个元素。
![]()