Flink简介与快速上手
1、初识Flink
1.1 Flink的源起和设计理念
Flink起源于一个叫作Stratosphere的项目,它是由3所地处柏林的大学和欧洲其他一些大学在2010~2014年共同进行的研究项目,由柏林理工大学的教授沃克尔·马尔科(Volker Markl) 领衔开发。2014年4月,Stratosphere的代码被复制并捐赠给了Apache软件基金会,Flink就是在此基础上被重新设计出来的。
从命名上,我们也可以看出Flink项目对于自身特点的定位,那就是对于大数据处理,要做到快速和灵活。
- 2014年8月,Flink第一个版本0.6正式发布(至于0.5之前的版本,那就是在Stratosphere名下的了)。与此同时 Fink 的几位核心开发者创办了Data Artisans公司, 主要做Fink的商业应用,帮助企业部署大规模数据处理解决方案。
- 2014年12月,Flink项目完成了孵化,一跃成为Apache软件基金会的顶级项目。
- 2015年4月,Flink发布了里程碑式的重要版本0.9.0,很多国内外大公司也正是从这时开始关注、并参与到Flink社区建设的。
- 2019年1月,长期对Flink投入研发的阿里巴巴,以9000万欧元的价格收购了Data Artisans公司;之后又将自己的内部版本Blink开源,继而与8月份发布的Flink 1.9.0版本进行了合并。自此之后,Flink被越来越多的人所熟知,成为当前最火的新一代大数据处理框架。
具体定位是:Apache Flink是一个框架和分布式处理引擎,如图 1-2 所示,用于对无界和有界数据流进行有状态计算。Flink被设计在所有常见的集群环境中运行,以内存执行速度和任意规模来执行计算。
![]()
1.2 Flink的应用
1.2.1 Flink在企业中的应用
- 对于数据处理而言,任何行业、任何公司的需求其实都是一样的:数据规模大、实时性要求高、确保结果准确、方便扩展、故障后可恢复——而这些要求,作为新一代大数据流式处理引擎的Flink统统可以满足!这也正是Flink在全世界范围得到广泛应用的原因。
- 以大家熟悉的阿里为例。阿里巴巴这个庞大的电商公司,为买方和卖方提供了交易平台。 它的个性化搜索和实时推荐功能就是通过Blink实现的(当然我们知道,Blink就是基于Flink的,现在两者也已合体)。用户所购买或者浏览的商品,可以被用作推荐的依据,这就是为什 么我们经常发现“刚看过什么、网站就推出来了”。当用户数据量非常庞大时,快速地分析响应、 实时做出精准的推荐就显得尤为困难。而Flink这样真正意义上的大数据流处理引擎,就能做到这些。这也是阿里在Flink上充分发力并成为引领者的原因。
1.2.2 Flink主要的应用场景
- 回到Flink本身的定位,它是一个大数据流式处理引擎,处理的是流式数据,也就是“数据流”(Data Flow)。顾名思义,数据流的含义是,数据并不是收集好的,而是像水流一样, 是一组有序的数据序列,逐个到来、逐个处理。由于数据来到之后就会被即刻处理,所以流处理的一大特点就是“快速”,也就是良好的实时性。Flink适合的场景,其实也就是需要实时处理数据流的场景。具体来看,一些行业中的典型应用有:
- 电商和市场营销。
- 举例:实时数据报表、广告投放、实时推荐。
- 在电商行业中,网站点击量是统计PV、UV的重要来源,也是如今“流量经济”的最主要数据指标。很多公司的营销策略,比如广告的投放,也是基于点击量来决定的。另外,在网站上提供给用户的实时推荐,往往也是基于当前用户的点击行为做出的。
- 网站获得的点击数据可能是连续且不均匀的,还可能在同一时间大量产生,这是典型的数据流。如果我们希望把它们全部收集起来,再去分析处理,就会面临很多问题:首先,我们需要很大的空间来存储数据;其次,收集数据的过程耗去了大量时间,统计分析结果的实时性就大大降低了;另外,分布式处理无法保证数据的顺序,如果我们只以数据进入系统的时间为准,可能导致最终结果计算错误。
- 我们需要的是直接处理数据流,而Flink就可以做到这一点。
- 物联网(IOT)。
- 举例:传感器实时数据采集和显示、实时报警,交通运输业。
- 物联网是流数据被普遍应用的领域。各种传感器不停获得测量数据,并将它们以流的形式传输至数据中心。而数据中心会将数据处理分析之后,得到运行状态或者报警信息,实时地显示在监控屏幕上。所以在物联网中,低延迟的数据传输和处理,以及准确的数据分析通常很关键。
- 交通运输业也体现了流处理的重要性。比如说,如今高铁运行主要就是依靠传感器检测数据,测量数据包括列车的速度和位置,以及轨道周边的状况。这些数据会从轨道传给列车,再从列车传到沿途的其他传感器;与此同时,数据报告也被发送回控制中心。因为列车处于高速行驶状态,因此数据处理的实时性要求是极高的。如果流数据没有被及时正确处理,调整意见和警告就不能相应产生,后果可能会非常严重。
- 物流配送和服务业。
- 举例:订单状态实时更新、通知信息推送。
- 在很多服务型应用中,都会涉及订单状态的更新和通知的推送。这些信息基于事件触发, 不均匀地连续不断生成,处理之后需要及时传递给用户。这也是非常典型的数据流的处理。
- 银行和金融业。
- 举例:实时结算和通知推送,实时检测异常行为。
- 银行和金融业是另一个典型的应用行业。用户的交易行为是连续大量发生的,银行面对的是海量的流式数据。由于要处理的交易数据量太大,以前的银行是按天结算的,汇款一般都要隔天才能到账。所以有一个说法叫作“银行家工作时间”,说的就是银行家不仅不需要996,甚至下午早早就下班了:因为银行需要早点关门进行结算,这样才能保证第二天营业之前算出准确的账。这显然不能满足我们快速交易的需求。在全球化经济中,能够提供24小时服务变得越来越重要。现在交易和报表都会快速准确地生成,我们跨行转账也可以做到瞬间到账,还可以接到实时的推送通知。这就需要我们能够实时处理数据流。
- 另外,信用卡欺诈的检测也需要及时的监控和报警。一些金融交易市场,对异常交易行为的及时检测可以更好地进行风险控制;还可以对异常登录进行检测,从而发现钓鱼式攻击,从而避免巨大的损失。
- 电商和市场营销。
1.3 流式数据处理的发展和演变
1.3.1 流处理和批处理
- 数据处理有不同的方式。
- 对于具体应用来说,有些场景数据是一个一个来的,是一组有序的数据序列,我们把它叫作“数据流”;而有些场景的数据,本身就是一批同时到来,是一个有限的数据集,这就是批量数据(有时也直接叫数据集)。
- 容易想到,处理数据流,当然应该“来一个就处理一个”,这种数据处理模式就叫作流处理;因为这种处理是即时的,所以也叫实时处理。与之对应,处理批量数据自然就应该一批读入、一起计算,这种方式就叫作批处理,也叫作离线处理。
1.3.2 传统事务处理
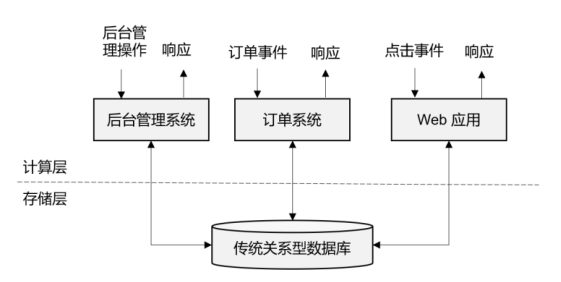
IT互联网公司往往会用不同的应用程序来处理各种业务。比如内部使用的企业资源规划(ERP)系统、客户关系管理(CRM)系统,还有面向客户的Web应用程序。这些系统一般都会进行分层设计:“计算层”就是应用程序本身,用于数据计算和处理;而“存储层”往往是传统的关系型数据库,用于数据存储,如图所示。
![]()
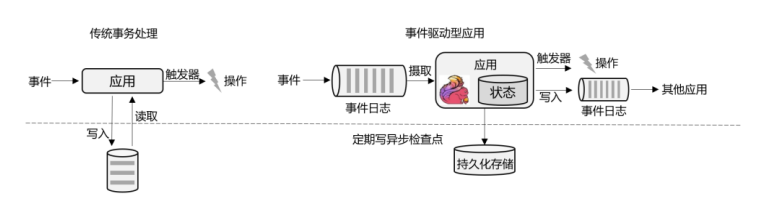
这就是传统的“事务处理”架构。系统所处理的连续不断的事件,其实就是一个数据流。而对于每一个事件,系统都在收到之后进行相应的处理,这也是符合流处理的原则的。所以可以说,传统的事务处理,就是最基本的流处理架构。
对于各种事件请求,事务处理的方式能够保证实时响应,好处是一目了然的。但是我们知 道,这样的架构对表和数据库的设计要求很高;当数据规模越来越庞大、系统越来越复杂时,可能需要对表进行重构,而且一次联表查询也会花费大量的时间,甚至不能及时得到返回结果。于是,作为程序员就只好将更多的精力放在表的设计和重构,以及SQL的调优上,而无法专注于业务逻辑的实现了——我们都知道,这种工作费力费时,却没法直接体现在产品上给老板看,简直就是噩梦。
1.3.3 有状态的流处理
不难想到,如果我们对于事件流的处理非常简单,例如收到一条请求就返回一个“收到”, 那就可以省去数据库的查询和更新了。但是这样的处理是没什么实际意义的。在现实的应用中,往往需要还其他一些额外数据。我们可以把需要的额外数据保存成一个“状态”,然后针对这条数据进行处理,并且更新状态。在传统架构中,这个状态就是保存在数据库里的。这就是所谓的“有状态的流处理”。
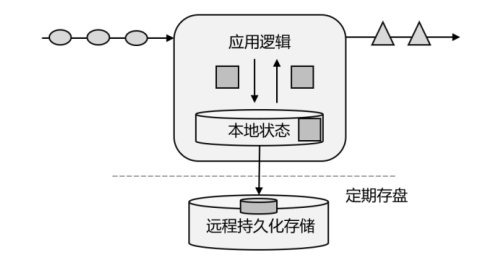
为了加快访问速度,我们可以直接将状态保存在本地内存,如图所示。当应用收到一个新事件时,它可以从状态中读取数据,也可以更新状态。而当状态是从内存中读写的时候,这就和访问本地变量没什么区别了,实时性可以得到极大的提升。另外,数据规模增大时,我们也不需要做重构,只需要构建分布式集群,各自在本地计算就可以了,可扩展性也变得更好。
因为采用的是一个分布式系统,所以还需要保护本地状态,防止在故障时数据丢失。我们 可以定期地将应用状态的一致性检查点(checkpoint)存盘,写入远程的持久化存储,遇到故障时再去读取进行恢复,这样就保证了更好的容错性。
![]()
有状态的流处理是一种通用而且灵活的设计架构,可用于许多不同的场景。具体来说,有以下几种典型应用。
事件驱动型(Event-Driven)应用。
事件驱动型应用是一类具有状态的应用,它从一个或多个事件流提取数据,并根据到来的事件触发计算、状态更新或其他外部动作。比较典型的就是以Kafka为代表的消息队列几乎都是事件驱动型应用。
这其实跟传统事务处理本质上是一样的,区别在于基于有状态流处理的事件驱动应用,不再需要查询远程数据库,而是在本地访问它们的数据,如图所示,这样在吞吐量和延迟方面就可以有更好的性能。
![]()
另外远程持久性存储的检查点保证了应用可以从故障中恢复。检查点可以异步和增量地完 成,因此对正常计算的影响非常小。
数据分析(Data Analysis)型应用。
所谓的数据分析,就是从原始数据中提取信息和发掘规律。传统上,数据分析一般是先将数据复制到数据仓库(Data Warehouse),然后进行批量查询。如果数据有了更新,必须将最新数据添加到要分析的数据集中,然后重新运行查询或应用程序。
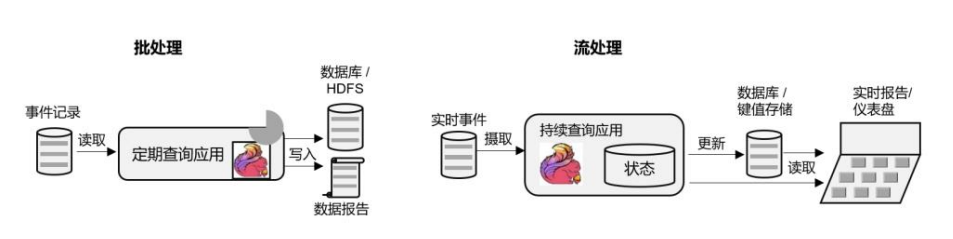
如今,Apache Hadoop生态系统的组件,已经是许多企业大数据架构中不可或缺的组成部分。现在的做法一般是将大量数据(如日志文件)写入Hadoop的分布式文件系统(HDFS)、S3或HBase等批量存储数据库,以较低的成本进行大容量存储。然后可以通过SQL-on-Hadoop类的引擎查询和处理数据,比如大家熟悉的Hive。这种处理方式,是典型的批处理,特点是可以处理海量数据,但实时性较差,所以也叫离线分析。
如果我们有了一个复杂的流处理引擎,数据分析其实也可以实时执行。流式查询或应用程序不是读取有限的数据集,而是接收实时事件流,不断生成和更新结果。结果要么写入外部数据库,要么作为内部状态进行维护。
Apache Flink同时支持流式与批处理的数据分析应用,如图所示。
![]()
与批处理分析相比,流处理分析最大的优势就是低延迟,真正实现了实时。另外,流处理不需要去单独考虑新数据的导入和处理,实时更新本来就是流处理的基本模式。当前企业对流式数据处理的一个热点应用就是实时数仓,很多公司正是基于Flink来实现的。
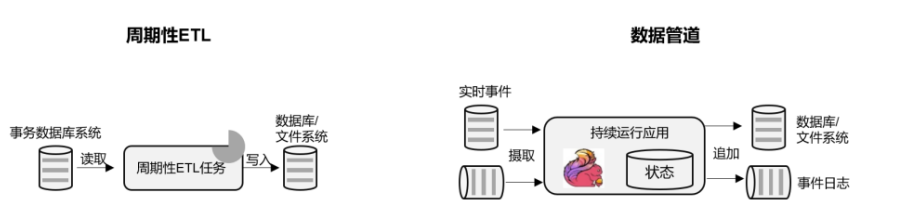
数据管道(Data Pipeline)型应用。
ETL也就是数据的提取、转换、加载,是在存储系统之间转换和移动数据的常用方法。在数据分析的应用中,通常会定期触发ETL任务,将数据从事务数据库系统复制到分析数据库或数据仓库。
所谓数据管道的作用与ETL类似。它们可以转换和扩展数据,也可以在存储系统之间移动数据。不过如果我们用流处理架构来搭建数据管道,这些工作就可以连续运行,而不需要再去周期性触发了。比如,数据管道可以用来监控文件系统目录中的新文件,将数据写入事件日志。连续数据管道的明显优势是减少了将数据移动到目的地的延迟,而且更加通用,可以用于更多的场景。如图所示,展示了ETL与数据管道之间的区别。
![]()
有状态的流处理架构上其实并不复杂,很多用户基于这种思想开发出了自己的流处理系统,这就是第一代流处理器。Apache Storm就是其中的代表。Storm可以说是开源流处理的先锋,最早是由Nathan Marz和创业公司BackType的一个团队开发的,后来才成为Apache软件基金会下属的项目。Storm提供了低延迟的流处理,但是它也为实时性付出了代价:很难实现高吞吐,而且无法保证结果的正确性。用更专业的话说,它并不能保证“精确一次” (exactly-once);即便是它能够保证的一致性级别,开销也相当大。
1.3.4 Lambda架构
对于有状态的流处理,当数据越来越多时,我们必须用分布式的集群架构来获取更大的吞吐量。但是分布式架构会带来另一个问题:怎样保证数据处理的顺序是正确的呢?
对于批处理来说,这并不是一个问题。因为所有数据都已收集完毕,我们可以根据需要选择、排列数据,得到想要的结果。可如果我们采用“来一个处理一个”的流处理,就可能出现 “乱序”的现象:本来先发生的事件,因为分布处理的原因滞后了。怎么解决这个问题呢?
以Storm为代表的第一代分布式开源流处理器,主要专注于具有毫秒延迟的事件处理,特点就是一个字“快”;而对于准确性和结果的一致性,是不提供内置支持的,因为结果有可能取决于到达事件的时间和顺序。另外,第一代流处理器通过检查点来保证容错性,但是故障恢复的时候,即使事件不会丢失,也有可能被重复处理——所以无法保证 exactly-once。
与批处理器相比,可以说第一代流处理器牺牲了结果的准确性,用来换取更低的延迟。而批处理器恰好反过来,牺牲了实时性,换取了结果的准确。
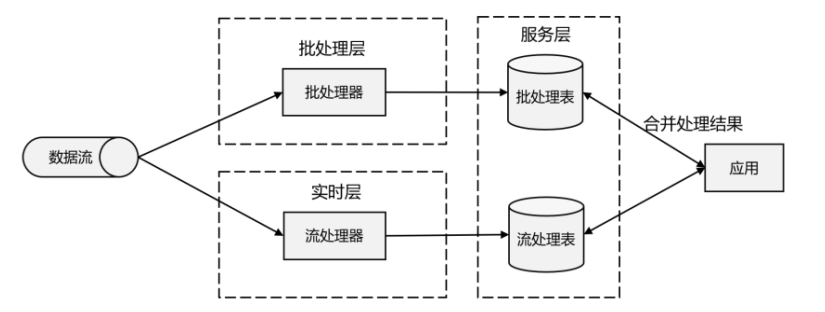
我们自然想到,如果可以让二者做个结合,不就可以同时提供快速和准确的结果了吗?正是基于这样的思想,Lambda架构被设计出来,如图所示。我们可以认为这是第二代流处理架构,但事实上,它只是第一代流处理器和批处理器的简单合并。
![]()
Lambda 架构主体是传统批处理架构的增强。它的“批处理层”(Batch Layer)就是由传统的批处理器和存储组成,而“实时层”(Speed Layer)则由低延迟的流处理器实现。数据到达之后,两层处理双管齐下,一方面由流处理器进行实时处理,另一方面写入批处理存储空间, 等待批处理器批量计算。流处理器快速计算出一个近似结果,并将它们写入“流处理表”中。 而批处理器会定期处理存储中的数据,将准确的结果写入批处理表,并从快速表中删除不准确 的结果。最终,应用程序会合并快速表和批处理表中的结果,并展示出来。
Lambda架构现在已经不再是最先进的,但仍在许多地方使用。它的优点非常明显,就是兼具了批处理器和第一代流处理器的特点,同时保证了低延迟和结果的准确性。而它的缺点同样非常明显。首先,Lambda架构本身就很难建立和维护;而且,它需要我们对一个应用程序, 做出两套语义上等效的逻辑实现,因为批处理和流处理是两套完全独立的系统,它们的API也完全不同。为了实现一个应用,付出了双倍的工作量,这对程序员显然不够友好。
1.3.5 新一代流处理器
- 第三代流处理器代表当然就是Flink。第三代流处理器通过巧妙的设计,完美解决了乱序数据对结果正确性的影响。这一代系统还做到了精确一次(exactly-once)的一致性保障,是第一个具有一致性和准确结果的开源流 处理器。另外,先前的流处理器仅能在高吞吐和低延迟中二选一,而新一代系统能够同时提供这两个特性。所以可以说,这一代流处理器仅凭一套系统就完成了Lambda架构两套系统的工 作,它的出现使得Lambda架构黯然失色。
- 除了低延迟、容错和结果准确性之外,新一代流处理器还在不断添加新的功能,例如高可用的设置,以及与资源管理器(如 YARN 或 Kubernetes)的紧密集成等等。
1.4 Flink的特性总结
- Flink是第三代分布式流处理器,它的功能丰富而强大。
1.4.1 Flink的核心特性
- Flink区别与传统数据处理框架的特性如下。
- 高吞吐和低延迟。每秒处理数百万个事件,毫秒级延迟。
- 结果的准确性。Flink提供了事件时间(event-time)和处理时间(processing-time) 语义。对于乱序事件流,事件时间语义仍然能提供一致且准确的结果。
- 精确一次(exactly-once)的状态一致性保证。
- 可以连接到最常用的存储系统,如Apache Kafka、Apache Cassandra、Elasticsearch、 JDBC、Kinesis 和(分布式)文件系统,如HDFS和S3。
- 高可用。本身高可用的设置,加上与K8s,YARN和Mesos的紧密集成,再加上从故障中快速恢复和动态扩展任务的能力,Flink能做到以极少的停机时间7×24全天候运行。
- 能够更新应用程序代码并将作业(jobs)迁移到不同的Flink集群,而不会丢失应用程序的状态。
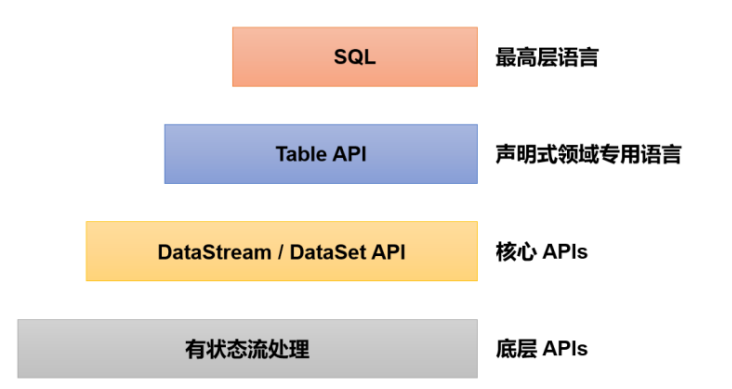
1.4.2 分层API
除了上述这些特性之外,Flink还是一个非常易于开发的框架,因为它拥有易于使用的分层API,整体API分层如图所示。
![]()
- 最底层级的抽象仅仅提供了有状态流,它将处理函数(Process Function)嵌入到了DataStream API 中。底层处理函数(Process Function)与DataStream API相集成,可以对某些操作进行抽象,它允许用户可以使用自定义状态处理来自一个或多个数据流的事件,且状态具有一致性和容错保证。除此之外,用户可以注册事件时间并处理时间回调,从而使程序可以处理复杂的计算。
- 实际上,大多数应用并不需要上述的底层抽象,而是直接针对核心API(Core APIs)进行编程,比如DataStream API(用于处理有界或无界流数据)以及DataSet API(用于处理有界数据集)。这些API为数据处理提供了通用的构建模块,比如由用户定义的多种形式的转换 (transformations)、连接(joins)、聚合(aggregations)、窗口(windows)操作等。DataSet API为有界数据集提供了额外的支持,例如循环与迭代。这些API处理的数据类型以类(classes)的形式由各自的编程语言所表示。
- Table API是以表为中心的声明式编程,其中表在表达流数据时会动态变化。Table API遵循关系模型:表有二维数据结构(schema)(类似于关系数据库中的表),同时API提供可比较的操作,例如select、join、group-by、aggregate等。
- 尽管Table API可以通过多种类型的用户自定义函数(UDF)进行扩展,仍不如核心API更具表达能力,但是使用起来代码量更少,更加简洁。除此之外,Table API程序在执行之前会使用内置优化器进行优化。 我们可以在表与DataStream/DataSet之间无缝切换,以允许程序将Table API与DataStream以及DataSet混合使用。
- Flink提供的最高层级的抽象是SQL。这一层抽象在语法与表达能力上与Table API类似,但是是以SQL查询表达式的形式表现程序。SQL抽象与Table API交互密切,同时SQL查询可以直接在Table API定义的表上执行。
- 目前Flink SQL和Table API还在开发完善的过程中,很多大厂都会二次开发符合自己需要的工具包。而DataSet作为批处理API实际应用较少,2020年12月8日发布的新版本1.12.0已经完全实现了真正的流批一体,DataSet API已处于软性弃用(soft deprecated)的状态。用Data Stream API写好的一套代码即可以处理流数据,也可以处理批数据,只需要设置不同的执行模式。这与之前版本处理有界流的方式是不一样的,Flink已专门对批处理数据做了优化处理。
2、Flink快速上手
2.1 创建项目
创建一个Maven工程,在项目的pom文件中,增加<properties>标签设置属性,然后增加<denpendencies>标签引入需要的依赖。我们需要添加的依赖最重要的就是Flink的相关组件,包括flink-java、flink-streaming-java,以及flink-clients(客户端,也可以省略)。另外,为了方便查看运行日志,我们引入slf4j和log4j进行日志管理。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41<properties>
<flink.version>1.13.0</flink.version>
<java.version>1.8</java.version>
<scala.binary.version>2.12</scala.binary.version>
<slf4j.version>1.7.30</slf4j.version>
</properties>
<dependencies>
<!-- 引入 Flink 相关依赖-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- 引入日志管理相关依赖-->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-to-slf4j</artifactId>
<version>2.14.0</version>
</dependency>
</dependencies>- 在属性中,我们定义了<scala.binary.version>,这指代的是所依赖的Scala版本。这有一点奇怪:Flink底层是Java,而且我们也只用Java API,为什么还会依赖Scala 呢?这是因为Flink的架构中使用了Akka来实现底层的分布式通信,而Akka是用Scala开发的。
配置日志管理。在目录src/main/resources下添加文件:log4j.properties,内容配置如下:
1
2
3
4log4j.rootLogger=error, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%-4r [%t] %-5p %c %x - %m%n
2.2 编写代码
- 接下来用一个最简单的示例来说明Flink代码怎样编写:统计一段文字中,每个单词出现的频次。这就是传说中的WordCount程序——它是大数据领域非常经典的入门案例。
2.2.1 批处理
对于批处理而言,输入的应该是收集好的数据集。这里我们可以将要统计的文字,写入一个文本文档,然后读取这个文件处理数据就可以了。
在工程根目录下新建一个input文件夹,并在下面创建文本文件words.txt,在words.txt中输入一些文字,例如:
1
2
3hello world
hello flink
hello java新建Java类BatchWordCount,在静态main方法中编写测试代码。我们进行单词频次统计的基本思路是:先逐行读入文件数据,然后将每一行文字拆分成单词;接着按照单词分组,统计每组数据的个数,就是对应单词的频次。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22public class BatchWordCount {
public static void main(String[] args) throws Exception {
// 1. 创建执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 2. 从文件读取数据 按行读取(存储的元素就是每行的文本)
DataSource<String> lineDS = env.readTextFile("input/words.txt");
// 3. 转换数据格式
FlatMapOperator<String, Tuple2<String, Long>> wordAndOne = lineDS
.flatMap((String line, Collector<Tuple2<String, Long>> out) -> {
String[] words = line.split(" ");
for (String word : words) {
out.collect(Tuple2.of(word, 1L));
}
}).returns(Types.TUPLE(Types.STRING, Types.LONG)); //当Lambda表达式使用Java泛型的时候, 由于泛型擦除的存在, 需要显示的声明类型信息
// 4. 按照 word 进行分组
UnsortedGrouping<Tuple2<String, Long>> wordAndOneUG = wordAndOne.groupBy(0);
// 5. 分组内聚合统计
AggregateOperator<Tuple2<String, Long>> sum = wordAndOneUG.sum(1);
// 6. 打印结果
sum.print();
}
}Flink在执行应用程序前应该获取执行环境对象,也就是运行时上下文环境。
1
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
Flink同时提供了Java和Scala两种语言的API,有些类在两套API中名称是一样的。所以在引入包时,如果有Java和Scala两种选择,要注意选用Java的包。
直接调用执行环境的readTextFile方法,可以从文件中读取数据。
我们的目标是将每个单词对应的个数统计出来,所以调用flatmap方法可以对一行文字进行分词转换。将文件中每一行文字拆分成单词后,要转换成(word,count)形式的二元组,初始count都为1。returns方法指定的返回数据类型Tuple2,就是Flink自带的二元组数据类型。
在分组时调用了groupBy方法,它不能使用分组选择器,只能采用位置索引或属性名称进行分组。
1
2
3
4// 使用索引定位
dataStream.groupBy(0)
// 使用类属性名称
dataStream.groupBy("id")在分组之后调用sum方法进行聚合,同样只能指定聚合字段的位置索引或属性名称。
运行程序,控制台会打印出结果:

可以看到,我们将文档中的所有单词的频次,全部统计出来,以二元组的形式在控制台打印输出了。
需要注意的是,这种代码的实现方式,是基于DataSet API的,也就是我们对数据的处理转换,是看作数据集来进行操作的。事实上Flink本身是流批统一的处理架构,批量的数据集本质上也是流,没有必要用两套不同的API来实现。所以从Flink 1.12开始,官方推荐的做法是直接使用DataStream API,在提交任务时通过将执行模式设为BATCH来进行批处理:
1
$ bin/flink run -Dexecution.runtime-mode=BATCH BatchWordCount.jar
- 这样,DataSet API就已经处于“软弃用”(soft deprecated)的状态,在实际应用中我们只要维护一套DataStream API就可以了。这里只是为了方便大家理解,我们依然用DataSet API做了批处理的实现。

2.2.2 流处理
我们已经知道,用DataSet API可以很容易地实现批处理;与之对应,流处理当然可以用DataStream API来实现。对于Flink而言,流才是整个处理逻辑的底层核心,所以流批统一之后的DataStream API更加强大,可以直接处理批处理和流处理的所有场景。下面我们就针对不同类型的输入数据源,用具体的代码来实现流处理。
读取文件。我们同样试图读取文档words.txt中的数据,并统计每个单词出现的频次。这是一个“有界流”的处理,整体思路与之前的批处理非常类似,代码模式也基本一致。新建Java类BoundedStreamWordCount,在静态main方法中编写测试代码。具体代码实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26public class BoundedStreamWordCount {
public static void main(String[] args) throws Exception {
// 1. 创建流式执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 读取文件
DataStreamSource<String> lineDSS = env.readTextFile("input/words.txt");
// 3. 转换数据格式
SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOne = lineDSS
.flatMap((String line, Collector<String> words) -> {
Arrays.stream(line.split(" ")).forEach(words::collect);
})
.returns(Types.STRING)
.map(word -> Tuple2.of(word, 1L))
.returns(Types.TUPLE(Types.STRING, Types.LONG));
// 4. 分组
KeyedStream<Tuple2<String, Long>, String> wordAndOneKS = wordAndOne
.keyBy(t -> t.f0);
// 5. 求和
SingleOutputStreamOperator<Tuple2<String, Long>> result = wordAndOneKS
.sum(1);
// 6. 打印
result.print();
// 7. 执行
env.execute();
}
}主要观察与批处理程序BatchWordCount的不同:
- 创建执行环境的不同,流处理程序使用的是StreamExecutionEnvironment。
- 每一步处理转换之后,得到的数据对象类型不同。
- 分组操作调用的是keyBy方法,可以传入一个匿名函数作为键选择器(KeySelector),指定当前分组的key是什么。
- 代码末尾需要调用env的execute方法,开始执行任务。
运行程序,控制台输出结果如下:

我们可以看到,这与批处理的结果是完全不同的。批处理针对每个单词,只会输出一个最终的统计个数;而在流处理的打印结果中,“hello”这个单词每出现一次,都会有一个频次统计数据输出。这就是流处理的特点,数据逐个处理,每来一条数据就会处理输出一次。我们通过打印结果,可以清晰地看到单词“hello”数量增长的过程。
看到这里大家可能又会有新的疑惑:我们读取文件,第一行应该是“hello flink”,怎么这 里输出的第一个单词是“world”呢?每个输出的结果二元组,前面都有一个数字,这又是什么呢?
- 我们可以先做个简单的解释。Flink是一个分布式处理引擎,所以我们的程序应该也是分布式运行的。在开发环境里,会通过多线程来模拟 Flink 集群运行。所以这里结果前的数字, 其实就指示了本地执行的不同线程,对应着Flink运行时不同的并行资源。这样第一个乱序的问题也就解决了:既然是并行执行,不同线程的输出结果,自然也就无法保持输入的顺序了。
- 另外需要说明,这里显示的编号为1~8,是由于运行电脑的CPU是8核,所以默认模拟的并行线程有8个。这段代码不同的运行环境,得到的结果会是不同的。关于Flink程序并行执行的数量,可以通过设定“并行度”(Parallelism)来进行配置。
读取文本流。在实际的生产环境中,真正的数据流其实是无界的,有开始却没有结束,这就要求我们需要保持一个监听事件的状态,持续地处理捕获的数据。为了模拟这种场景,我们就不再通过读取文件来获取数据了,而是监听数据发送端主机的 指定端口,统计发送来的文本数据中出现过的单词的个数。具体实现上,我们只要对BoundedStreamWordCount代码中读取数据的步骤稍做修改,就可以实现对真正无界流的处理。
新建一个Java类StreamWordCount,将BoundedStreamWordCount代码中读取文件数据的readTextFile方法,替换成读取socket文本流的方法socketTextStream。具体代码实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28public class StreamWordCount {
public static void main(String[] args) throws Exception {
// 1. 创建流式执行环境
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 读取文本流
DataStreamSource<String> lineDSS = env.socketTextStream("localhost", 7777);
// 3. 转换数据格式
SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOne = lineDSS
.flatMap((String line, Collector<String> words) -> {
Arrays.stream(line.split(" ")).forEach(words::collect);
})
.returns(Types.STRING)
.map(word -> Tuple2.of(word, 1L))
.returns(Types.TUPLE(Types.STRING, Types.LONG));
// 4. 分组
KeyedStream<Tuple2<String, Long>, String> wordAndOneKS = wordAndOne
.keyBy(t -> t.f0);
// 5. 求和
SingleOutputStreamOperator<Tuple2<String, Long>> result = wordAndOneKS
.sum(1);
// 6. 打印
result.print();
// 7. 执行
env.execute();
}
}- socket文本流的读取需要配置两个参数:发送端主机名和端口号。这里代码中指定了主机“localhost”的7777端口作为发送数据的socket端口,读者可以根据测试环境自行配置。
- 在实际项目应用中,主机名和端口号这类信息往往可以通过配置文件,或者传入程序运行参数的方式来指定。
- socket文本流数据的发送,可以通过Linux系统自带的netcat工具进行模拟。
在本地Linux环境上,执行下列命令,发送数据进行测试:
1
nc -lk 7777
启动StreamWordCount程序,我们会发现程序启动之后没有任何输出、也不会退出。这是正常的——因为Flink的流处理是事件驱动的,当前程序会一直处于监听状态,只有接收到数据才会执行任务、输出统计结果。
从本地发送数据:

可以看到控制台输出结果如下:

我们会发现,输出的结果与之前读取文件的流处理非常相似。而且可以非常明显地看到, 每输入一条数据,就有一次对应的输出。具体对应关系是:输入“hello flink”,就会输出两条统计结果(flink,1)和(hello,1);之后再输入“hello world”,同样会将hello和world的个数统计输出,hello的个数会对应增长为2。



3、Flink部署
3.1 快速启动一个Flink集群
我们在本地执行代码,其实是先模拟启动一个Flink集群,然后将作业提交到集群上,创建好要执行的任务等待数据输入。
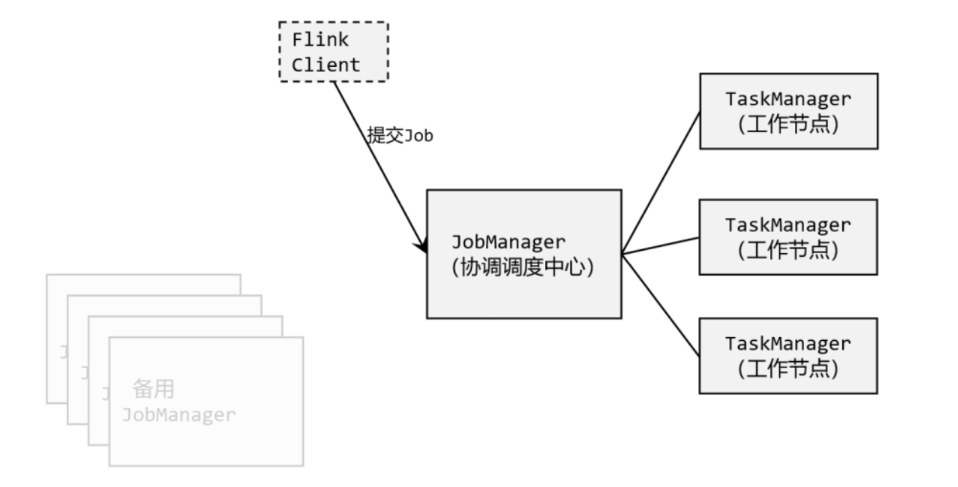
这里需要提到Flink中的几个关键组件:客户端(Client)、作业管理器(JobManager)和 任务管理器(TaskManager)。我们的代码,实际上是由客户端获取并做转换,之后提交给JobManger的。所以JobManager就是Flink集群里的“管事人”,对作业进行中央调度管理;而它获取到要执行的作业后,会进一步处理转换,然后分发任务给众多的TaskManager。这里的TaskManager,就是真正“干活的人”,数据的处理操作都是它们来做的,如图所示。
![]()
在实际项目应用中,我们当然不能使用开发环境的模拟集群,而是需要将 Flink 部署在生 产集群环境中,然后在将作业提交到集群上运行。Flink是一个非常灵活的处理框架,它支持多种不同的部署场景,还可以和不同的资源管理平台方便地集成。
这里只演示本地启动。这是最简单的启动方式,其实是不搭建集群,直接本地启动。本地部署非常简单,直接解压安装包就可以使用,不用进行任何配置;一般用来做一些简单的测试。
下载安装包。进入Flink官网,下载1.13.0版本安装包flink-1.13.0-bin-scala_2.12.tgz,注意此处选用对应scala版本为scala 2.12的安装包(
https://archive.apache.org/dist/flink/flink-1.13.0/flink-1.13.0-bin-scala_2.12.tgz)。解压。在hadoop102节点服务器上创建安装目录/opt/module,将flink安装包放在该目录下,并执行解压命令,解压至当前目录。
1
2
3
4
5
6$ tar -zxvf flink-1.13.0-bin-scala_2.12.tgz -C /opt/module/
flink-1.13.0/
flink-1.13.0/log/
flink-1.13.0/LICENSE
flink-1.13.0/lib/
......启动。进入解压后的目录,执行启动命令,并查看进程。
1
2
3
4
5
6
7
8
9$ cd flink-1.13.0/
$ bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host hadoop102.
Starting taskexecutor daemon on host hadoop102.
$ jps
10369 StandaloneSessionClusterEntrypoint
10680 TaskManagerRunner
10717 Jps访问 Web UI。启动成功后,访问
http://ip:8081,可以对flink集群和任务进行监控管理,如图所示。![]()
关闭集群。如果想要让Flink集群停止运行,可以执行以下命令:
1
2
3$ bin/stop-cluster.sh
Stopping taskexecutor daemon (pid: 10680) on host hadoop102.
Stopping standalonesession daemon (pid: 10369) on host hadoop102.在Web UI上提交作业。之前我们已经编写了词频统计的批处理和流处理的示例程序,并在开发环境的模拟集群上做了运行测试。现在既然已经有了真正的集群环境,那接下来我们就要把作业提交上去执行了。
程序打包。为方便自定义结构和定制依赖,我们可以引入插件maven-assembly-plugin进行打包。在FlinkTutorial项目的pom.xml文件中添加打包插件的配置,具体如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
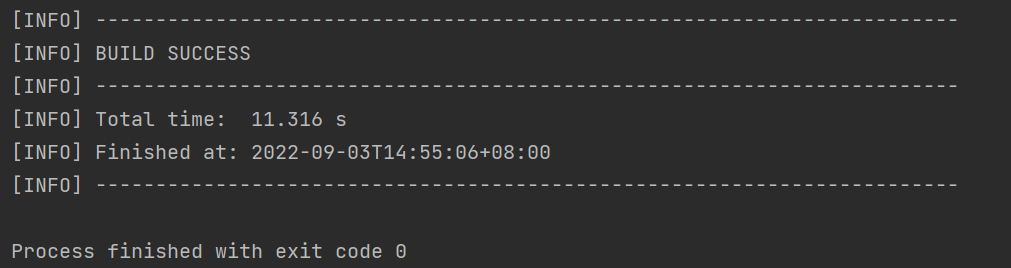
</build>插件配置完毕后,可以使用IDEA的Maven工具执行package命令,出现如下提示即表示打包成功。
![]()
打包完成后,在target目 录下即可找到所需JAR包,JAR包会有两个,FlinkTutorial-1.0-SNAPSHOT.jar和FlinkTutorial-1.0-SNAPSHOT-jar-with-dependencies.jar,因为集群中已经具备任务运行所需的所有依赖,所以建议使用FlinkTutorial-1.0-SNAPSHOT.jar。
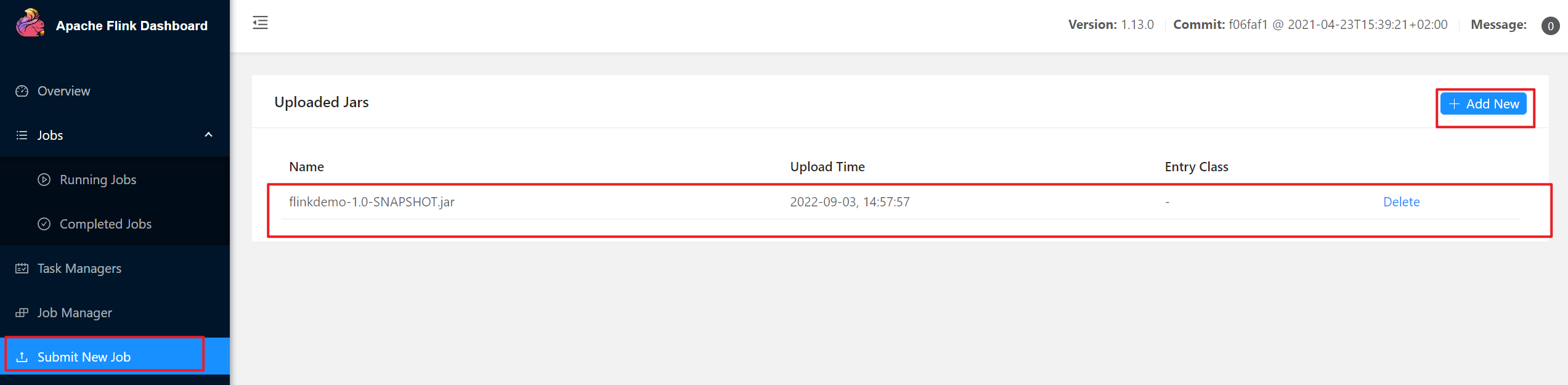
在Web UI上提交作业。任务打包完成后,我们打开Flink的WEB UI页面,在右侧导航栏点击“Submit New Job”,然后点击按钮“+ Add New”,选择要上传运行的JAR包进行上传,如图所示。
![]()
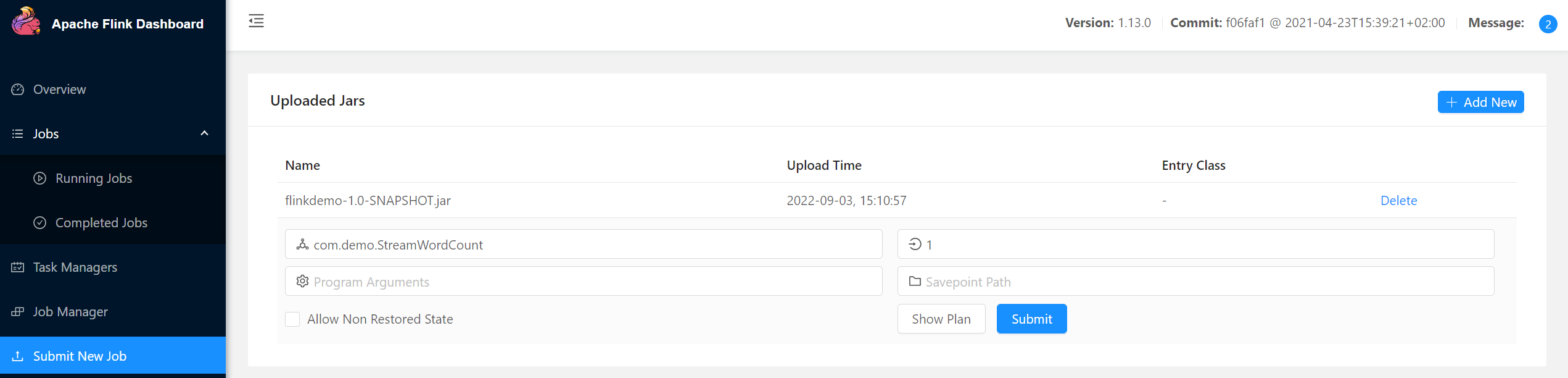
点击该JAR包,出现任务配置页面,进行相应配置。主要配置程序入口主类的全类名,任务运行的并行度,任务运行所需的配置参数和保存点路径等,如图所示,配置完成后,即可点击按钮“Submit”,将任务提交到集群运行。
![]()
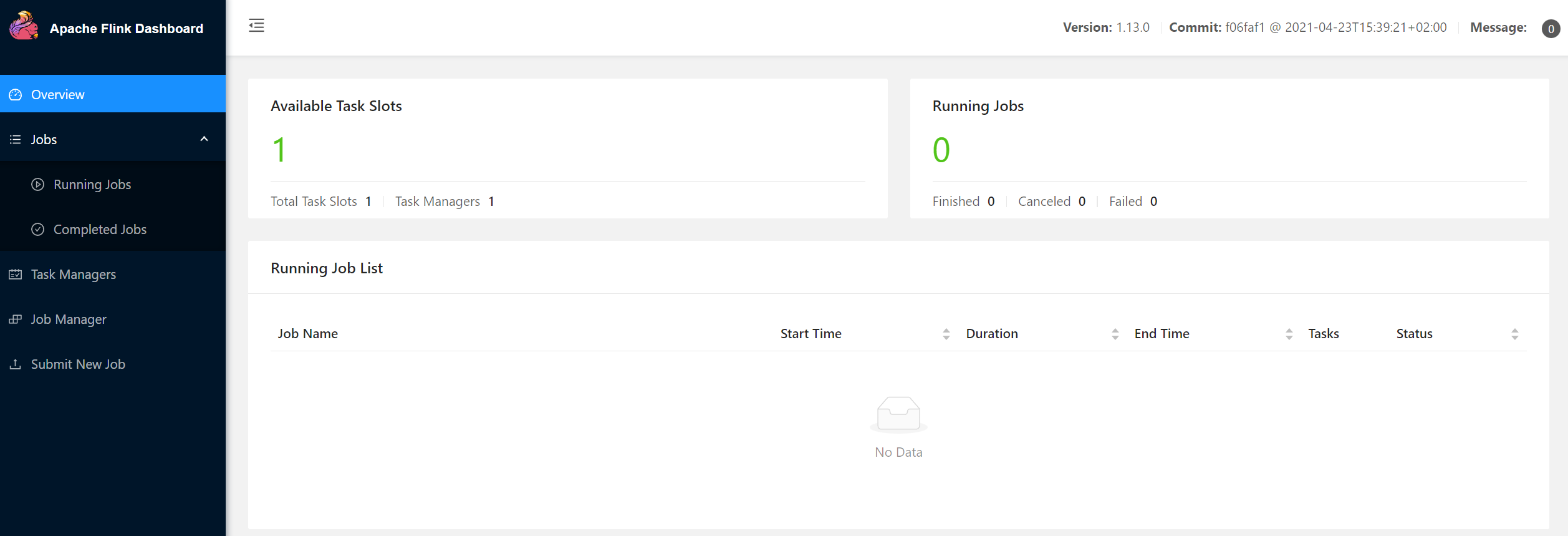
输入文本流每输入一条信息都可以在task manager中看到打印信息。
![]()
![]()
命令行提交作业。除了通过WEB UI界面提交任务之外,也可以直接通过命令行来提交任务。这里为方便 起见,我们可以先把jar包直接上传到目录flink-1.13.0下。接着在命令行使用flink run命令提交作业。这里的参数–m指定了提交到的JobManager,-c指定了入口类。
1
2[root@VM-12-5-centos flink-1.13.0]# bin/flink run -m localhost:8081 -c com.demo.StreamWordCount ./flinkdemo-1.0-SNAPSHOT.jar
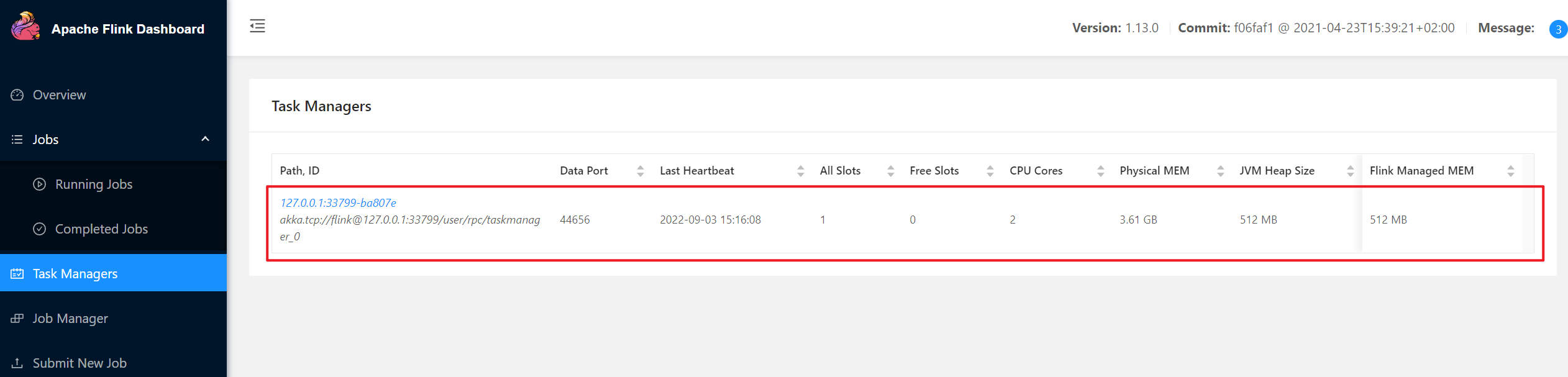
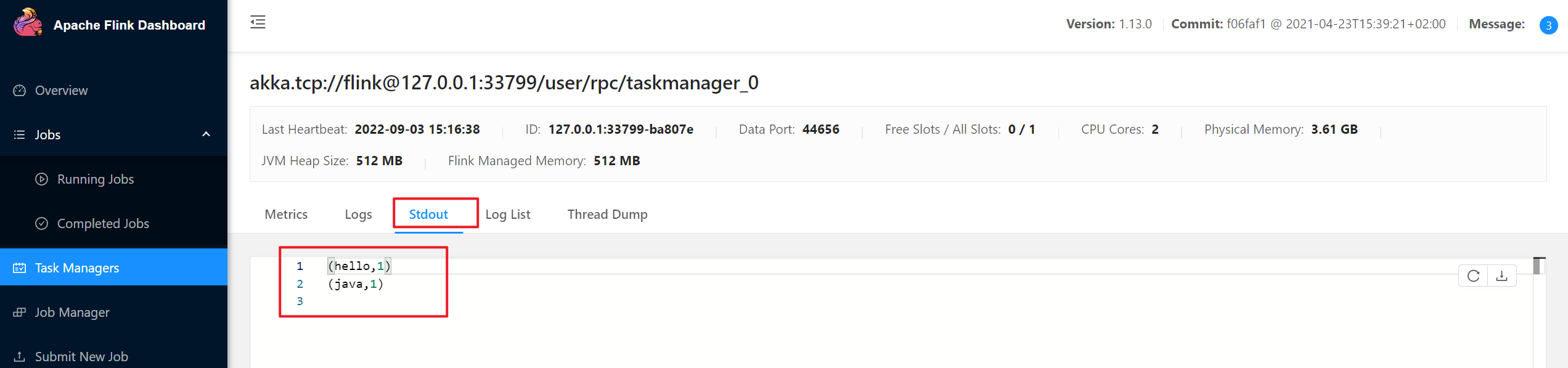
Job has been submitted with JobID c8581e3ce34ce398cd79e60834dd64a1用netcat输入数据,除了可以在TaskManager的标准输出(Stdout)看到对应的统计结果之外,在log日志中,也可以查看执行结果,需要找到执行该数据任务的TaskManager节点查看日志。
1
2
3
4
5[root@VM-12-5-centos flink-1.13.0]# cat log/flink-root-taskexecutor-0-VM-12-5-centos.out
(hello,1)
(java,1)
(hello,1)
(flink,1)
3.2 部署模式
- 在一些应用场景中,对于集群资源分配和占用的方式,可能会有特定的需求。Flink为各种场景提供了不同的部署模式,主要有以下三种:
- 会话模式(Session Mode)。
- 单作业模式(Per-Job Mode)。
- 应用模式(Application Mode)。
- 它们的区别主要在于:集群的生命周期以及资源的分配方式;以及应用的main方法到底在哪里执行——客户端(Client)还是JobManager。接下来我们就做一个展开说明。
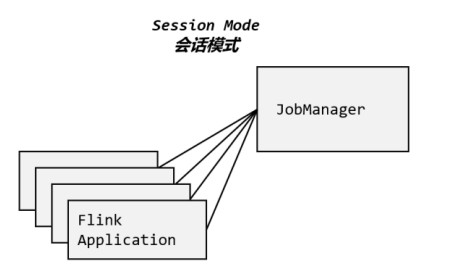
3.2.1 会话模式(Session Mode)
会话模式其实最符合常规思维。我们需要先启动一个集群,保持一个会话,在这个会话中通过客户端提交作业,如图所示。集群启动时所有资源就都已经确定,所以所有提交的作业会竞争集群中的资源。
![]()
这样的好处很明显,我们只需要一个集群,就像一个大箱子,所有的作业提交之后都塞进去;集群的生命周期是超越于作业之上的,铁打的营盘流水的兵,作业结束了就释放资源,集 群依然正常运行。当然缺点也是显而易见的:因为资源是共享的,所以资源不够了,提交新的 作业就会失败。另外,同一个TaskManager上可能运行了很多作业,如果其中一个发生故障导致TaskManager宕机,那么所有作业都会受到影响。
会话模式比较适合于单个规模小、执行时间短的大量作业。
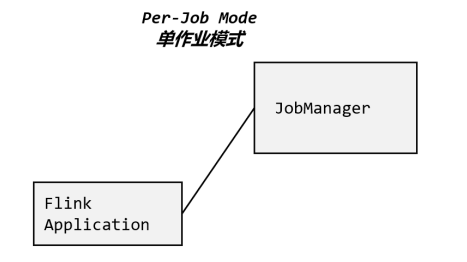
3.2.2 单作业模式(Per-Job Mode)
会话模式因为资源共享会导致很多问题,所以为了更好地隔离资源,我们可以考虑为每个提交的作业启动一个集群,这就是所谓的单作业(Per-Job)模式,如图所示。
![]()
单作业模式也很好理解,就是严格的一对一,集群只为这个作业而生。同样由客户端运行应用程序,然后启动集群,作业被提交给JobManager,进而分发给TaskManager执行。作业作业完成后,集群就会关闭,所有资源也会释放。这样一来,每个作业都有它自己的JobManager管理,占用独享的资源,即使发生故障,它的TaskManager宕机也不会影响其他作业。
这些特性使得单作业模式在生产环境运行更加稳定,所以是实际应用的首选模式。
需要注意的是,Flink本身无法直接这样运行,所以单作业模式一般需要借助一些资源管理框架来启动集群,比如YARN、Kubernetes。
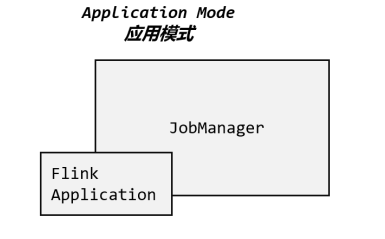
3.2.3 应用模式(Application Mode)
前面提到的两种模式下,应用代码都是在客户端上执行,然后由客户端提交给JobManager的。但是这种方式客户端需要占用大量网络带宽,去下载依赖和把二进制数据发送给JobManager;加上很多情况下我们提交作业用的是同一个客户端,就会加重客户端所在节点的资源消耗。
所以解决办法就是,我们不要客户端了,直接把应用提交到JobManger上运行。而这也就代表着,我们需要为每一个提交的应用单独启动一个JobManager,也就是创建一个集群。这个JobManager只为执行这一个应用而存在,执行结束之后JobManager也就关闭了,这就是所谓的应用模式,如图所示。
![]()
应用模式与单作业模式,都是提交作业之后才创建集群;单作业模式是通过客户端来提交的,客户端解析出的每一个作业对应一个集群;而应用模式下,是直接由JobManager执行应用程序的,并且即使应用包含了多个作业,也只创建一个集群。
3.2.4 总结
- 总结一下,在会话模式下,集群的生命周期独立于集群上运行的任何作业的生命周期,并且提交的所有作业共享资源。而单作业模式为每个提交的作业创建一个集群,带来了更好的资源隔离,这时集群的生命周期与作业的生命周期绑定。最后,应用模式为每个应用程序创建一个会话集群,在JobManager上直接调用应用程序的 main()方法。
- 我们所讲到的部署模式,相对是比较抽象的概念。实际应用时,一般需要和资源管理平台结合起来,选择特定的模式来分配资源、部署应用。接下来,我们就针对不同的资源提供者(Resource Provider)的场景,具体介绍Flink的部署方式。
3.3 独立模式(Standalone)
- 独立模式(Standalone)是部署Flink最基本也是最简单的方式:所需要的所有Flink组件, 都只是操作系统上运行的一个JVM进程。
- 独立模式是独立运行的,不依赖任何外部的资源管理平台;当然独立也是有代价的:如果资源不足,或者出现故障,没有自动扩展或重分配资源的保证,必须手动处理。所以独立模式一般只用在开发测试或作业非常少的场景下。
- 另外,我们也可以将独立模式的集群放在容器中运行。Flink提供了独立模式的容器化部署方式,可以在Docker或者Kubernetes上进行部署。
3.3.1 会话模式部署
- 可以发现,独立模式的特点是不依赖外部资源管理平台,而会话模式的特点是先启动集群、后提交作业。所以,我们在第3.1节用的就是独立模式(Standalone)的会话模式部署。
3.3.2 单作业模式部署
- 在3.2.2节中我们提到,Flink本身无法直接以单作业方式启动集群,一般需要借助一些资源管理平台。所以Flink的独立(Standalone)集群并不支持单作业模式部署。
3.3.3 应用模式部署
应用模式下不会提前创建集群,所以不能调用start-cluster.sh脚本。我们可以使用同样在bin目录下的standalone-job.sh来创建一个JobManager。
进入到Flink的安装路径下,将应用程序的jar包放到lib/目录下。
1
[root@VM-12-5-centos flink-1.13.0]# cp ./flinkdemo-1.0-SNAPSHOT.jar lib/
执行以下命令,启动JobManager。这里我们直接指定作业入口类,脚本会到lib目录扫描所有的jar包。
1
2[root@VM-12-5-centos flink-1.13.0]# ./bin/standalone-job.sh start --job-classname com.demo.StreamWordCount
Starting standalonejob daemon on host VM-12-5-centos.同样是使用bin目录下的脚本,启动TaskManager。
1
2
3[root@VM-12-5-centos flink-1.13.0]# ./bin/taskmanager.sh start
[INFO] 1 instance(s) of taskexecutor are already running on VM-12-5-centos.
Starting taskexecutor daemon on host VM-12-5-centos.如果希望停掉集群,同样可以使用脚本,命令如下。
1
2$ ./bin/standalone-job.sh stop
$ ./bin/taskmanager.sh stop
3.3.4 高可用(High Availability)
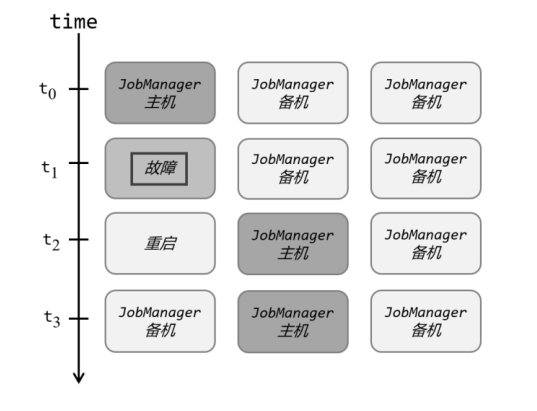
分布式除了提供高吞吐,另一大好处就是有更好的容错性。对于Flink而言,因为一般会有多个TaskManager,即使运行时出现故障,也不需要将全部节点重启,只要尝试重启故障节点就可以了。但是我们发现,针对一个作业而言,管理它的JobManager却只有一个,这同样有可能出现单点故障。为了实现更好的可用性,我们需要JobManager做一些主备冗余,这就 是所谓的高可用(High Availability,简称 HA)。
我们可以通过配置,让集群在任何时候都有一个主JobManager和多个备用JobManagers, 如图所示,这样主节点故障时就由备用节点来接管集群,接管后作业就可以继续正常运行。主备JobManager实例之间没有明显的区别,每个JobManager都可以充当主节点或者备节点。
![]()
3.4 YARN模式
- 独立(Standalone)模式由Flink自身提供资源,无需其他框架,这种方式降低了和其他第三方资源框架的耦合性,独立性非常强。但我们知道,Flink是大数据计算框架,不是资源调度框架,这并不是它的强项;所以还是应该让专业的框架做专业的事,和其他资源调度框架集成更靠谱。而在目前大数据生态中,国内应用最为广泛的资源管理平台就是YARN了。所 以接下来我们就将学习,在强大的YARN平台上Flink是如何集成部署的。
- 整体来说,YARN上部署的过程是:客户端把Flink应用提交给Yarn的ResourceManager,Yarn的ResourceManager会向Yarn的NodeManager申请容器。在这些容器上,Flink会部署JobManager和TaskManager的实例,从而启动集群。Flink会根据运行在JobManger上的作业所需要的Slot数量动态分配TaskManager资源。
3.5 K8S模式
- 容器化部署是如今业界流行的一项技术,基于Docker镜像运行能够让用户更加方便地对应用进行管理和运维。容器管理工具中最为流行的就是Kubernetes(k8s),而Flink也在最近的版本中支持了k8s部署模式。基本原理与YARN是类似的,具体配置可以参见官网说明,这里我们就不做过多讲解了。
4、Flink运行时架构
4.1 系统架构
- Flink可以配置为独立(Standalone)集群运行,也可以方便地跟一些集群资源管理工具集成使用,比如YARN、Kubernetes和Mesos。Flink也不会自己 去提供持久化的分布式存储,而是直接利用了已有的分布式文件系统(比如 HDFS)或者对象 存储(比如S3)。而对于高可用的配置,Flink是依靠Apache ZooKeeper来完成的。
4.1.1 整体构成
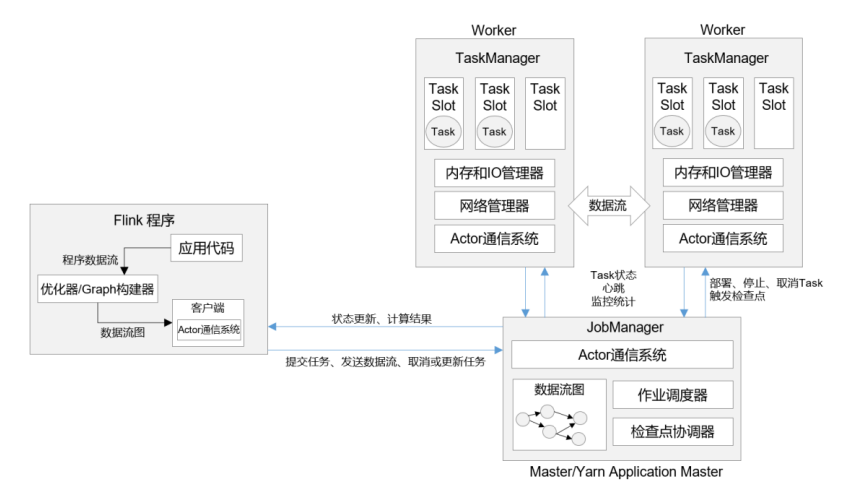
Flink的运行时架构中,最重要的就是两大组件:作业管理器(JobManger)和任务管理器(TaskManager)。对于一个提交执行的作业,JobManager是真正意义上的“管理者”(Master),负责管理调度,所以在不考虑高可用的情况下只能有一个;而TaskManager是“工作者”(Worker、Slave),负责执行任务处理数据,所以可以有一个或多个。Flink的作业提交和任务处理时的系统如图所示。
![]()
- 这里首先要说明一下“客户端”。其实客户端并不是处理系统的一部分,它只负责作业的提交。具体来说,就是调用程序的main方法,将代码转换成“数据流图”(Dataflow Graph), 并最终生成作业图(JobGraph),一并发送给JobManager。提交之后,任务的执行其实就跟客户端没有关系了;我们可以在客户端选择断开与JobManager的连接,也可以继续保持连接。之前我们在命令提交作业时,加上的-d 参数,就是表示分离模式(detached mode),也就是断开连接。
- 当然,客户端可以随时连接到JobManager,获取当前作业的状态和执行结果,也可以发送请求取消作业。我们在上一章中不论通过Web UI还是命令行执行“flink run”的相关操作,都是通过客户端实现的。
JobManager和TaskManagers可以以不同的方式启动,这其实就对应着不同的部署方式:
- 作为独立(Standalone)集群的进程,直接在机器上启动。
- 在容器中启动。
- 由资源管理平台调度启动,比如 YARN、K8S。
TaskManager启动之后,JobManager会与它建立连接,并将作业图(JobGraph)转换成可执行的“执行图”(ExecutionGraph)分发给可用的TaskManager,然后就由TaskManager具体执行任务。接下来,我们就具体介绍一下JobManger和TaskManager在整个过程中扮演的角色。
4.1.2 作业管理器(JobManager)
- JobManager是一个Flink集群中任务管理和调度的核心,是控制应用执行的主进程。也就是说,每个应用都应该被唯一的JobManager所控制执行。当然,在高可用(HA)的场景下,可能会出现多个JobManager;这时只有一个是正在运行的领导节点(leader),其他都是备用节点(standby)。JobManger又包含3个不同的组件,下面我们一一讲解。
- JobMaster:
- JobMaster是JobManager中最核心的组件,负责处理单独的作业(Job)。所以JobMaster和具体的Job是一一对应的,多个Job可以同时运行在一个Flink集群中,每个Job都有一个 自己的JobMaster。需要注意在早期版本的Flink中,没有JobMaster的概念;而JobManager的概念范围较小,实际指的就是现在所说的JobMaster。
- 在作业提交时,JobMaster会先接收到要执行的应用。这里所说“应用”一般是客户端提交来的,包括:Jar 包,数据流图(dataflow graph),和作业图(JobGraph)。
- JobMaster会把JobGraph转换成一个物理层面的数据流图,这个图被叫作“执行图”(ExecutionGraph),它包含了所有可以并发执行的任务。 JobMaster会向资源管理器 (ResourceManager)发出请求,申请执行任务必要的资源。一旦它获取到了足够的资源,就会将执行图分发到真正运行它们的TaskManager上。
- 而在运行过程中,JobMaster会负责所有需要中央协调的操作,比如说检查点(checkpoints) 的协调。
- 资源管理器(ResourceManager):
- ResourceManager主要负责资源的分配和管理,在Flink集群中只有一个。所谓“资源”, 主要是指TaskManager的任务槽(task slots)。任务槽就是Flink集群中的资源调配单元,包含了机器用来执行计算的一组CPU和内存资源。每一个任务(Task)都需要分配到一个slot上执行。
- 这里注意要把Flink内置的ResourceManager和其他资源管理平台(比如YARN)的ResourceManager区分开。
- Flink的ResourceManager,针对不同的环境和资源管理平台(比如Standalone部署,或者 YARN),有不同的具体实现。在Standalone部署时,因为TaskManager是单独启动的(没有Per-Job 模式),所以ResourceManager只能分发可用TaskManager的任务槽,不能单独启动新 TaskManager。
- 而在有资源管理平台时,就不受此限制。当新的作业申请资源时,ResourceManager会将有空闲槽位的TaskManager分配给 JobMaster。如果ResourceManager没有足够的任务槽,它还可以向资源提供平台发起会话,请求提供启动TaskManager进程的容器。另外,ResourceManager还负责停掉空闲的TaskManager,释放计算资源。
- 分发器(Dispatcher):
- Dispatcher主要负责提供一个REST接口,用来提交应用,并且负责为每一个新提交的作业启动一个新的JobMaster组件。Dispatcher也会启动一个Web UI,用来方便地展示和监控作业执行的信息。Dispatcher在架构中并不是必需的,在不同的部署模式下可能会被忽略掉。
- JobMaster:
4.1.3 任务管理器(TaskManager)
- TaskManager是Flink中的工作进程,数据流的具体计算就是它来做的,所以也被称为“Worker”。Flink集群中必须至少有一个TaskManager;当然由于分布式计算的考虑,通常会有多个TaskManager运行,每一个 TaskManager都包含了一定数量的任务槽(task slots)。Slot是资源调度的最小单位,slot的数量限制了 TaskManager能够并行处理的任务数量。
- 启动之后,TaskManager会向资源管理器注册它的slots;收到资源管理器的指令后,TaskManager就会将一个或者多个槽位提供给JobMaster调用,JobMaster就可以分配任务来执行了。
- 在执行过程中,TaskManager可以缓冲数据,还可以跟其他运行同一应用的TaskManager交换数据。
4.2 作业提交流程
- 了解了Flink运行时的基本组件和系统架构,我们再来梳理一下作业提交的具体流程。
4.2.1 高层级抽象视角
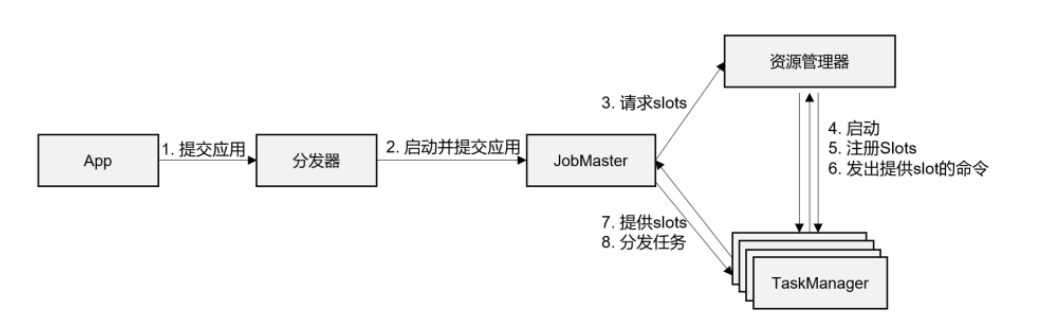
Flink的提交流程,随着部署模式、资源管理平台的不同,会有不同的变化。首先我们从 一个高层级的视角,来做一下抽象提炼,看一看作业提交时宏观上各组件是怎样交互协作的。
![]()
- ①一般情况下,由客户端(App)通过分发器提供的REST接口,将作业提交给JobManager。
- ②由分发器启动JobMaster,并将作业(包含 JobGraph)提交给JobMaster。
- ③JobMaster将JobGraph解析为可执行的ExecutionGraph,得到所需的资源数量,然后向资源管理器请求资源(slots)。
- ④资源管理器判断当前是否由足够的可用资源;如果没有,启动新的TaskManager。
- ⑤TaskManager启动之后,向ResourceManager注册自己的可用任务槽(slots)。
- ⑥资源管理器通知TaskManager为新的作业提供slots。
- ⑦TaskManager连接到对应的JobMaster,提供slots。
- ⑧JobMaster将需要执行的任务分发给TaskManager。
- ⑨TaskManager执行任务,互相之间可以交换数据。
如果部署模式不同,或者集群环境不同(例如Standalone、YARN、K8S 等),其中一些步骤可能会不同或被省略,也可能有些组件会运行在同一个JVM进程中。比如我们在上一章实践过的独立集群环境的会话模式,就是需要先启动集群,如果资源不够,只能等待资源释放, 而不会直接启动新的TaskManager。
接下来我们就具体介绍一下不同部署环境下的提交流程。
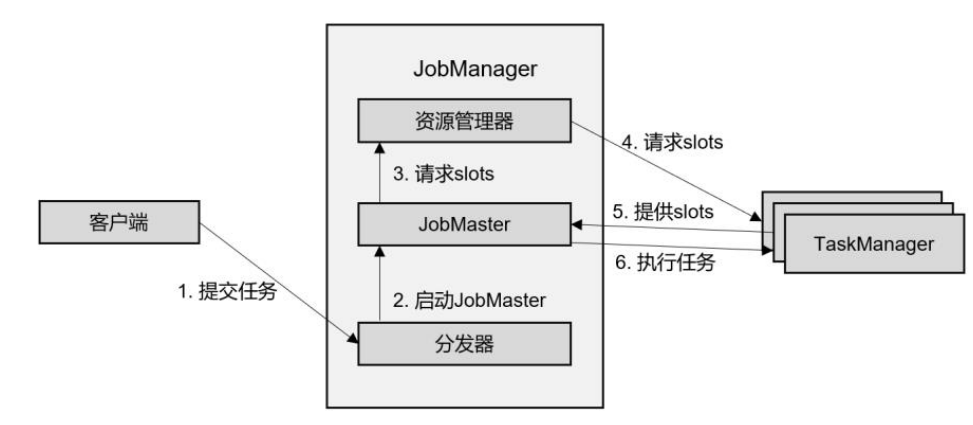
4.2.2 独立模式(Standalone)
在独立模式(Standalone)下,只有会话模式和应用模式两种部署方式。两者整体来看流程是非常相似的:TaskManager都需要手动启动,所以当ResourceManager收到JobMaster的请求时,会直接要求TaskManager提供资源。而JobMaster的启动时间点,会话模式是预先启动,应用模式则是在作业提交时启动。提交的整体流程如图所示。
![]()
- 我们发现除去第4步不会启动TaskManager,而且直接向已有的TaskManager要求资源, 其他步骤与上一节所讲抽象流程完全一致。
4.2.3 YARN集群
接下来我们再看一下有资源管理平台时,具体的提交流程。我们以YARN为例,分不同的部署模式来做具体说明。
会话(Session)模式。
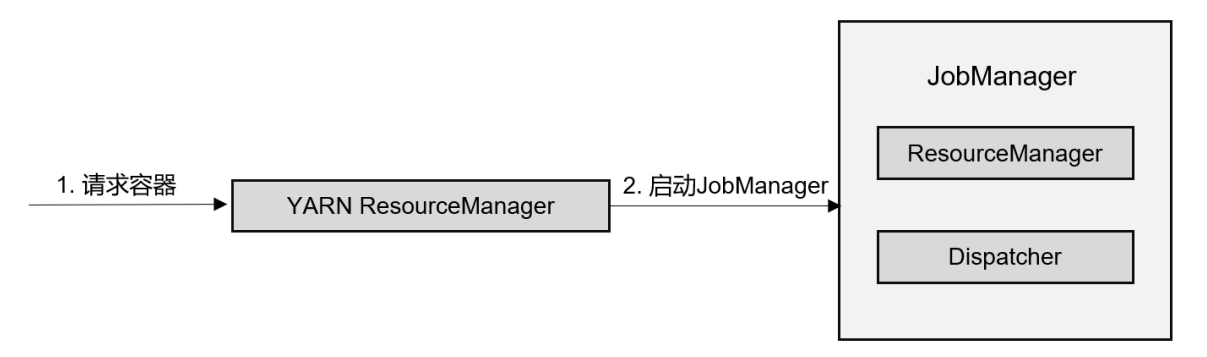
在会话模式下,我们需要先启动一个YARN session,这个会话会创建一个Flink集群。这里只启动了JobManager,而TaskManager可以根据需要动态地启动。在JobManager内部,由于还没有提交作业,所以只有ResourceManager和Dispatcher在运行,如图所示。
![]()
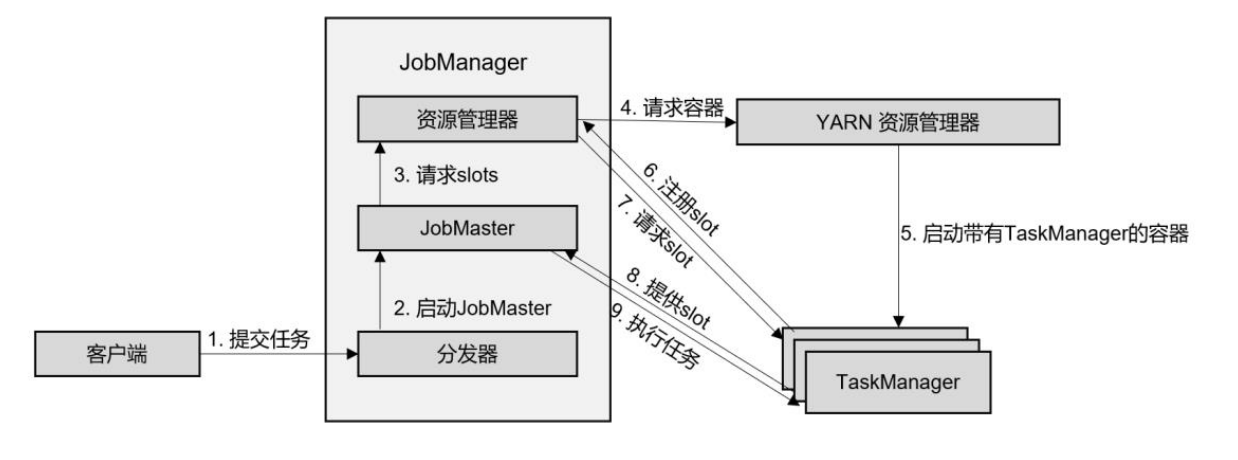
接下来就是真正提交作业的流程,如图所示:
![]()
- ①客户端通过REST接口,将作业提交给分发器。
- ②分发器启动JobMaster,并将作业(包含 JobGraph)提交给JobMaster。
- ③JobMaster向资源管理器请求资源(slots)。
- ④资源管理器向YARN的资源管理器请求container资源。
- ⑤YARN启动新的TaskManager容器。
- ⑥TaskManager启动之后,向Flink的资源管理器注册自己的可用任务槽。
- ⑦资源管理器通知TaskManager为新的作业提供slots。
- ⑧TaskManager连接到对应的JobMaster,提供slots。
- ⑨JobMaster将需要执行的任务分发给TaskManager,执行任务。
可见,整个流程除了请求资源时要“上报”YARN的资源管理器,其他与4.2.1节所述抽象流程几乎完全一样。
单作业(Per-Job)模式。
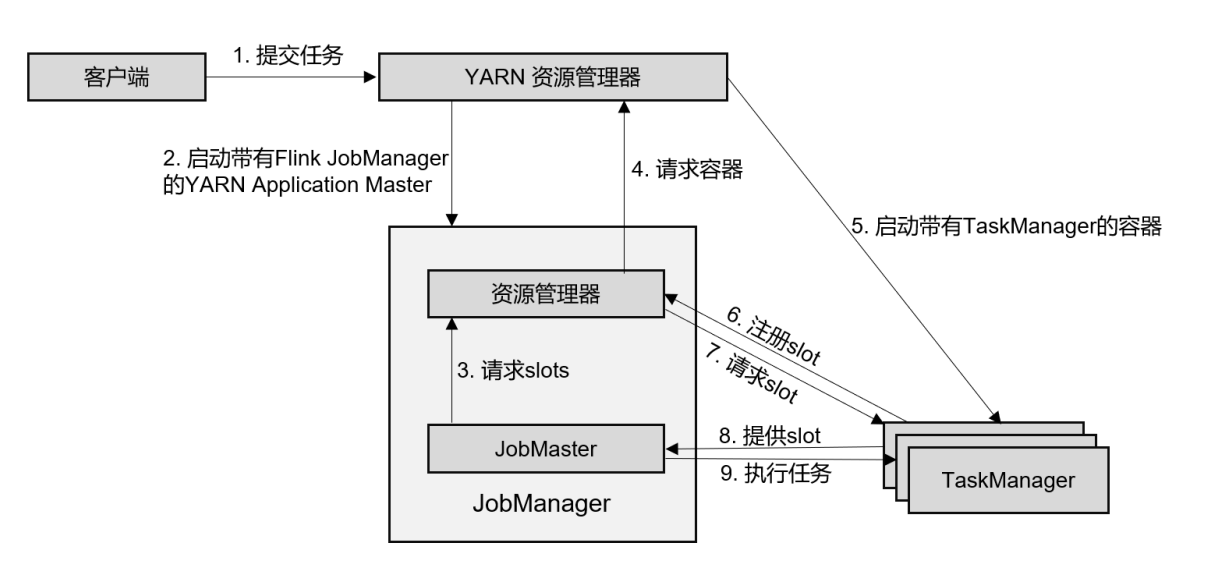
在单作业模式下,Flink集群不会预先启动,而是在提交作业时,才启动新的JobManager。具体流程如图所示。
![]()
- ①客户端将作业提交给YARN的资源管理器,这一步中会同时将Flink的Jar包和配置上传到HDFS,以便后续启动Flink相关组件的容器。
- ②YARN的资源管理器分配Container资源,启动Flink JobManager,并将作业提交给JobMaster。这里省略了Dispatcher组件。
- ③JobMaster向资源管理器请求资源(slots)。
- ④资源管理器向YARN的资源管理器请求container资源。
- ⑤YARN启动新的TaskManager容器。
- ⑥TaskManager启动之后,向Flink的资源管理器注册自己的可用任务槽。
- ⑦资源管理器通知TaskManager为新的作业提供slots。
- ⑧TaskManager连接到对应的JobMaster,提供slots。
- ⑨JobMaster将需要执行的任务分发给TaskManager,执行任务。
可见,区别只在于JobManager的启动方式,以及省去了分发器。当第2步作业提交给JobMaster,之后的流程就与会话模式完全一样了。
应用(Application)模式。
- 应用模式与单作业模式的提交流程非常相似,只是初始提交给YARN资源管理器的不再是具体的作业,而是整个应用。一个应用中可能包含了多个作业,这些作业都将在Flink集群中启动各自对应的 JobMaster。
4.3 一些重要概念
4.3.1 数据流图(Dataflow Graph)
Flink是流式计算框架。它的程序结构,其实就是定义了一连串的处理操作,每一个数据输入之后都会依次调用每一步计算。在Flink代码中,我们定义的每一个处理转换操作都叫作 “算子”(Operator),所以我们的程序可以看作是一串算子构成的管道,数据则像水流一样有序地流过。比如在之前的WordCount代码中,基于执行环境调用的socketTextStream()方法,就是一个读取文本流的算子;而后面的flatMap()方法,则是将字符串数据进行分词、转换成二元组的算子。
所有的Flink程序都可以归纳为由三部分构成:Source、Transformation和Sink。
- Source表示“源算子”,负责读取数据源。
- Transformation表示“转换算子”,利用各种算子进行处理加工。
- Sink表示“下沉算子”,负责数据的输出。
在运行时,Flink程序会被映射成所有算子按照逻辑顺序连接在一起的一张图,这被称为 “逻辑数据流”(logical dataflow),或者叫“数据流图”(dataflow graph)。我们提交作业之后, 打开Flink自带的 Web UI,点击作业就能看到对应的dataflow,如图所示。在数据流图中,可以清楚地看到Source、Transformation、Sink三部分。
![]()
数据流图类似于任意的有向无环图(DAG),这一点与Spark等其他框架是一致的。图中的每一条数据流(dataflow)以一个或多个source算子开始,以一个或多个sink算子结束。
在大部分情况下,dataflow中的算子,和程序中的转换运算是一一对应的关系。那是不是说,我们代码中基于DataStream API的每一个方法调用,都是一个算子呢?
- 并非如此。除了Source读取数据和Sink输出数据,一个中间的转换算子(Transformation Operator)必须是一个转换处理的操作;而在代码中有一些方法调用,数据是没有完成转换的。 可能只是对属性做了一个设置,也可能定义的是数据的传递方式而非转换,又或者是需要几个方法合在一起才能表达一个完整的转换操作。例如,在之前的代码中,我们用到了定义分组的方法keyBy,它就只是一个数据分区操作,而并不是一个算子。事实上,代码中我们可以看到调用其他转换操作之后返回的数据类型是SingleOutputStreamOperator,说明这是一个算子操作;而keyBy之后返回的数据类型是KeyedStream。
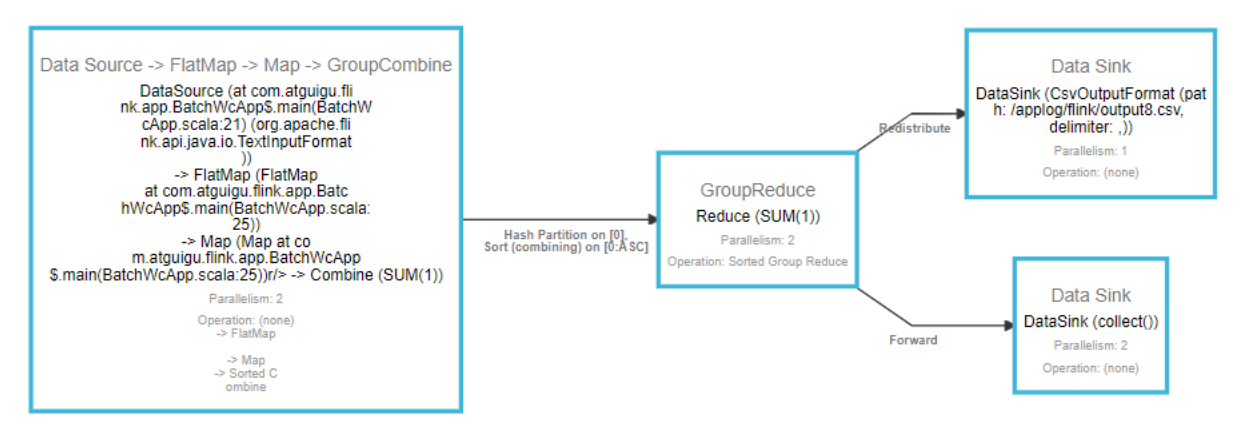
4.3.2 并行度(Parallelism)
我们已经清楚了算子和数据流图的概念,那最终执行的任务又是什么呢?容易想到,一个算子操作就应该是一个任务。那是不是程序中的算子数量,就是最终执行的任务数呢?
什么是并行计算?
- 在大数据场景下,我们都是依靠分布式架构做并行计算,从而提高数据吞吐量的。既然处理完一个操作就可以把数据发往别处,那我们就可以将不同的算子操作任务,分配到不同的节点上执行了。这样就对任务做了分摊,实现了并行处理。
- 但是仔细分析会发现,这种“并行”其实并不彻底。因为算子之间是有执行顺序的,对一条数据来说必须依次执行;而一个算子在同一时刻只能处理一个数据。比如之前WordCount,一条数据到来之后,我们必须先用source算子读进来、再做flatMap转换;一条数据被source读入的同时,之前的数据可能正在被flatMap处理,这样不同的算子任务是并行的。但如果多条数据同时到来,一个算子是没有办法同时处理的,我们还是需要等待一条数据处理完、再处理下一条数据——这并没有真正提高吞吐量。
- 所以相对于上述的“任务并行”,我们真正关心的,是“数据并行”。也就是说,多条数据同时到来,我们应该可以同时读入,同时在不同节点执行flatMap操作。
并行子任务和并行度。
怎样实现数据并行呢?其实也很简单,我们把一个算子操作,“复制”多份到多个节点,数据来了之后就可以到其中任意一个执行。这样一来,一个算子任务就被拆分成了多个并行的“子任务”(subtasks),再将它们分发到不同节点,就真正实现了并行计算。
在Flink执行过程中,每一个算子(operator)可以包含一个或多个子任务(operator subtask), 这些子任务在不同的线程、不同的物理机或不同的容器中完全独立地执行。
一个特定算子的子任务(subtask)的个数被称之为其并行度(parallelism)。这样,包含并行子任务的数据流,就是并行数据流,它需要多个分区(stream partition)来分配并行任务。一般情况下,一个流程序的并行度,可以认为就是其所有算子中最大的并行度。一个程序中,不同的算子可能具有不同的并行度。
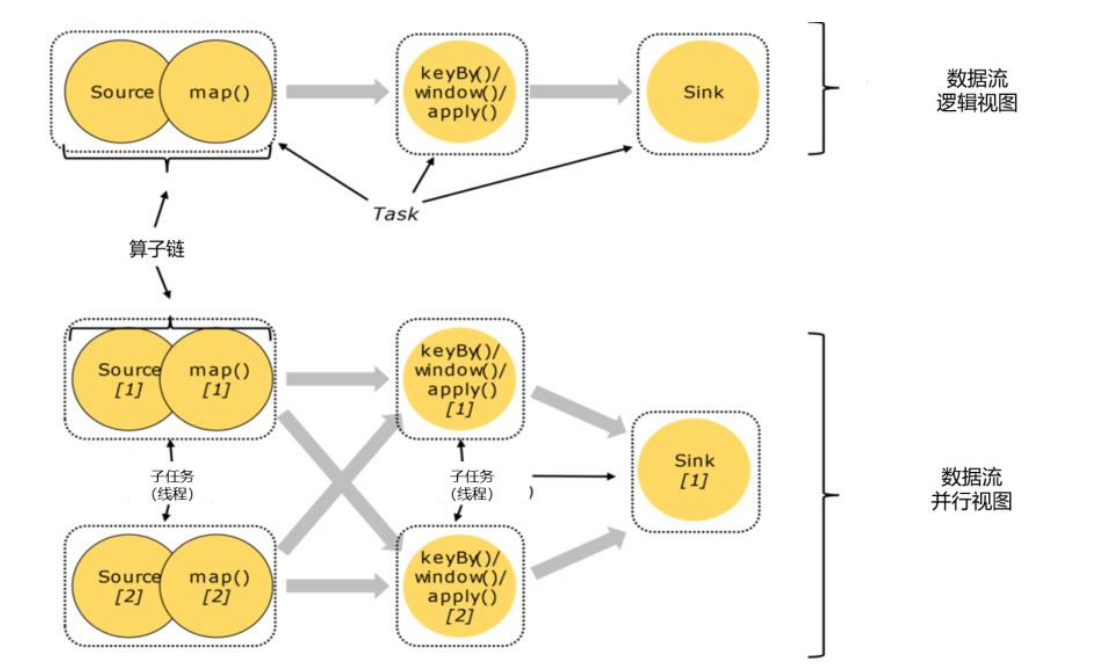
如图所示,当前数据流中有source、map、window、sink四个算子,除最后sink,其他算子的并行度都为2。整个程序包含了7个子任务,至少需要2个分区来并行执行。我们可以说,这段流处理程序的并行度就是2。
![]()
并行度的设置。在Flink中,可以用不同的方法来设置并行度,它们的有效范围和优先级别也是不同的。
代码中设置。
我们在代码中,可以很简单地在算子后跟着调用setParallelism()方法,来设置当前算子的 并行度。这种方式设置的并行度,只针对当前算子有效。
1
stream.map(word -> Tuple2.of(word, 1L)).setParallelism(2);
另外,我们也可以直接调用执行环境的setParallelism()方法,全局设定并行度。这样代码中所有算子,默认的并行度就都为2了。我们一般不会在程序中设置全局并行度,因为如果在程序中对全局并行度进行硬编码,会导致无法动态扩容。
1
env.setParallelism(2);
这里要注意的是,由于keyBy不是算子,所以无法对keyBy设置并行度。
提交应用时设置。
在使用flink run命令提交应用时,可以增加-p参数来指定当前应用程序执行的并行度,它的作用类似于执行环境的全局设置。
1
bin/flink run –p 2 –c com.demo.StreamWordCount ./flinkdemo-1.0-SNAPSHOT.jar
如果我们直接在Web UI上提交作业,也可以在对应输入框中直接添加并行度。
配置文件中设置。
我们还可以直接在集群的配置文件flink-conf.yaml中直接更改默认并行度:
1
parallelism.default: 2
这个设置对于整个集群上提交的所有作业有效,初始值为1。无论在代码中设置、还是提交时的-p参数,都不是必须的;所以在没有指定并行度的时候,就会采用配置文件中的集群默认并行度。在开发环境中,没有配置文件,默认并行度就是当前机器的CPU核心数。这也就解释了为什么我们在第二章运行WordCount流处理程序时,会看到结果前有1~8的分区编号——运行程序的电脑是8核CPU,那么开发环境默认的并行度就是8。
我们可以总结一下所有的并行度设置方法,它们的优先级如下:
- 对于一个算子,首先看在代码中是否单独指定了它的并行度,这个特定的设置优先级最高,会覆盖后面所有的设置。
- 如果没有单独设置,那么采用当前代码中执行环境全局设置的并行度。
- 如果代码中完全没有设置,那么采用提交时-p参数指定的并行度。
- 如果提交时也未指定-p参数,那么采用集群配置文件中的默认并行度。
这里需要说明的是,算子的并行度有时会受到自身具体实现的影响。比如之前我们用到的读取 socket 文本流的算子socketTextStream,它本身就是非并行的Source算子,所以无论怎么 设置,它在运行时的并行度都是 1,对应在数据流图上就只有一个并行子任务。那么实践中怎样设置并行度比较好呢?那就是在代码中只针对算子设置并行度,不设置全局并行度,这样方便我们提交作业时进行动态扩容。
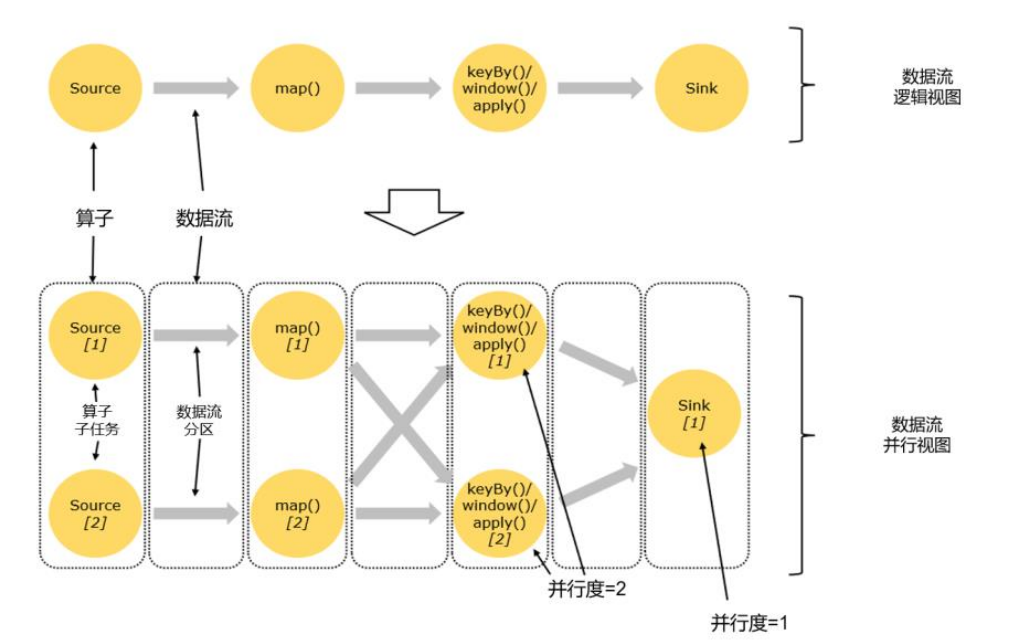
4.3.3 算子链(Operator Chain)
关于“一个作业有多少任务”这个问题,现在已经基本解决了。但如果我们仔细观察Web UI上给出的图,如图所示,上面的节点似乎跟代码中的算子又不是一一对应的。很明显,这里的一个节点,会把转换处理的很多个任务都连接在一起,合并成了一个“大任务”。这又是怎么回事呢?
![]()
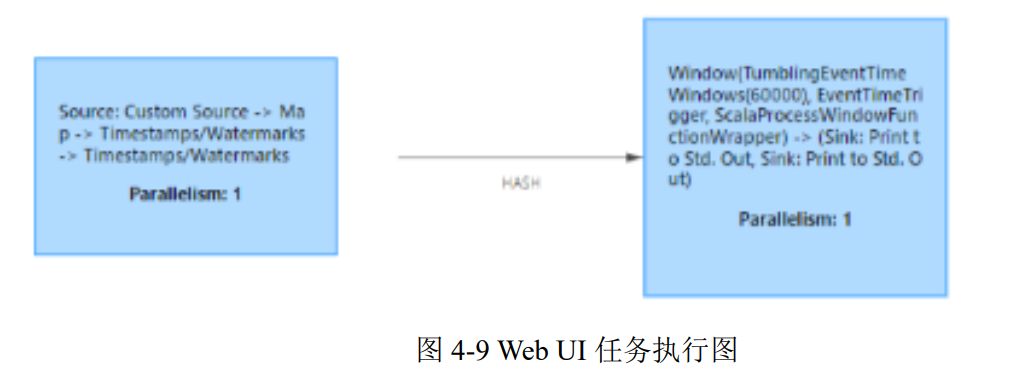
算子间的数据传输
如图所示,一个数据流在算子之间传输数据的形式可以是一对一(one-to-one)的直通 (forwarding)模式,也可以是打乱的重分区(redistributing)模式,具体是哪一种形式,取决于算子的种类。
![]()
- 一对一(One-to-one,forwarding)
- 这种模式下,数据流维护着分区以及元素的顺序。比如图中的source和map算子,source算子读取数据之后,可以直接发送给map算子做处理,它们之间不需要重新分区,也不需要调整数据的顺序。这就意味着map算子的子任务,看到的元素个数和顺序跟source算子的子任务产生的完全一样,保证着“一对一”的关系。map、filter、flatMap等算子都是这种one-to-one的对应关系。
- 这种关系类似于 Spark中的窄依赖。
- 重分区(Redistributing)
- 在这种模式下,数据流的分区会发生改变。比图中的map和后面的keyBy/window算子之间(这里的 keyBy是数据传输算子,后面的window、apply方法共同构成了window算子), 以及keyBy/window 算子和Sink算子之间,都是这样的关系。
- 每一个算子的子任务,会根据数据传输的策略,把数据发送到不同的下游目标任务。例如,keyBy()是分组操作,本质上基于键(key)的哈希值(hashCode)进行了重分区;而当并行度改变时,比如从并行度为2的window算子,要传递到并行度为1的Sink算子,这时的数据传输方式是再平衡(rebalance),会把数据均匀地向下游子任务分发出去。这些传输方式都会引起重分区(redistribute)的过程,这一过程类似于Spark中的 shuffle。
- 总体说来,这种算子间的关系类似于Spark中的宽依赖。
- 一对一(One-to-one,forwarding)
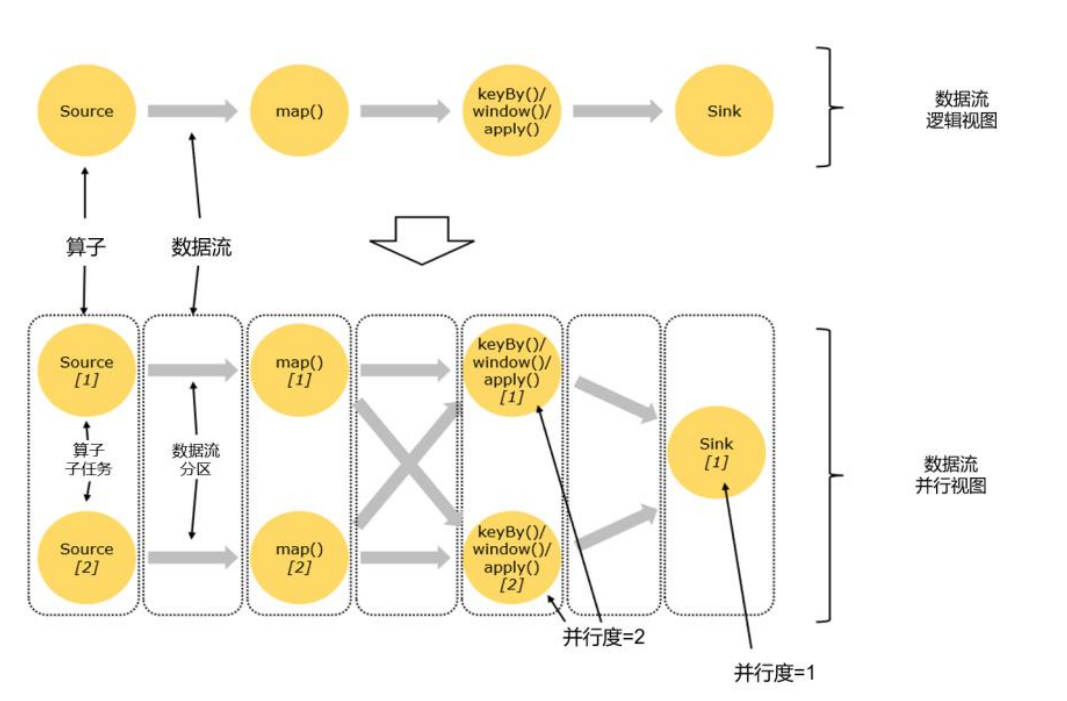
合并算子链
在Flink中,并行度相同的一对一(one to one)算子操作,可以直接链接在一起形成一个 “大”的任务(task),这样原来的算子就成为了真正任务里的一部分,如图所示。每个task会被一个线程执行。这样的技术被称为“算子链”(Operator Chain)。
比如在图中的例子中,Source和map之间满足了算子链的要求,所以可以直接合并在一起,形成了一个任务;因为并行度为2,所以合并后的任务也有两个并行子任务。这样,这个数据流图所表示的作业最终会有5个任务,由5个线程并行执行。
![]()
Flink为什么要有算子链这样一个设计呢?这是因为将算子链接成task是非常有效的优化:可以减少线程之间的切换和基于缓存区的数据交换,在减少时延的同时提升吞吐量。
Flink默认会按照算子链的原则进行链接合并,如果我们想要禁止合并或者自行定义,也可以在代码中对算子做一些特定的设置:
1
2
3
4// 禁用算子链
.map(word -> Tuple2.of(word, 1L)).disableChaining();
// 从当前算子开始新链
.map(word -> Tuple2.of(word, 1L)).startNewChain()
4.3.4 作业图(JobGraph)与执行图(ExecutionGraph)
由Flink程序直接映射成的数据流图(dataflow graph),也被称为逻辑流图(logical StreamGraph),因为它们表示的是计算逻辑的高级视图。到具体执行环节时,我们还要考虑并行子任务的分配、数据在任务间的传输,以及合并算子链的优化。为了说明最终应该怎样执行一个流处理程序,Flink需要将逻辑流图进行解析,转换为物理数据流图。
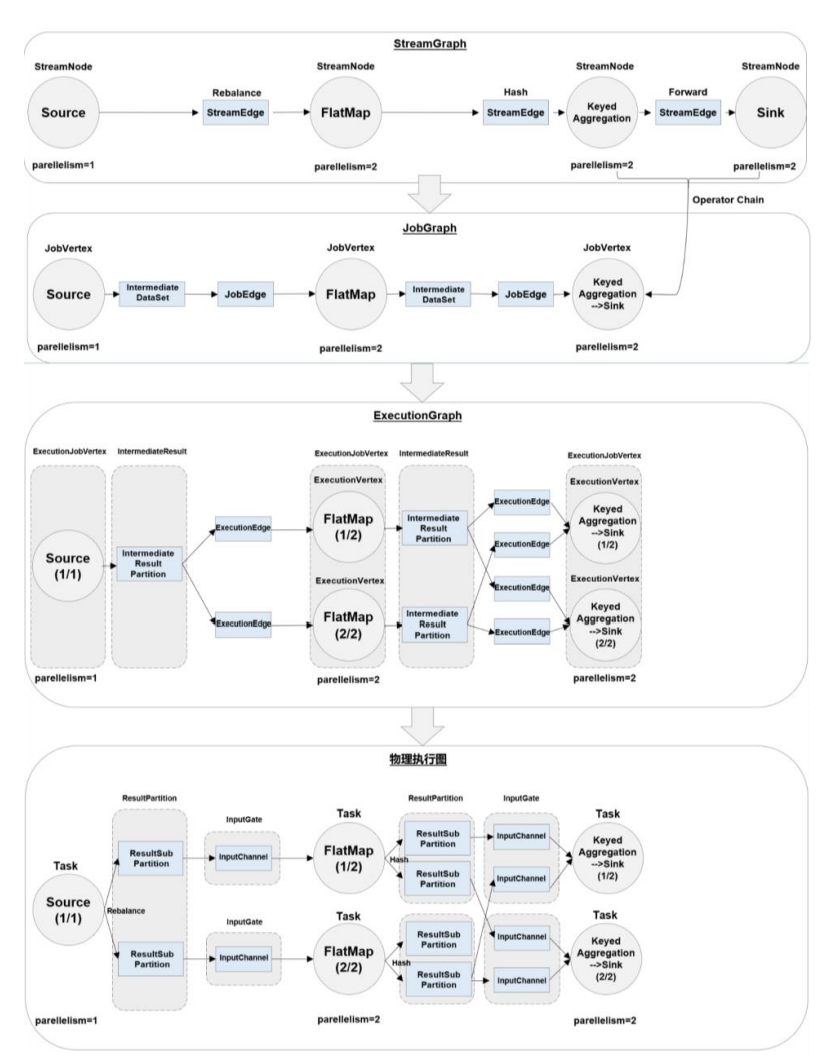
在这个转换过程中,有几个不同的阶段,会生成不同层级的图,其中最重要的就是作业图 (JobGraph)和执行图(ExecutionGraph)。Flink中任务调度执行的图,按照生成顺序可以分成四层:逻辑流图(StreamGraph)→ 作业图(JobGraph)→ 执行图(ExecutionGraph)→ 物理图(Physical Graph)。
之前处理socket文本流的StreamWordCount程序:
1
env.socketTextStream().flatMap(…).keyBy(0).sum(1).print();
如果提交时设置并行度为2:
1
bin/flink run –p 2 –c com.demo.StreamWordCount ./flinkdemo-1.0-SNAPSHOT.jar
那么根据之前的分析,除了socketTextStream()是非并行的Source算子,它的并行度始终 为1,其他算子的并行度都为2。
接下来我们分析一下程序对应四层调度图的演变过程,如图所示。
![]()
- 逻辑流图(StreamGraph)
- 这是根据用户通过DataStream API编写的代码生成的最初的 DAG 图,用来表示程序的拓扑结构。这一步一般在客户端完成。
- 我们可以看到,逻辑流图中的节点,完全对应着代码中的四步算子操作:**源算子 Source(socketTextStream())→扁平映射算子Flat Map(flatMap()) →分组聚合算子Keyed Aggregation(keyBy/sum()) →输出算子 Sink(print())**。
- 作业图(JobGraph)
- StreamGraph经过优化后生成的就是作业图(JobGraph),这是提交给JobManager的数据结构,确定了当前作业中所有任务的划分。主要的优化为:将多个符合条件的节点链接在一起合并成一个任务节点,形成算子链,这样可以减少数据交换的消耗。JobGraph一般也是在客户端生成的,在作业提交时传递给JobMaster。
- 在图中,分组聚合算子(Keyed Aggregation)和输出算子Sink(print)并行度都为2, 而且是一对一的关系,满足算子链的要求,所以会合并在一起,成为一个任务节点。
- 执行图(ExecutionGraph)
- JobMaster收到JobGraph后,会根据它来生成执行图(ExecutionGraph)。ExecutionGraph是JobGraph的并行化版本,是调度层最核心的数据结构。
- 从图中可以看到,与JobGraph最大的区别就是按照并行度对并行子任务进行了拆分,并明确了任务间数据传输的方式。
- 物理图(Physical Graph)
- JobMaster生成执行图后,会将它分发给TaskManager;各个TaskManager会根据执行图部署任务,最终的物理执行过程也会形成一张“图”,一般就叫作物理图(Physical Graph)。这只是具体执行层面的图,并不是一个具体的数据结构。
- 对应在上图中,物理图主要就是在执行图的基础上,进一步确定数据存放的位置和收发的具体方式。有了物理图,TaskManager就可以对传递来的数据进行处理计算了。
- 逻辑流图(StreamGraph)
所以我们可以看到,程序里定义了四个算子操作:源(Source)->转换(flatMap)->分组聚合(keyBy/sum)->输出(print);合并算子链进行优化之后,就只有三个任务节点了;再考虑并行度后,一共有5个并行子任务,最终需要5个线程来执行。
4.3.5 任务(Tasks)和任务槽(Task Slots)
通过前几小节的介绍,我们对任务的生成和分配已经非常清楚了。上一小节中我们最终得到结论:作业划分为5个并行子任务,需要5个线程并行执行。那在我们将应用提交到Flink集群之后,到底需要占用多少资源呢?是否需要5个TaskManager来运行呢?
任务槽(Task Slots)
之前已经提到过,Flink中每一个worker(也就是TaskManager)都是一个JVM进程,它可以启动多个独立的线程,来并行执行多个子任务(subtask)。所以如果想要执行5个任务,并不一定非要5个 TaskManager,我们可以让TaskManager多线程执行任务。如果可以同时运行5个线程,那么只要一个TaskManager就可以满足我们之前程序的运行需求了。
很显然,TaskManager的计算资源是有限的,并不是所有任务都可以放在一个TaskManager上并行执行。并行的任务越多,每个线程的资源就会越少。那一个TaskManager到底能并行处理多少个任务呢?为了控制并发量,我们需要在TaskManager上对每个任务运行所占用的资源做出明确的划分,这就是所谓的任务槽(task slots)。
每个任务槽(task slot)其实表示了TaskManager拥有计算资源的一个固定大小的子集。这些资源就是用来独立执行一个子任务的。
假如一个TaskManager有三个slot,那么它会将管理的内存平均分成三份,每个slot独自占据一份。这样一来,我们在slot上执行一个子任务时,相当于划定了一块内存“专款专用”,就不需要跟来自其他作业的任务去竞争内存资源了。所以现在我们只要2个TaskManager,就可以并行处理分配好的5 个任务了,如图所示。
![]()
任务槽数量的设置
我们可以通过集群的配置文件来设定TaskManager的slot数量:
1
taskmanager.numberOfTaskSlots: 8
通过调整slot的数量,我们就可以控制子任务之间的隔离级别。
具体来说,如果一个TaskManager只有一个slot,那将意味着每个任务都会运行在独立的JVM中(当然,该JVM可能是通过一个特定的容器启动的);而一个TaskManager设置多个slot则意味着多个子任务可以共享同一个JVM。它们的区别在于:前者任务之间完全独立运行, 隔离级别更高、彼此间的影响可以降到最小;而后者在同一个JVM进程中运行的任务,将共享TCP连接和心跳消息,也可能共享数据集和数据结构,这就减少了每个任务的运行开销, 在降低隔离级别的同时提升了性能。
需要注意的是,slot目前仅仅用来隔离内存,不会涉及CPU的隔离。在具体应用时,可以将slot数量配置为机器的CPU核心数,尽量避免不同任务之间对CPU的竞争。这也是开发环境默认并行度设为机器CPU数量的原因。
任务对任务槽的共享
这样看来,一共有多少任务,我们就需要有多少slot来并行处理它们。不过实际提交作业进行测试就会发现,我们之前的WordCount程序设置并行度为2提交,一共有5个并行子任务,可集群即使只有2个task slot也是可以成功提交并运行的。这又是为什么呢?
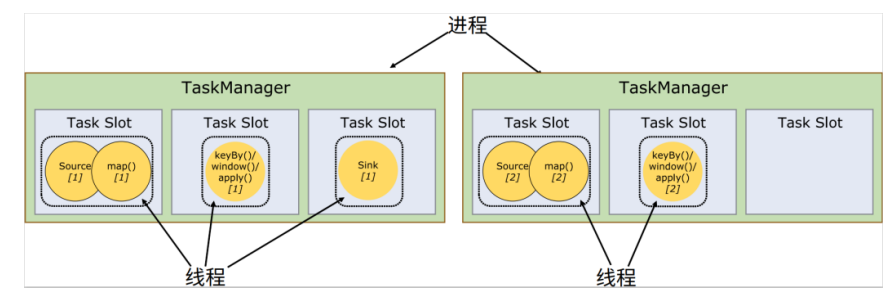
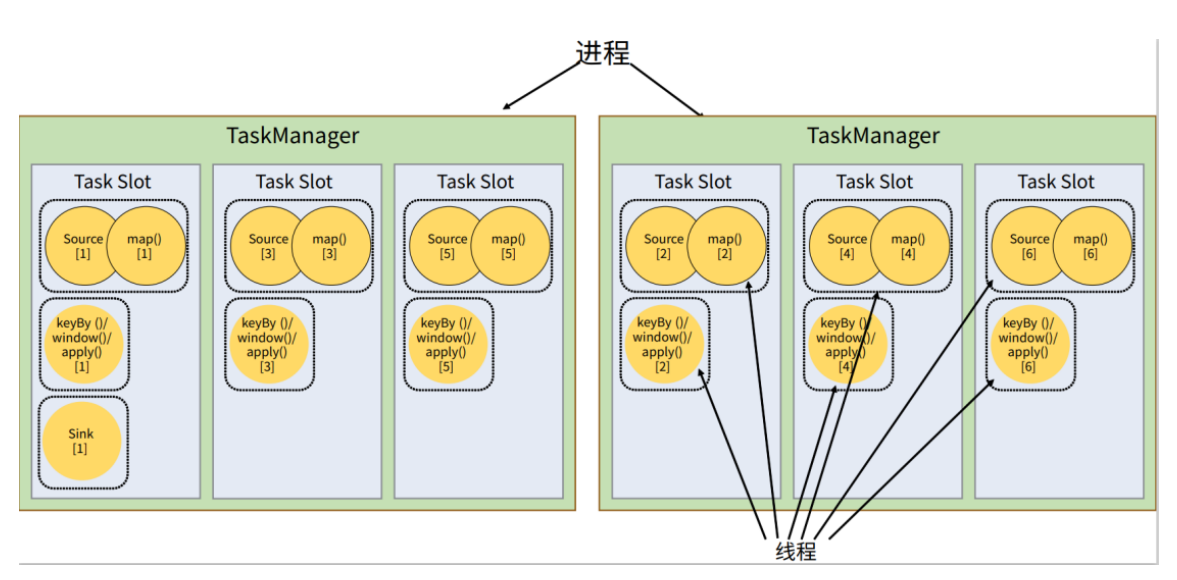
我们可以基于之前的例子继续扩展。如果我们保持sink任务并行度为1不变,而作业提交时设置全局并行度为6,那么前两个任务节点就会各自有6个并行子任务,整个流处理程序则有13个子任务。那对于2个TaskManager、每个有3个slot的集群配置来说,还能否正常运行呢?
完全没有问题。这是因为默认情况下,Flink是允许子任务共享slot的。如图所示, 只要属于同一个作业,那么对于不同任务节点的并行子任务,就可以放到同一个slot上执行。所以对于第一个任务节点 source→map,它的6个并行子任务必须分到不同的slot上(如果在同一slot就没法数据并行了),而第二个任务节点keyBy/window/apply的并行子任务却可以和第一个任务节点共享slot。
![]()
于是最终结果就变成了:每个任务节点的并行子任务一字排开,占据不同的slot;而不同的任务节点的子任务可以共享slot。一个slot中,可以将程序处理的所有任务都放在这里执行, 我们把它叫作保存了整个作业的运行管道(pipeline)。
当我们将资源密集型和非密集型的任务同时放到一个slot中,它们就可以自行分配对资源占用的比例,从而保证最重的活平均分配给所有的TaskManager。slot共享另一个好处就是允许我们保存完整的作业管道。这样一来,即使某个TaskManager出现故障宕机,其他节点也可以完全不受影响,作业的任务可以继续执行。
另外,同一个任务节点的并行子任务是不能共享slot的,所以允许slot共享之后,运行作业所需的slot数量正好就是作业中所有算子并行度的最大值。这样一来,我们考虑当前集群需要配置多少slot资源时,就不需要再去详细计算一个作业总共包含多少个并行子任务了,只看最大的并行度就够了。
当然,Flink默认是允许slot共享的,如果希望某个算子对应的任务完全独占一个slot,或者只有某一部分算子共享slot,我们也可以通过设置“slot 共享组”(SlotSharingGroup)手动指定:
1
.map(word -> Tuple2.of(word, 1L)).slotSharingGroup(“1”);
- 这样,只有属于同一个slot共享组的子任务,才会开启slot共享;不同组之间的任务是完全隔离的,必须分配到不同的slot上。在这种场景下,总共需要的slot数量,就是各个slot共享组最大并行度的总和。
任务槽和并行度的关系
直观上看,slot就是TaskManager为了并行执行任务而设置的,那它和之前讲过的并行度(Parallelism)是不是一回事呢?
Slot和并行度确实都跟程序的并行执行有关,但两者是完全不同的概念。简单来说,task slot是静态的概念,是指TaskManager具有的并发执行能力,可以通过参数taskmanager.numberOfTaskSlots进行配置;而并行度(parallelism)是动态概念,也就是TaskManager运行程序时实际使用的并发能力,可以通过参数parallelism.default进行配置。换句话说,并行度如果小于等于集群中可用slot的总数,程序是可以正常执行的,因为slot不一定要全部占用,有十分力气可以只用八分;而如果并行度大于可用slot总数,导致超出了并行能力上限,那么心有余力不足,程序就只好等待资源管理器分配更多的资源了。
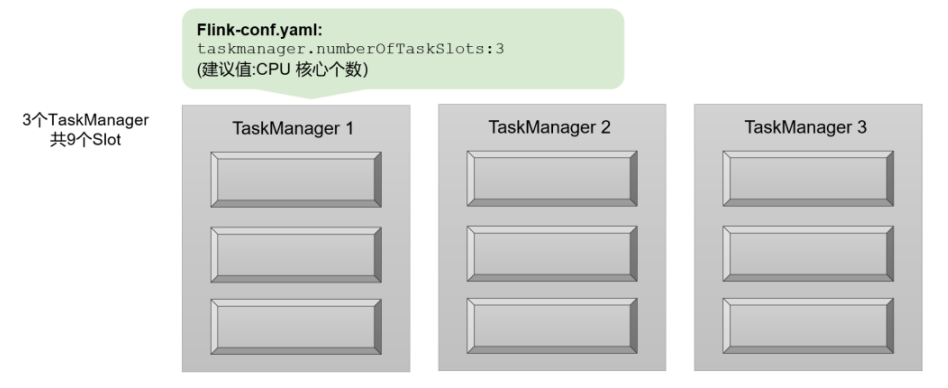
下面再举一个具体的例子。假设一共有3个TaskManager,每一个TaskManager中的slot数量设置为3个,那么一共有9个task slot,如图所示,表示集群最多能并行执行9个任务。而我们定义WordCount程序的处理操作是四个转换算子:source→ flatMap→ reduce→ sink。当所有算子并行度相同时,容易看出source和flatMap可以合并算子链,于是最终有三个任务节点。
![]()
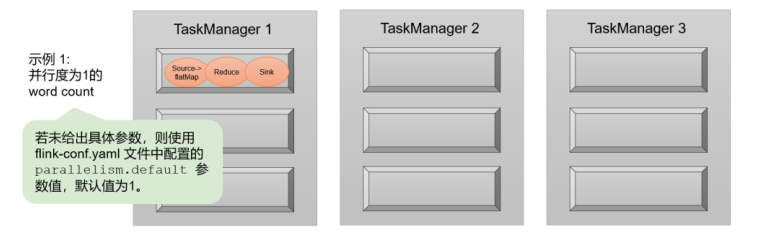
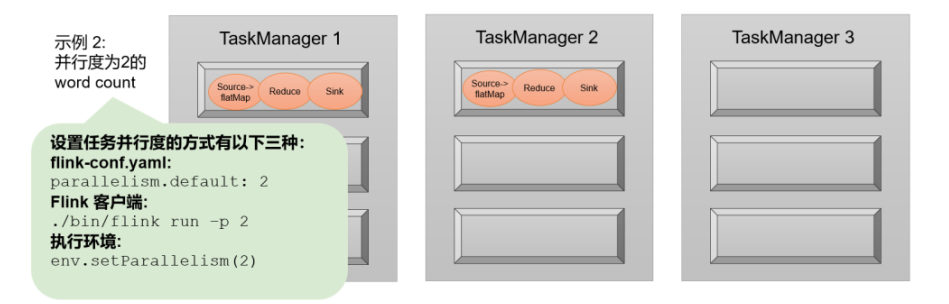
如果我们没有任何并行度设置,而配置文件中默认parallelism.default=1,那么程序运行的默认并行度为1,总共有3个任务。由于不同算子的任务可以共享任务槽,所以最终占用的slot只有1个。9个slot只用了1个,有8个空闲,如图所示。
![]()
如果我们更改默认参数,或者提交作业时设置并行度为2,那么总共有6个任务,共享任务槽之后会占用2个slot,如图所示。同样,就有7个 slot 空闲,计算资源没有充分利用。所以可以看到,设置合适的并行度才能提高效率。
![]()
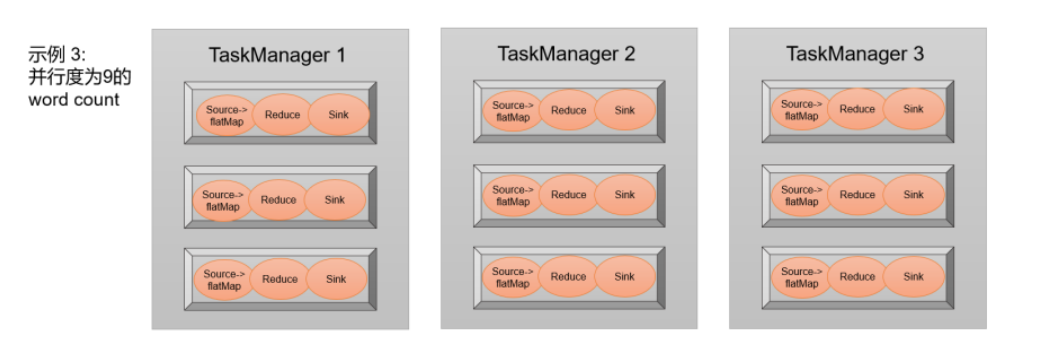
那对于这个例子,怎样设置并行度效率最高呢?当然是需要把所有的slot都利用起来。考虑到slot共享,我们可以直接把并行度设置为9,这样所有27个任务就会完全占用9个slot。这是当前集群资源下能执行的最大并行度,计算资源得到了充分的利用,如图所示。
![]()
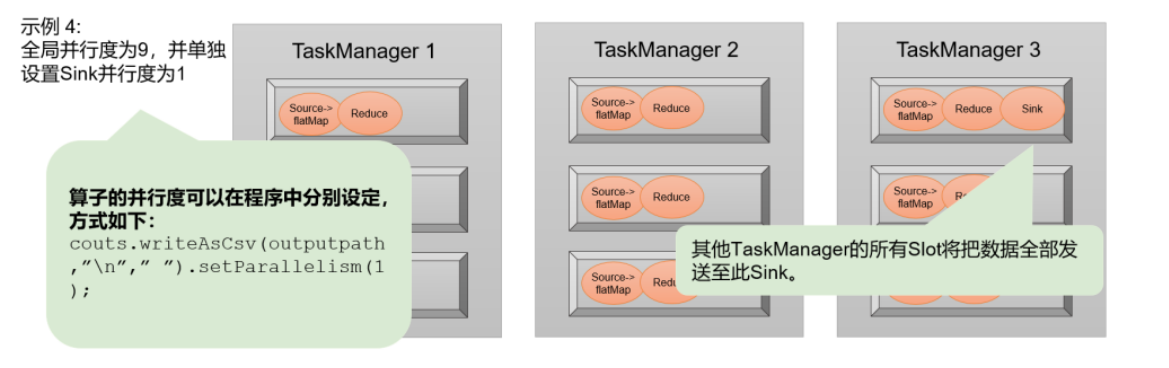
另外再考虑对于某个算子单独设置并行度的场景。例如,如果我们考虑到输出可能是写入文件,那会希望不要并行写入多个文件,就需要设置sink算子的并行度为1。这时其他的算子并行度依然为 9,所以总共会有19个子任务。根据slot共享的原则,它们最终还是会占用全部的9个 slot,而sink任务只在其中一个slot上执行,如图所示。通过这个例子也可以明确地看到,整个流处理程序的并行度,就应该是所有算子并行度中最大的那个,这代表了运行程序需要的slot数量。
![]()