Flink中的时间和窗口
1、简介
- 我们已经了解了基本API的用法,熟悉了DataStream进行简单转换、聚合的一些操作。 除此之外,Flink还提供了丰富的转换算子,可以用于更加复杂的处理场景。
- 在流数据处理应用中,一个很重要、也很常见的操作就是窗口计算。所谓的“窗口”,一般就是划定的一段时间范围,也就是“时间窗”;对在这范围内的数据进行处理,就是所谓的窗口计算。所以窗口和时间往往是分不开的。
2、时间语义
对于一台机器而言,“时间”自然就是指系统时间。但我们知道,Flink是一个分布式处理 系统。分布式架构最大的特点,就是节点彼此独立、互不影响,这带来了更高的吞吐量和容错性;但有利必有弊,最大的问题也来源于此。
在分布式系统中,节点“各自为政”,是没有统一时钟的,数据和控制信息都通过网络进行传输。比如现在有一个任务是窗口聚合,我们希望将每个小时的数据收集起来进行统计处理。 而对于并行的窗口子任务,它们所在节点不同,系统时间也会有差异;当我们希望统计8点~9点的数据时,对并行任务来说其实并不是“同时”的,收集到的数据也会有误差。
那既然一个集群中有JobManager作为管理者,是不是让它统一向所有TaskManager发送同步时钟信号就行了呢?这也是不行的。因为网络传输会有延迟,而且这延迟是不确定的,所以JobManager发出的同步信号无法同时到达所有节点;想要拥有一个全局统一的时钟,在分布式系统里是做不到的。
另一个麻烦的问题是,在流式处理的过程中,数据是在不同的节点间不停流动的,这同样也会有网络传输的延迟。这样一来,当上下游任务需要跨节点传输数据时,它们对于“时间” 的理解也会有所不同。例如,上游任务在8点59分59秒发出一条数据,到下游要做窗口计算时已经是9点零1秒了,那这条数据到底该不该被收到8点~9点的窗口呢?所以,当我们希望对数据按照时间窗口来进行收集计算时,“时间”到底以谁为标准就非常重要了。
我们重新梳理一下流式数据处理的过程。如图所示,在事件发生之后,生成的数据被收集起来,首先进入分布式消息队列,然后被Flink系统中的Source算子读取消费,进而向下游的转换算子(窗口算子)传递,最终由窗口算子进行计算处理。

- 很明显,这里有两个非常重要的时间点:一个是数据产生的时间,我们把它叫作“事件时间”(Event Time);另一个是数据真正被处理的时刻,叫作“处理时间”(Processing Time)。 我们所定义的窗口操作,到底是以那种时间作为衡量标准,就是所谓的“时间语义”(Notions of Time)。由于分布式系统中网络传输的延迟和时钟漂移,处理时间相对事件发生的时间会有所滞后。

2.1 处理时间(Processing Time)
- 处理时间的概念非常简单,就是指执行处理操作的机器的系统时间。
- 如果我们以它作为衡量标准,那么数据属于哪个窗口就很明显了:只看窗口任务处理这条数据时,当前的系统时间。比如之前举的例子,数据8点59分59秒产生,而窗口计算时的时间是9点零1秒,那么这条数据就属于9点—10点的窗口;如果数据传输非常快,9点之前就到了窗口任务,那么它就属于8点—9点的窗口了。每个并行的窗口子任务,就只按照自己的系统时钟划分窗口。假如我们在早上8点10分启动运行程序,那么接下来一直到9点以前处理的所有数据,都属于第一个窗口;9点之后、10点之前的所有数据就将属于第二个窗口。
- 这种方法非常简单粗暴,不需要各个节点之间进行协调同步,也不需要考虑数据在流中的 位置,简单来说就是“我的地盘听我的”。所以处理时间是最简单的时间语义。
2.2 事件时间(Event Time)
- 事件时间,是指每个事件在对应的设备上发生的时间,也就是数据生成的时间。
- 数据一旦产生,这个时间自然就确定了,所以它可以作为一个属性嵌入到数据中。这其实就是这条数据记录的“时间戳”(Timestamp)。
- 在事件时间语义下,我们对于时间的衡量,就不看任何机器的系统时间了,而是依赖于数据本身。打个比方,这相当于任务处理的时候自己本身是没有时钟的,所以只好来一个数据就问一下“现在几点了”;而数据本身也没有表,只有一个自带的“出厂时间”,于是任务就基于这 个时间来确定自己的时钟。由于流处理中数据是源源不断产生的,一般来说,先产生的数据也会先被处理,所以当任务不停地接到数据时,它们的时间戳也基本上是不断增长的,就可以代 表时间的推进。
- 当然我们会发现,这里有个前提,就是“先产生的数据先被处理”,这要求我们可以保证数据到达的顺序。但是由于分布式系统中网络传输延迟的不确定性,实际应用中我们要面对的数据流往往是乱序的。在这种情况下,就不能简单地把数据自带的时间戳当作时钟了,而需要用另外的标志来表示事件时间进展,在Flink中把它叫作事件时间的“水位线”(Watermarks)。
3、水位线(Watermark)
3.1 事件时间和窗口
在实际应用中,一般会采用事件时间语义。而水位线,就是基于事件时间提出的概念。所以在介绍水位线之前,我们首先来梳理一下事件时间和窗口的关系。
一个数据产生的时刻,就是流处理中事件触发的时间点,这就是“事件时间”,一般都会以时间戳的形式作为一个字段记录在数据里。这个时间就像商品的“生产日期”一样,一旦产生就是固定的,印在包装袋上,不会因为运输辗转而变化。如果我们想要统计一段时间内的数据,需要划分时间窗口,这时只要判断一下时间戳就可以知道数据属于哪个窗口了。
明确了一个数据的所属窗口,还不能直接进行计算。因为窗口处理的是有界数据,我们需要等窗口的数据都到齐了,才能计算出最终的统计结果。那什么时候数据就都到齐了呢?对于时间窗口来说这很明显:到了窗口的结束时间,自然就应该收集到了所有数据,就可以触发计算输出结果了。比如我们想统计8点~9点的用户点击量,那就是从8点开始收集数据,到9点截止,将收集的数据做处理计算。这有点类似于班车,如图所示,每小时发一班,那么8点之后来的人都会上同一班车,到9点钟准时发车;9点之后来的人,就只好等下一班10点发的车了。
在处理时间语义下,都是以当前任务所在节点的系统时间为准的。这就相当于每辆车里都挂了一个钟,司机看到到了9点就直接发车。这种方式简单粗暴容易实现,但因为车上的钟是独立运行的,以它为标准就不能准确地判断商品的生产时间。在分布式环境下,这样会因为网络传输延迟的不确定而导致误差。比如有些商品在8点59分59秒生产出来,可是从下生产线到运至车上又要花费几秒,那就赶不上9点钟这班车了。而且现在分布式系统中有很多辆9点发的班车,所以同时生产出的一批商品,需要平均分配到不同班车上,可这些班车距离有近有远、上面挂的钟有快有慢,这就可能导致有些商品上车了、有些却被漏掉;先后生产出的商品,到达车上的顺序也可能乱掉:统计结果的正确性受到了影响。
所以在实际中我们往往需要以事件时间为准。如果考虑事件时间,情况就复杂起来了。现在不能直接用每辆车上挂的钟(系统时间),又没有统一的时钟,那该怎么确定发车时间呢?
现在能利用的,就只有商品的生产时间(数据的时间戳)了。我们可以这样思考:一般情况下,商品生产出来之后,就会立即传送到车上;所以商品到达车上的时间(系统时间)应该稍稍滞后于商品的生产时间(数据时间戳)。如果不考虑传输过程的一点点延迟,我们就可以 直接用商品生产时间来表示当前车上的时间了。如图所示,到达车上的商品,生产时间是8点05分,那么当前车上的时间就是8点05分;又来了一个8点10分生产的商品,现在车上的时间就是8点10分。我们直接用数据的时间戳来指示当前的时间进展,窗口的关闭自然也是以数据的时间戳等于窗口结束时间为准,这就相当于可以不受网络传输延迟的影响了。像之前所说8点59分59秒生产出来的商品,到车上的时候不管实际时间(系统时间)是几点,我们就认为当前是8点59分59秒,所以它总是能赶上车的;而9点这班车,要等到9点整生产的商品到来,才认为时间到了9点,这时才正式发车。这样就可以得到正确的统计结果了。

- 在这个处理过程中,我们其实是基于数据的时间戳,自定义了一个“逻辑时钟”。这个时钟的时间不会自动流逝;它的时间进展,就是靠着新到数据的时间戳来推动的。这样的好处在于,计算的过程可以完全不依赖处理时间(系统时间),不论什么时候进行统计处理,得到的结果都是正确的。比如双十一的时候系统处理压力大,我们可能会把大量数据缓存在Kafka中;过了高峰时段之后再读取出来,在几秒之内就可以处理完几个小时甚至几天的数据,而且依然可以按照数据产生的时间段进行统计,所有窗口都能收集到正确的数据。而一般实时流处理的场景中,事件时间可以基本与处理时间保持同步,只是略微有一点延迟,同时保证了窗口 计算的正确性。

3.2 什么是水位线
在事件时间语义下,我们不依赖系统时间,而是基于数据自带的时间戳去定义了一个时钟,用来表示当前时间的进展。于是每个并行子任务都会有一个自己的逻辑时钟,它的前进是靠数据的时间戳来驱动的。
但在分布式系统中,这种驱动方式又会有一些问题。因为数据本身在处理转换的过程中会变化,如果遇到窗口聚合这样的操作,其实是要攒一批数据才会输出一个结果,那么下游的数据就会变少,时间进度的控制就不够精细了。另外,数据向下游任务传递时,一般只能传输给一个子任务(除广播外),这样其他的并行子任务的时钟就无法推进了。例如一个时间戳为9点整的数据到来,当前任务的时钟就已经是9点了;处理完当前数据要发送到下游,如果下游任务是一个窗口计算,并行度为3,那么接收到这个数据的子任务,时钟也会进展到9点,9点结束的窗口就可以关闭进行计算了;而另外两个并行子任务则时间没有变化,不能进行窗口计算。
所以我们应该把时钟也以数据的形式传递出去,告诉下游任务当前时间的进展;而且这个时钟的传递不会因为窗口聚合之类的运算而停滞。一种简单的想法是,在数据流中加入一个时钟标记,记录当前的事件时间;这个标记可以直接广播到下游,当下游任务收到这个标记,就可以更新自己的时钟了。由于类似于水流中用来做标志的记号,在Flink中,这种用来衡量事件时间(Event Time)进展的标记,就被称作“水位线”(Watermark)。
具体实现上,水位线可以看作一条特殊的数据记录,它是插入到数据流中的一个标记点, 主要内容就是一个时间戳,用来指示当前的事件时间。而它插入流中的位置,就应该是在某个数据到来之后;这样就可以从这个数据中提取时间戳,作为当前水位线的时间戳了。
如图所示,每个事件产生的数据,都包含了一个时间戳,我们直接用一个整数表示。 这里没有指定单位,可以理解为秒或者毫秒(方便起见,下面讲述统一认为是秒)。当产生于2秒的数据到来之后,当前的事件时间就是2秒;在后面插入一个时间戳也为2秒的水位线, 随着数据一起向下游流动。而当5秒产生的数据到来之后,同样在后面插入一个水位线,时间戳也为 5,当前的时钟就推进到了5秒。这样,如果出现下游有多个并行子任务的情形,我们只要将水位线广播出去,就可以通知到所有下游任务当前的时间进度了。


3.2.1 有序流中的水位线
在理想状态下,数据应该按照它们生成的先后顺序、排好队进入流中;也就是说,它们处理的过程会保持原先的顺序不变,遵守先来后到的原则。这样的话我们从每个数据中提取时间戳,就可以保证总是从小到大增长的,从而插入的水位线也会不断增长、事件时钟不断向前推进。
实际应用中,如果当前数据量非常大,可能会有很多数据的时间戳是相同的,这时每来一条数据就提取时间戳、插入水位线就做了大量的无用功。而且即使时间戳不同,同时涌来的数据时间差会非常小(比如几毫秒),往往对处理计算也没什么影响。所以为了提高效率,一般会每隔一段时间生成一个水位线,这个水位线的时间戳,就是当前最新数据的时间戳,如图所示。所以这时的水位线,其实就是有序流中的一个周期性出现的时间标记。

- 这里需要注意的是,水位线插入的“周期”,本身也是一个时间概念。在当前事件时间语义下,假如我们设定了每隔100ms生成一次水位线,那就是要等事件时钟推进100ms才能插 入;但是事件时钟本身的进展,本身就是靠水位线来表示的——现在要插入一个水位线,可前提又是水位线要向前推进100ms,这就陷入了死循环。所以对于水位线的周期性生成,周期时间是指处理时间(系统时间),而不是事件时间。

3.2.2 乱序流中的水位线
有序流的处理非常简单,看起来水位线也并没有起到太大的作用。但这种情况只存在于理想状态下。我们知道在分布式系统中,数据在节点间传输,会因为网络传输延迟的不确定性, 导致顺序发生改变,这就是所谓的“乱序数据”。
这里所说的“乱序”(out-of-order),是指数据的先后顺序不一致,主要就是基于数据的产生时间而言的。如图所示,一个7秒时产生的数据,生成时间自然要比9秒的数据早;但是经过数据缓存和传输之后,处理任务可能先收到了9秒的数据,之后7秒的数据才姗姗来迟。 这时如果我们希望插入水位线,来指示当前的事件时间进展,又该怎么做呢?

解决思路也很简单:我们插入新的水位线时,要先判断一下时间戳是否比之前的大,否则就不再生成新的水位线,如图所示。也就是说,只有数据的时间戳比当前时钟大,才能推动时钟前进,这时才插入水位线。

如果考虑到大量数据同时到来的处理效率,我们同样可以周期性地生成水位线。这时只需要保存一下之前所有数据中的最大时间戳,需要插入水位线时,就直接以它作为时间戳生成新的水位线,如图所示。

这样做尽管可以定义出一个事件时钟,却也会带来一个非常大的问题:我们无法正确处理 “迟到”的数据。为了让窗口能够正确收集到迟到的数据,我们也可以等上2秒;也就是用当前已有数据的最大时间戳减去2秒,就是要插入的水位线的时间戳,如图所示。这样的话,9秒的数据到来之后,事件时钟不会直接推进到9秒,而是进展到了7秒;必须等到11秒的数据到来之后,事件时钟才会进展到9秒,这时迟到数据也都已收集齐,0~9秒的窗口就可以正确计算结果了。

如果仔细观察就会看到,这种“等2秒”的策略其实并不能处理所有的乱序数据。比如22秒的数据到来之后,插入的水位线时间戳为20,也就是当前时钟已经推进到了20秒;对于10
20秒的窗口,这时就该关闭了。但是之后又会有17秒的迟到数据到来,它本来应该属于1020秒窗口,现在却被遗漏丢弃了。那又该怎么办呢?既然现在等2秒还是等不到17秒产生的迟到数据,那自然我们可以试着多等几秒,也就是把时钟调得更慢一些。最终的目的,就是要让窗口能够把所有迟到数据都收进来,得到正确的计算结果。对应到水位线上,其实就是要保证,当前时间已经进展到了这个时间戳,在这之后不可能再有迟到数据来了。
如图所示,第一个水位线时间戳为7,它表示当前事件时间是7秒,7秒之前的数据都已经到齐,之后再也不会有了;同样,第二个、第三个水位线时间戳分别为12和20,表示11秒、20秒之前的数据都已经到齐,如果有对应的窗口就可以直接关闭了,统计的结果一定是正确的。这里由于水位线是周期性生成的,所以插入的位置不一定是在时间戳最大的数据后面。

另外需要注意的是,这里一个窗口所收集的数据,并不是之前所有已经到达的数据。因为数据属于哪个窗口,是由数据本身的时间戳决定的,一个窗口只会收集真正属于它的那些数据。 也就是说,上图中尽管水位线W(20)之前有时间戳为22的数据到来,10~20秒的窗口中也不会收集这个数据,进行计算依然可以得到正确的结果。





3.2.3 水位线的特性
- 现在我们可以知道,水位线就代表了当前的事件时间时钟,而且可以在数据的时间戳基础上加一些延迟来保证不丢数据,这一点对于乱序流的正确处理非常重要。
- 我们可以总结一下水位线的特性:
- 水位线是插入到数据流中的一个标记,可以认为是一个特殊的数据。
- 水位线主要的内容是一个时间戳,用来表示当前事件时间的进展。
- 水位线是基于数据的时间戳生成的。
- 水位线的时间戳必须单调递增,以确保任务的事件时间时钟一直向前推进。
- 水位线可以通过设置延迟,来保证正确处理乱序数据。
- 一个水位线Watermark(t),表示在当前流中事件时间已经达到了时间戳t, 这代表t之前的所有数据都到齐了,之后流中不会出现时间戳t’ ≤ t的数据。
- 水位线是Flink流处理中保证结果正确性的核心机制,它往往会跟窗口一起配合,完成对乱序数据的正确处理。
3.3 如何生成水位线
- 水位线是用来保证窗口处理结果的正确性的,如果不能正确处理所有乱序数据,可以尝试调大延迟的时间。那在实际应用中,到底应该怎样生成水位线呢?
3.3.1 生成水位线的总体原则
- 如果我们希望计算结果能更加准确,那可以将水位线的延迟设置得更高一些,等待的时间越长,自然也就越不容易漏掉数据。不过这样做的代价是处理的实时性降低了,我们可能为极少数的迟到数据增加了很多不必要的延迟。
- 如果我们希望处理得更快、实时性更强,那么可以将水位线延迟设得低一些。这种情况下, 可能很多迟到数据会在水位线之后才到达,就会导致窗口遗漏数据,计算结果不准确。对于这 些 “漏网之鱼”,Flink另外提供了窗口处理迟到数据的方法,我们会在后面介绍。当然,如果我们对准确性完全不考虑、一味地追求处理速度,可以直接使用处理时间语义,这在理论上可以得到最低的延迟。
- 所以Flink中的水位线,其实是流处理中对低延迟和结果正确性的一个权衡机制,而且把控制的权力交给了程序员,我们可以在代码中定义水位线的生成策略。接下来我们就具体了解一下水位线在代码中的使用。
3.3.2 水位线生成策略(Watermark Strategies)
在Flink的DataStream API中,有一个单独用于生成水位线的方法:assignTimestampsAndWatermarks(),它主要用来为流中的数据分配时间戳,并生成水位线来指示事件时间:
1
2public SingleOutputStreamOperator<T> assignTimestampsAndWatermarks(
WatermarkStrategy<T> watermarkStrategy)具体使用时,直接用DataStream调用该方法即可,与普通的transform方法完全一样。
1
2
3DataStream<Event> stream = env.addSource(new ClickSource());
DataStream<Event> withTimestampsAndWatermarks =
stream.assignTimestampsAndWatermarks(<watermark strategy>);这里可能有疑惑:不是说数据里已经有时间戳了吗,为什么这里还要“分配”呢?这是因为原始的时间戳只是写入日志数据的一个字段,如果不提取出来并明确把它分配给数据, Flink是无法知道数据真正产生的时间的。当然,有些时候数据源本身就提供了时间戳信息, 比如读取Kafka时,我们就可以从Kafka数据中直接获取时间戳,而不需要单独提取字段分配了。
.assignTimestampsAndWatermarks()方法需要传入一个WatermarkStrategy作为参数,这就 是所谓的“水位线生成策略”。WatermarkStrategy中包含了一个“时间戳分配器”TimestampAssigner和一个“水位线生成器”WatermarkGenerator。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23public interface WatermarkStrategy<T>
extends TimestampAssignerSupplier<T>, WatermarkGeneratorSupplier<T> {
// ------------------------------------------------------------------------
// Methods that implementors need to implement.
// ------------------------------------------------------------------------
/** Instantiates a WatermarkGenerator that generates watermarks according to this strategy. */
WatermarkGenerator<T> createWatermarkGenerator(WatermarkGeneratorSupplier.Context context);
/**
* Instantiates a {@link TimestampAssigner} for assigning timestamps according to this strategy.
*/
default TimestampAssigner<T> createTimestampAssigner(
TimestampAssignerSupplier.Context context) {
// By default, this is {@link RecordTimestampAssigner},
// for cases where records come out of a source with valid timestamps, for example from
// Kafka.
return new RecordTimestampAssigner<>();
}
}TimestampAssigner:主要负责从流中数据元素的某个字段中提取时间戳,并分配给元素。时间戳的分配是生成水位线的基础。
WatermarkGenerator:主要负责按照既定的方式,基于时间戳生成水位线。在WatermarkGenerator接口中,主要又有两个方法:onEvent()和onPeriodicEmit()。
onEvent:每个事件(数据)到来都会调用的方法,它的参数有当前事件、时间戳, 以及允许发出水位线的一个WatermarkOutput,可以基于事件做各种操作。
onPeriodicEmit:周期性调用的方法,可以由WatermarkOutput发出水位线。周期时间为处理时间,可以调用环境配置的.setAutoWatermarkInterval()方法来设置,默认为200ms。
1
env.getConfig().setAutoWatermarkInterval(60 * 1000L);
3.3.3 Flink内置水位线生成器
WatermarkStrategy这个接口是一个生成水位线策略的抽象,让我们可以灵活地实现自己的需求;但看起来有些复杂,如果想要自己实现应该还是比较麻烦的。好在Flink充分考虑到了我们的痛苦,提供了内置的水位线生成器(WatermarkGenerator),不仅开箱即用简化了编程, 而且也为我们自定义水位线策略提供了模板。
这两个生成器可以通过调用WatermarkStrategy的静态辅助方法来创建。它们都是周期性生成水位线的,分别对应着处理有序流和乱序流的场景。
有序流。
对于有序流,主要特点就是时间戳单调增长(Monotonously Increasing Timestamps),所以永远不会出现迟到数据的问题。这是周期性生成水位线的最简单的场景,直接调用WatermarkStrategy.forMonotonousTimestamps()方法就可以实现。简单来说,就是直接拿当前最大的时间戳作为水位线就可以了。
1
2
3
4
5
6
7
8stream.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<Event>(){
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
}
));上面代码中我们调用.withTimestampAssigner()方法,将数据中的timestamp字段提取出来, 作为时间戳分配给数据元素;然后用内置的有序流水位线生成器构造出了生成策略。这样,提取出的数据时间戳,就是我们处理计算的事件时间。这里需要注意的是,时间戳和水位线的单位,必须都是毫秒。
乱序流。
由于乱序流中需要等待迟到数据到齐,所以必须设置一个固定量的延迟时间(Fixed Amount of Lateness)。这时生成水位线的时间戳,就是当前数据流中最大的时间戳减去延迟的结果,相当于把表调慢,当前时钟会滞后于数据的最大时间戳。调用 WatermarkStrategy.forBoundedOutOfOrderness()方法就可以实现。这个方法需要传入一个maxOutOfOrderness参数,表示“最大乱序程度”,它表示数据流中乱序数据时间戳的最大差值;如果我们能确定乱序程度,那么设置对应时间长度的延迟,就可以等到所有的乱序数据了。代码示例如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20public class WatermarkTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.addSource(new ClickSource())
// 插入水位线的逻辑
.assignTimestampsAndWatermarks(
// 针对乱序流插入水位线,延迟时间设置为 5s
WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ofSeconds(5))
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
// 抽取时间戳的逻辑
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
})
).print();
env.execute();
}
}上面代码中,我们同样提取了timestamp字段作为时间戳,并且以5秒的延迟时间创建了处理乱序流的水位线生成器。事实上,有序流的水位线生成器本质上和乱序流是一样的,相当于延迟设为0的乱序流水位线生成器,两者完全等同:
1
2
3WatermarkStrategy.forMonotonousTimestamps()
WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(0))这里需要注意的是,乱序流中生成的水位线真正的时间戳,其实是当前最大时间戳 – 延迟时间 – 1,这里的单位是毫秒。为什么要减1毫秒呢?我们可以回想一下水位线的特点:时间戳为t的水位线,表示时间戳≤t的数据全部到齐,不会再来了。如果考虑有序流,也就是延迟时间为0的情况,那么时间戳为7秒的数据到来时,之后其实是还有可能继续来7秒的数据的;所以生成的水位线不是7秒,而是6秒999毫秒,7秒的数据还可以继续来。这一点可以在BoundedOutOfOrdernessWatermarks的源码中明显地看到:
1
2
3
4
public void onPeriodicEmit(WatermarkOutput output) {
output.emitWatermark(new Watermark(maxTimestamp - outOfOrdernessMillis - 1));
}
3.3.4 自定义水位线策略
在WatermarkStrategy中,时间戳分配器TimestampAssigner都是大同小异的,指定字段提取时间戳就可以了;而不同策略的关键就在于WatermarkGenerator的实现。整体说来,Flink有两种不同的生成水位线的方式:一种是周期性的(Periodic),另一种是断点式的(Punctuated)。
还记得WatermarkGenerator接口中的两个方法吗?——onEvent()和onPeriodicEmit(),前者是在每个事件到来时调用,而后者由框架周期性调用。周期性调用的方法中发出水位线,自然就是周期性生成水位线;而在事件触发的方法中发出水位线,自然就是断点式生成了。两种方式的不同就集中体现在这两个方法的实现上。
周期性水位线生成器(Periodic Generator)。周期性生成器一般是通过onEvent()观察判断输入的事件,而在onPeriodicEmit()里发出水位线。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48public class CustomWatermarkTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.addSource(new ClickSource())
.assignTimestampsAndWatermarks(new CustomWatermarkStrategy())
.print();
env.execute();
}
public static class CustomWatermarkStrategy implements WatermarkStrategy<Event> {
public WatermarkGenerator<Event> createWatermarkGenerator(WatermarkGeneratorSupplier.Context context) {
return new CustomPeriodicGenerator();
}
public TimestampAssigner<Event> createTimestampAssigner(TimestampAssignerSupplier.Context context) {
return new SerializableTimestampAssigner<Event>() {
public long extractTimestamp(Event element, long recordTimestamp) {
// 告诉程序数据源里的时间戳是哪一个字段
return element.timestamp;
}
};
}
}
public static class CustomPeriodicGenerator implements WatermarkGenerator<Event> {
private Long delayTime = 5000L; // 延迟时间
private Long maxTs = Long.MIN_VALUE + delayTime + 1L; // 观察到的最大时间戳
public void onEvent(Event event, long eventTimestamp, WatermarkOutput output) {
// 每来一条数据就调用一次
maxTs = Math.max(event.timestamp, maxTs); // 更新最大时间戳
}
public void onPeriodicEmit(WatermarkOutput output) {
// 发射水位线,默认 200ms 调用一次
output.emitWatermark(new Watermark(maxTs - delayTime - 1L));
}
}
}- 我们在onPeriodicEmit()里调用output.emitWatermark(),就可以发出水位线了;这个方法由系统框架周期性地调用,默认200ms一次。所以水位线的时间戳是依赖当前已有数据的最大时间戳的(这里的实现与内置生成器类似,也是减去延迟时间再减1),但具体什么时候生成与数据无关。
断点式水位线生成器(Punctuated Generator)。断点式生成器会不停地检测onEvent()中的事件,当发现带有水位线信息的特殊事件时,就立即发出水位线。一般来说,断点式生成器不会通过onPeriodicEmit()发出水位线。自定义的断点式水位线生成器代码如下:
1
2
3
4
5
6
7
8
9
10
11
12public class CustomPunctuatedGenerator implements WatermarkGenerator<Event> {
public void onEvent(Event r, long eventTimestamp, WatermarkOutput output) {
// 只有在遇到特定的 itemId 时,才发出水位线 if (r.user.equals("Mary")) {
output.emitWatermark(new Watermark(r.timestamp - 1));
}
public void onPeriodicEmit(WatermarkOutput output) {
// 不需要做任何事情,因为我们在 onEvent 方法中发射了水位线
}
}- 我们在onEvent()中判断当前事件的user字段,只有遇到“Mary”这个特殊的值时,才调用output.emitWatermark()发出水位线。这个过程是完全依靠事件来触发的,所以水位线的生成一定在某个数据到来之后。
3.3.5 在自定义数据源中发送水位线
我们也可以在自定义的数据源中抽取事件时间,然后发送水位线。这里要注意的是,在自定义数据源中发送了水位线以后,就不能再在程序中使用assignTimestampsAndWatermarks方法来生成水位线了。在自定义数据源中生成水位线和在程序中使用assignTimestampsAndWatermarks方法生成水位线二者只能取其一。示例程序如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38public class EmitWatermarkInSourceFunction {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.addSource(new ClickSourceWithWatermark()).print();
env.execute();
}
public static class ClickSourceWithWatermark implements SourceFunction<Event> {
private boolean running = true;
public void run(SourceContext<Event> sourceContext) throws Exception {
Random random = new Random();
String[] userArr = {"Mary", "Bob", "Alice"};
String[] urlArr = {"./home", "./cart", "./prod?id=1"};
while (running) {
long currTs = Calendar.getInstance().getTimeInMillis(); // 毫秒时
String username = userArr[random.nextInt(userArr.length)];
String url = urlArr[random.nextInt(urlArr.length)];
Event event = new Event(username, url, currTs);
// 使用 collectWithTimestamp 方法将数据发送出去,并指明数据中的时间戳的字段
sourceContext.collectWithTimestamp(event, event.timestamp);
// 发送水位线
sourceContext.emitWatermark(new Watermark(event.timestamp - 1L));
Thread.sleep(1000L);
}
}
public void cancel() {
running = false;
}
}
}- 在自定义水位线中生成水位线相比assignTimestampsAndWatermarks 方法更加灵活,可以任意的产生周期性的、非周期性的水位线,以及水位线的大小也完全由我们自定义。所以非常 适合用来编写Flink的测试程序,测试Flink的各种各样的特性。
3.4 水位线的传递
我们知道水位线是数据流中插入的一个标记,用来表示事件时间的进展,它会随着数据一 起在任务间传递。如果只是直通式(forward)的传输,那很简单,数据和水位线都是按照本 身的顺序依次传递、依次处理的;一旦水位线到达了算子任务,那么这个任务就会将它内部的时钟设为这个水位线的时间戳。
在这里,“任务的时钟”其实仍然是各自为政的,并没有统一的时钟。实际应用中往往上下游都有多个并行子任务,为了统一推进事件时间的进展,我们要求上游任务处理完水位线、 时钟改变之后,要把当前的水位线再次发出,广播给所有的下游子任务。这样,后续任务就不 需要依赖原始数据中的时间戳(经过转化处理后,数据可能已经改变了),也可以知道当前事件时间了。
可是还有另外一个问题,那就是在“重分区”(redistributing)的传输模式下,一个任务有可能会收到来自不同分区上游子任务的数据。而不同分区的子任务时钟并不同步,所以同一时刻发给下游任务的水位线可能并不相同。这时下游任务又该听谁的呢?
- 这就要回到水位线定义的本质了:它表示的是“当前时间之前的数据,都已经到齐了”。 这是一种保证,告诉下游任务“只要你接到这个水位线,就代表之后我不会再给你发更早的数据了,你可以放心做统计计算而不会遗漏数据”。所以如果一个任务收到了来自上游并行任务的不同的水位线,说明上游各个分区处理得有快有慢,进度各不相同比如上游有两个并行子任务都发来了水位线,一个是5秒,一个是7秒;这代表第一个并行任务已经处理完5秒之前的所有数据,而第二个并行任务处理到了7秒。我们也要以“这之前的数据全部到齐”为标准,且要以较小的水位线5秒作为当前时间。
我们可以用一个具体的例子,将水位线在任务间传递的过程完整梳理一遍。如图所示,当前任务的上游,有四个并行子任务,所以会接收到来自四个分区的水位线;而下游有三个并行子任务,所以会向三个分区发出水位线。具体过程如下:

- (1)上游并行子任务发来不同的水位线,当前任务会为每一个分区设置一个“分区水位线” (Partition Watermark),这是一个分区时钟;而当前任务自己的时钟,就是所有分区时钟里最小的那个。
- (2)当有一个新的水位线(第一分区的4)从上游传来时,当前任务会首先更新对应的分区时钟;然后再次判断所有分区时钟中的最小值,如果比之前大,说明事件时间有了进展,当前任务的时钟也就可以更新了。这里要注意,更新后的任务时钟,并不一定是新来的那个分区水位线,比如这里改变的是第一分区的时钟,但最小的分区时钟是第三分区的3,于是当前任务时钟就推进到了3。当时钟有进展时,当前任务就会将自己的时钟以水位线的形式,广播给下游所有子任务。
- (3)再次收到新的水位线(第二分区的7)后,执行同样的处理流程。首先将第二个分区时钟更新为7,然后比较所有分区时;发现最小值没有变化,那么当前任务的时钟也不变,也不会向下游任务发出水位线。
- (4)同样道理,当又一次收到新的水位线(第三分区的6)之后,第三个分区时钟更新为6,同时所有分区时钟最小值变成了第一分区的4,所以当前任务的时钟推进到4,并发出时间戳为4的水位线,广播到下游各个分区任务。
水位线在上下游任务之间的传递,非常巧妙地避免了分布式系统中没有统一时钟的问题,每个任务都以“处理完之前所有数据”为标准来确定自己的时钟,就可以保证窗口处理的结果总是正确的。对于有多条流合并之后进行处理的场景,水位线传递的规则是类似的。

4、窗口(Window)
- 我们之前了解的Flink中事件时间和水位线的概念,它们可以做基于时间的处理计算。其中最常见的场景,就是窗口聚合计算。
- 之前我们已经了解了Flink中基本的聚合操作。在流处理中,我们往往需要面对的是连续不断、无休无止的无界流,不可能等到所有所有数据都到齐了才开始处理。所以聚合计算其实只能针对当前已有的数据——之后再有数据到来,就需要继续叠加、再次输出结果。这样似乎很“实时”,但现实中大量数据一般会同时到来,需要并行处理,这样频繁地更新结果就会给系统带来很大负担了。
- 更加高效的做法是,把无界流进行切分,每一段数据分别进行聚合,结果只输出一次。这就相当于将无界流的聚合转化为了有界数据集的聚合,这就是所谓的“窗口”(Window)聚合操作。窗口聚合其实是对实时性和处理效率的一个权衡。在实际应用中,我们往往更关心一段时间内数据的统计结果,比如在过去的1分钟内有多少用户点击了网页。在这种情况下,我们就可以定义一个窗口,收集最近一分钟内的所有用户点击数据,然后进行聚合统计,最终输出一个结果就可以了。
4.1 窗口的概念
Flink是一种流式计算引擎,主要是来处理无界数据流的,数据源源不断、无穷无尽。想要更加方便高效地处理无界流,一种方式就是将无限数据切割成有限的“数据块”进行处理,这就是所谓的“窗口”(Window)。
在Flink中, 窗口就是用来处理无界流的核心。我们很容易把窗口想象成一个固定位置的“框”,数据源源不断地流过来,到某个时间点窗口该关闭了,就停止收集数据、触发计算并输出结果。例如,我们定义一个时间窗口,每10秒统计一次数据,那么就相当于把窗口放在那里,从0秒开始收集数据;到10秒时,处理当前窗口内所有数据,输出一个结果,然后清空窗口继续收集数据;到20秒时,再对窗口内所有数据进行计算处理,输出结果;依次类推,如图所示。

由于有乱序数据,我们需要设置一个延迟时间来等所有数据到齐。比如上面的例子中,我们可以设置延迟时间为2秒,如图所示,这样0~10秒的窗口会在时间戳为12的数据到来之后,才真正关闭计算输出结果,这 样就可以正常包含迟到的9秒数据了。

但是这样一来,0~10秒的窗口不光包含了迟到的9秒数据,连11秒和12秒的数据也包含进去了。我们为了正确处理迟到数据,结果把早到的数据划分到了错误的窗口——最终结果都是错误的。
所以在Flink中,窗口其实并不是一个“框”,流进来的数据被框住了就只能进这一个窗口。相比之下,我们应该把窗口理解成一个“桶”,如图所示。在Flink中,窗口可以把流切割成有限大小的多个“存储桶”(bucket);每个数据都会分发到对应的桶中,当到达窗口结束时间时,就对每个桶中收集的数据进行计算处理。

- (1)第一个数据时间戳为2,判断之后创建第一个窗口[0, 10),并将2秒数据保存进去;
- (2)后续数据依次到来,时间戳均在[0, 10)范围内,所以全部保存进第一个窗口;
- (3)11秒数据到来,判断它不属于[0, 10)窗口,所以创建第二个窗口[10, 20),并将11秒的数据保存进去。由于水位线设置延迟时间为2秒,所以现在的时钟是9秒,第一个窗口也没有到关闭时间;
- (4)之后又有9秒数据到来,同样进入[0, 10)窗口中;
- (5)12秒数据到来,判断属于[10, 20)窗口,保存进去。这时产生的水位线推进到了10秒,所以[0, 10)窗口应该关闭了。第一个窗口收集到了所有的7个数据,进行处理计算后输出结果,并将窗口关闭销毁;
- (6)同样的,之后的数据依次进入第二个窗口,遇到20秒的数据时会创建第三个窗口[20, 30)并将数据保存进去;遇到22秒数据时,水位线达到了20秒,第二个窗口触发计算,输出结果并关闭。
这里需要注意的是,Flink中窗口并不是静态准备好的,而是动态创建——当有落在这个窗口区间范围的数据达到时,才创建对应的窗口。另外,这里我们认为到达窗口结束时间时,窗口就触发计算并关闭,事实上“触发计算”和“窗口关闭”两个行为也可以分开,这部分内容会在后面详述。



4.2 窗口的分类
4.2.1 按照驱动类型分类
窗口本身是截取有界数据的一种方式,所以窗口一个非常重要的信息其实就是“怎样截取数据”。换句话说,就是以什么标准来开始和结束数据的截取,我们把它叫作窗口的“驱动类型”。
我们最容易想到的就是按照时间段去截取数据,这种窗口就叫作“时间窗口”(Time Window)。这在实际应用中最常见,之前所举的例子也都是时间窗口。除了由时间驱动之外, 窗口其实也可以由数据驱动,也就是说按照固定的个数,来截取一段数据集,这种窗口叫作“计数窗口”(Count Window),如图所示。


时间窗口(Time Window)
时间窗口以时间点来定义窗口的开始(start)和结束(end),所以截取出的就是某一时间段的数据。到达结束时间时,窗口不再收集数据,触发计算输出结果,并将窗口关闭销毁。所以可以说基本思路就是“定点发车”。
用结束时间减去开始时间,得到这段时间的长度,就是窗口的大小(window size)。这里的时间可以是不同的语义,所以我们可以定义处理时间窗口和事件时间窗口。
Flink中有一个专门的类来表示时间窗口,名称就叫作TimeWindow。这个类只有两个私有属性:start和end,表示窗口的开始和结束的时间戳,单位为毫秒。
1
2private final long start;
private final long end;我们可以调用公有的getStart()和getEnd()方法直接获取这两个时间戳。另外,TimeWindow还提供了一个maxTimestamp()方法,用来获取窗口中能够包含数据的最大时间戳。
1
2
3public long maxTimestamp() {
return end - 1;
}- 很明显,窗口中的数据,最大允许的时间戳就是end - 1,这也就代表了我们定义的窗口时间范围都是左闭右开的区间[start,end)。
- 这主要是为了方便判断窗口什么时候关闭。对于事件时间语义,窗口的关闭需要水位线推进到窗口的结束时间;而我们知道,水位线Watermark(t)代表的含义是“时间戳小于等于t的数据都已到齐,不会再来了”。为了简化分析,我们先不考虑乱序流设置的延迟时间。那么当新到一个时间戳为t的数据时,当前水位线的时间推进到了t – 1。所以当时间戳为end的数据到来时,水位线推进到了end - 1;如果我们把窗口定义为不包含end,那么当前的水位线刚好就是maxTimestamp,表示窗口能够包含的数据都已经到齐,我们就可以直接关闭窗口了。所以有了这样的定义,我们就不需要再去考虑那烦人的“减一”了,直接看到时间戳为end的数据,就关闭对应的窗口。如果为乱序流设置了水位线延迟时间delay,也只需要等到时间戳为end + delay的数据,就可以关窗了。
计数窗口(Count Window)
计数窗口基于元素的个数来截取数据,到达固定的个数时就触发计算并关闭窗口。这相当于座位有限、“人满就发车”,是否发车与时间无关。每个窗口截取数据的个数,就是窗口的大小。
计数窗口相比时间窗口就更加简单,我们只需指定窗口大小,就可以把数据分配到对应的窗口中了。在Flink内部也并没有对应的类来表示计数窗口,底层是通过“全局窗口”(Global Window)来实现的。
4.2.2 按照窗口分配数据的规则分类
- 时间窗口和计数窗口,只是对窗口的一个大致划分;在具体应用时,还需要定义更加精细的规则,来控制数据应该划分到哪个窗口中去。不同的分配数据的方式,就可以有不同的功能应用。
- 据分配数据的规则,窗口的具体实现可以分为4类:滚动窗口(Tumbling Window)、滑动窗口(Sliding Window)、会话窗口(Session Window),以及全局窗口(Global Window)。 下面我们来做具体介绍。
滚动窗口(Tumbling Windows)
滚动窗口有固定的大小,是一种对数据进行“均匀切片”的划分方式。窗口之间没有重叠,也不会有间隔,是“首尾相接”的状态。我们之前所举的例子都是滚动窗口。也正是因为滚动窗口是“无缝衔接”,所以每个数据都会被分配到一个窗口,而且只会属于一个窗口。
滚动窗口可以基于时间定义,也可以基于数据个数定义;需要的参数只有一个,就是窗口的大小(window size)。比如我们可以定义一个长度为1小时的滚动时间窗口,那么每个小时就会进行一次统计;或者定义一个长度为10的滚动计数窗口,就会每10个数进行一次统计。
如图所示,小圆点表示流中的数据,我们对数据按照userId做了分区。当固定了窗口大小之后,所有分区的窗口划分都是一致的;窗口没有重叠,每个数据只属于一个窗口。


滑动窗口(Sliding Windows)
与滚动窗口类似,滑动窗口的大小也是固定的。区别在于,窗口之间并不是首尾相接的,而是可以“错开”一定的位置。如果看作一个窗口的运动,那么就像是向前小步“滑动”一样。
所以定义滑动窗口的参数有两个:除去窗口大小(window size)之外,还有一个“滑动步长”(window slide),它其实就代表了窗口计算的频率。滑动的距离代表了下个窗口开始的时间间隔,而窗口大小是固定的,所以也就是两个窗口结束时间的间隔;窗口在结束时间触发计算输出结果,那么滑动步长就代表了计算频率。例如,我们定义一个长度为1小时、滑动步长为5分钟的滑动窗口,那么就会统计1小时内的数据,每5分钟统计一次。同样,滑动窗口可以基于时间定义,也可以基于数据个数定义。
我们可以看到,当滑动步长小于窗口大小时,滑动窗口就会出现重叠,这时数据也可能会被同时分配到多个窗口中。而具体的个数,就由窗口大小和滑动步长的比值(size/slide)来决定。如图所示,滑动步长刚好是窗口大小的一半,那么每个数据都会被分配到2个窗口里。比如我们定义的窗口长度为1小时、滑动步长为30分钟,那么对于8点55分的数据,应该同时属于[8点, 9点)和[8点半, 9点半)两个窗口;而对于8点10分的数据,则同时属于[8点, 9点)和[7点半, 8点半)两个窗口。

换句话说,**滚动窗口也可以看作是一种特殊的滑动窗口——窗口大小等于滑动步长(size = slide)**。当然,我们也可以定义滑动步长大于窗口大小,这样的话就会出现窗口不重叠、但会有间隔的情况;这时有些数据不属于任何一个窗口,就会出现遗漏统计。所以一般情况下,我们会让滑动步长小于窗口大小, 并尽量设置为整数倍的关系。

会话窗口(Session Windows)
这里的会话类似Web应用中session的概念,不过并不表示两端的通讯过程,而是借用会话超时失效的机制来描述窗口。简单来说,就是数据来了之后就开启一个会话窗口,如果接下来还有数据陆续到来, 那么就一直保持会话;如果一段时间一直没收到数据,那就认为会话超时失效,窗口自动关闭。
与滑动窗口和滚动窗口不同,会话窗口只能基于时间来定义。对于会话窗口而言,最重要的参数就是这段时间的长度(size),它表示会话的超时时间,也就是两个会话窗口之间的最小距离。如果相邻两个数据到来的时间间隔(Gap)小于指定的大小(size),那说明还在保持会话,它们就属于同一个窗口;如果gap大于size,那么新来的数据就应该属于新的会话窗口,而前一个窗口就应该关闭了。在具体实现上,我们可以设置静态固定的大小(size),也可以通过一个自定义的提取器(gap extractor)动态提取最小间隔gap的值。
考虑到事件时间语义下的乱序流,这里又会有一些麻烦。相邻两个数据的时间间隔gap大于指定的 size,我们认为它们属于两个会话窗口,前一个窗口就关闭;可在数据乱序的情况 下,可能会有迟到数据,它的时间戳刚好是在之前的两个数据之间的。所以在Flink底层,对会话窗口的处理会比较特殊:每来一个新的数据,都会创建一个新的会话窗口;然后判断已有窗口之间的距离,如果小于给定的size,就对它们进行合并(merge)操作。在Window算子中,对会话窗口会有单独的处理逻辑。
我们可以看到,与前两种窗口不同,会话窗口的长度不固定,起始和结束时间也是不确定的,各个分区之间窗口没有任何关联。如图 所示,会话窗口之间一定是不会重叠的,而 且会留有至少为size的间隔(session gap)。


全局窗口(Global Windows)
还有一类比较通用的窗口,就是“全局窗口”。这种窗口全局有效,会把相同key的所有数据都分配到同一个窗口中;说直白一点,就跟没分窗口一样。无界流的数据永无止尽,所以这种窗口也没有结束的时候,默认是不会做触发计算的。如果希望它能对数据进行计算处理, 还需要自定义“触发器”(Trigger)。
如图所示,可以看到,全局窗口没有结束的时间点,所以一般在希望做更加灵活的窗口处理时自定义使用。Flink中的计数窗口(Count Window),底层就是用全局窗口实现的。


4.3 窗口API概览
4.3.1 按键分区(Keyed)和非按键分区(Non-Keyed)
- 在定义窗口操作之前,首先需要确定,到底是基于按键分区(Keyed)的数据流KeyedStream来开窗,还是直接在没有按键分区的DataStream上开窗。也就是说,在调用窗口算子之前,是否有keyBy操作。
按键分区窗口(Keyed Windows)
经过按键分区keyBy操作后,数据流会按照key被分为多条逻辑流(logical streams),这就是KeyedStream。基于KeyedStream进行窗口操作时,窗口计算会在多个并行子任务上同时执行。相同key的数据会被发送到同一个并行子任务,而窗口操作会基于每个key进行单独的 处理。所以可以认为,每个key上都定义了一组窗口,各自独立地进行统计计算。
在代码实现上,我们需要先对DataStream调用.keyBy()进行按键分区,然后再调用.window()定义窗口。
1
2stream.keyBy(...)
.window(...)
非按键分区(Non-Keyed Windows)
如果没有进行keyBy,那么原始的DataStream就不会分成多条逻辑流。这时窗口逻辑只能在一个任务(task)上执行,就相当于并行度变成了1。所以在实际应用中一般不推荐使用这种方式。
在代码中,直接基于DataStream调用.windowAll()定义窗口。
1
stream.windowAll(...)
这里需要注意的是,对于非按键分区的窗口操作,手动调大窗口算子的并行度也是无效的, windowAll本身就是一个非并行的操作。
4.3.2 代码中窗口API的调用
有了前置的基础,接下来我们就可以真正在代码中实现一个窗口操作了。简单来说,窗口操作主要有两个部分:窗口分配器(Window Assigners)和窗口函数(Window Functions)。
1
2
3stream.keyBy(<key selector>)
.window(<window assigner>)
.aggregate(<window function>)- 其中.window()方法需要传入一个窗口分配器,它指明了窗口的类型;而后面的.aggregate()方法传入一个窗口函数作为参数,它用来定义窗口具体的处理逻辑。窗口分配器有各种形式, 而窗口函数的调用方法也不只.aggregate()一种。
- 另外,在实际应用中,一般都需要并行执行任务,非按键分区很少用到,所以我们之后都以按键分区窗口为例;如果想要实现非按键分区窗口,只要前面不做keyBy,后面调用.window()时直接换成.windowAll()就可以了。
4.4 窗口分配器(Window Assigners)
- 定义窗口分配器(Window Assigners)是构建窗口算子的第一步,它的作用就是定义数据应该被“分配”到哪个窗口。窗口分配数据的规则,其实就对应着不同的窗口类型。所以可以说,窗口分配器其实就是在指定窗口的类型。
- 窗口分配器最通用的定义方式,就是调用.window()方法。这个方法需要传入一个WindowAssigner作为参数,返回 WindowedStream。如果是非按键分区窗口,那么直接调用.windowAll()方法,同样传入一个WindowAssigner,返回的是 AllWindowedStream。
- 窗口按照驱动类型可以分成时间窗口和计数窗口,而按照具体的分配规则,又有滚动窗口、 滑动窗口、会话窗口、全局窗口四种。除去需要自定义的全局窗口外,其他常用的类型Flink中都给出了内置的分配器实现,我们可以方便地调用实现各种需求。
4.4.1 时间窗口
时间窗口是最常用的窗口类型,又可以细分为滚动、滑动和会话三种。
直接调用.window(),在里面传入对应时间语义下的窗口分配器,不需要专门定义时间语义,默认就是事件时间;如果想用处理时间,那么在这里传入处理时间的窗口分配器就可以了。
滚动处理时间窗口
窗口分配器由类TumblingProcessingTimeWindows提供,需要调用它的静态方法.of()。
1
2
3stream.keyBy(...)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.aggregate(...)这里.of()方法需要传入一个Time类型的参数size,表示滚动窗口的大小,这里创建了一个长度为5秒的滚动窗口。
另外,.of()还有一个重载方法,可以传入两个Time类型的参数:size和offset。第一个参数当然还是窗口大小,第二个参数则表示窗口起始点的偏移量。
滑动处理时间窗口
窗口分配器由类SlidingProcessingTimeWindows提供,同样需要调用它的静态方法.of()。
1
2
3stream.keyBy(...)
.window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.aggregate(...)这里.of()方法需要传入两个Time类型的参数:size和slide,前者表示滑动窗口的大小,后者表示滑动窗口的滑动步长。我们这里创建了一个长度为10秒、滑动步长为5秒的滑动窗口。
滑动窗口同样可以追加第三个参数,用于指定窗口起始点的偏移量,用法与滚动窗口完全一致。
处理时间会话窗口
窗口分配器由类ProcessingTimeSessionWindows提供,需要调用它的静态方法.withGap()或者.withDynamicGap()。
1
2
3stream.keyBy(...)
.window(ProcessingTimeSessionWindows.withGap(Time.seconds(10)))
.aggregate(...)这里.withGap()方法需要传入一个Time类型的参数 size,表示会话的超时时间,也就是最小间隔session gap。我们这里创建了静态会话超时时间为10秒的会话窗口。
1
2
3
4
5
6.window(ProcessingTimeSessionWindows.withDynamicGap(new
SessionWindowTimeGapExtractor<Tuple2<String, Long>>() {
public long extract(Tuple2<String, Long> element) {
// 提取 session gap 值返回, 单位毫秒 return element.f0.length() * 1000;
} }))这里.withDynamicGap()方法需要传入一个SessionWindowTimeGapExtractor作为参数,用来定义session gap的动态提取逻辑。在这里,我们提取了数据元素的第一个字段,用它的长度乘以1000作为会话超时的间隔。
滚动事件时间窗口
窗口分配器由类TumblingEventTimeWindows提供,用法与滚动处理事件窗口完全一致。
1
2
3stream.keyBy(...)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.aggregate(...)这里.of()方法也可以传入第二个参数offset,用于设置窗口起始点的偏移量。
滑动事件时间窗口
窗口分配器由类SlidingEventTimeWindows提供,用法与滑动处理事件窗口完全一致。
1
2
3stream.keyBy(...)
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.aggregate(...)
事件时间会话窗口
窗口分配器由类EventTimeSessionWindows提供,用法与处理事件会话窗口完全一致。
1
2
3stream.keyBy(...)
.window(EventTimeSessionWindows.withGap(Time.seconds(10)))
.aggregate(...)
4.4.2 计数窗口
计数窗口概念非常简单,本身底层是基于全局窗口(Global Window)实现的。Flink为我们提供了非常方便的接口:直接调用.countWindow()方法。根据分配规则的不同,又可以分为滚动计数窗口和滑动计数窗口两类。
滚动计数窗口
滚动计数窗口只需要传入一个长整型的参数 size,表示窗口的大小。下面定义了一个长度为10的滚动计数窗口,当窗口中元素数量达到10的时候,就会触发计算执行并关闭窗口。
1
2stream.keyBy(...)
.countWindow(10)
滑动计数窗口
与滚动计数窗口类似,不过需要在.countWindow()调用时传入两个参数:size和slide,前者表示窗口大小,后者表示滑动步长。下面定义了一个长度为10、滑动步长为3的滑动计数窗口。每个窗口统计10个数据,每隔3个数据就统计输出一次结果。
1
2stream.keyBy(...)
.countWindow(10,3)
4.4.3 全局窗口
全局窗口是计数窗口的底层实现,一般在需要自定义窗口时使用。它的定义同样是直接调用.window(),分配器由GlobalWindows类提供。需要注意使用全局窗口,必须自行定义触发器才能实现窗口计算,否则起不到任何作用。
1
2stream.keyBy(...)
.window(GlobalWindows.create());
4.5 窗口函数(Window Functions)
定义了窗口分配器,我们只是知道了数据属于哪个窗口,可以将数据收集起来了;至于收集起来到底要做什么,其实还完全没有头绪。所以在窗口分配器之后,必须再接上一个定义窗口如何进行计算的操作,这就是所谓的“窗口函数”(window functions)。
经窗口分配器处理之后,数据可以分配到对应的窗口中,而数据流经过转换得到的数据类型是WindowedStream。这个类型并不是 DataStream,所以并不能直接进行其他转换,而必须进一步调用窗口函数,对收集到的数据进行处理计算之后,才能最终再次得到 DataStream,如图所示。
![image-20220914212521239]()
窗口函数定义了要对窗口中收集的数据做的计算操作,根据处理的方式可以分为两类:增量聚合函数和全窗口函数。
4.5.1 增量聚合函数(incremental aggregation functions)
窗口将数据收集起来,最基本的处理操作当然就是进行聚合。窗口对无限流的切分,可以 看作得到了一个有界数据集。如果我们等到所有数据都收集齐,在窗口到了结束时间要输出结果的一瞬间再去进行聚合,显然就不够高效了——这相当于真的在用批处理的思路来做实时流处理。
为了提高实时性,我们可以再次将流处理的思路发扬光大:就像DataStream的简单聚合 一样,每来一条数据就立即进行计算,中间只要保持一个简单的聚合状态就可以了;区别只是在于不立即输出结果,而是要等到窗口结束时间。等到窗口到了结束时间需要输出计算结果的时候,我们只需要拿出之前聚合的状态直接输出,这无疑就大大提高了程序运行的效率和实时性。
典型的增量聚合函数有两个:ReduceFunction和AggregateFunction。
归约函数(ReduceFunction)
窗口函数中也提供了ReduceFunction:只要基于WindowedStream调用.reduce()方法,然后传入ReduceFunction作为参数,就可以指定以归约两个元素的方式去对窗口中数据进行聚合了。这里的ReduceFunction其实与简单聚合时用到的ReduceFunction是同一个函数类接口,所以使用方式也是完全一样的。且中间聚合的状态和输出的结果,都和输入的数据类型是一样的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
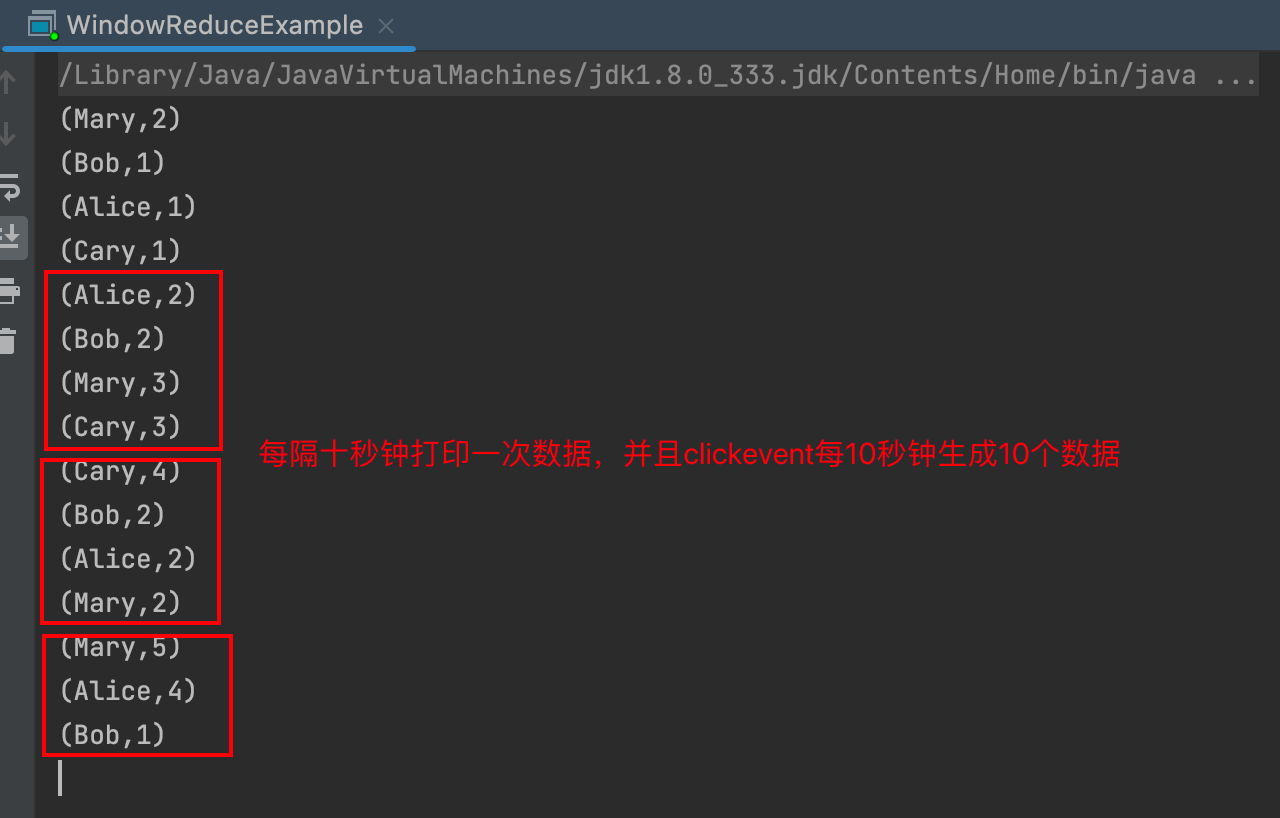
35public class WindowReduceExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 从自定义数据源读取数据,并提取时间戳、生成水位线
SingleOutputStreamOperator<Event> stream = env.addSource(new ClickSource())
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
}));
stream.map(new MapFunction<Event, Tuple2<String, Long>>() {
public Tuple2<String, Long> map(Event value) throws Exception {
// 将数据转换成二元组,方便计算
return Tuple2.of(value.user, 1L);
}
}).keyBy(r -> r.f0)
// 设置滚动事件时间窗口
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.reduce(new ReduceFunction<Tuple2<String, Long>>() {
public Tuple2<String, Long> reduce(Tuple2<String, Long> value1, Tuple2<String, Long> value2)
throws Exception {
// 定义累加规则,窗口闭合时,向下游发送累加结果
return Tuple2.of(value1.f0, value1.f1 + value2.f1);
}
}).print();
env.execute();
}
}![image-20220914215424814]()
聚合函数(AggregateFunction)
ReduceFunction 可以解决大多数归约聚合的问题,但是这个接口有一个限制,就是聚合状态的类型、输出结果的类型都必须和输入数据类型一样。这就迫使我们必须在聚合前,先将数据转换(map)成预期结果类型;而在有些情况下,还需要对状态进行进一步处理才能得到输出结果,这时它们的类型可能不同,使用ReduceFunction就会非常麻烦。
例如,如果我们希望计算一组数据的平均值,应该怎样做聚合呢?很明显,这时我们需要计算两个状态量:数据的总和(sum),以及数据的个数(count),而最终输出结果是两者的商(sum/count)。如果用ReduceFunction,那么我们应该先把数据转换成二元组(sum, count)的形式,然后进行归约聚合,最后再将元组的两个元素相除转换得到最后的平均值。本来应该只是一个任务,可我们却需要map-reduce-map三步操作,这显然不够高效。
Flink的Window API中的aggregate就提供了这样的操作。直接基于WindowedStream调用.aggregate()方法,就可以定义更加灵活的窗口聚合操作。这个方法需要传入一个AggregateFunction的实现类作为参数。AggregateFunction在源码中的定义如下:
1
2
3
4
5
6
7
8
9
10public interface AggregateFunction<IN, ACC, OUT> extends Function, Serializable {
// 创建一个累加器,这就是为聚合创建了一个初始状态,每个聚合任务只会调用一次。
ACC createAccumulator();
// 将输入的元素添加到累加器中。这就是基于聚合状态,对新来的数据进行进一步聚合的过程。方法传入两个参数:当前新到的数据 value,和当前的累加器accumulator;返回一个新的累加器值,也就是对聚合状态进行更新。每条数据到来之后都会调用这个方法。
ACC add(IN value, ACC accumulator);
// 从累加器中提取聚合的输出结果。也就是说,我们可以定义多个状态, 然后再基于这些聚合的状态计算出一个结果进行输出。比如之前我们提到的计算平均值,就可以把sum和count作为状态放入累加器,而在调用这个方法时相除得到最终结果。这个方法只在窗口要输出结果时调用。
OUT getResult(ACC accumulator);
// 合并两个累加器,并将合并后的状态作为一个累加器返回。这个方法只在需要合并窗口的场景下才会被调用;最常见的合并窗口(Merging Window)的场景就是会话窗口(Session Windows)。
ACC merge(ACC a, ACC b);
}AggregateFunction可以看作是ReduceFunction的通用版本,这里有三种类型:输入类型 (IN)、累加器类型(ACC)和输出类型(OUT)。输入类型IN就是输入流中元素的数据类型;累加器类型ACC则是我们进行聚合的中间状态类型;而输出类型当然就是最终计算结果的类型了。
所以可以看到,AggregateFunction的工作原理是:首先调用createAccumulator()为任务初始化一个状态(累加器);而后每来一个数据就调用一次add()方法,对数据进行聚合,得到的结果保存在状态中;等到了窗口需要输出时,再调用getResult()方法得到计算结果。很明显,与ReduceFunction相同,AggregateFunction也是增量式的聚合;而由于输入、中间状态、输 出的类型可以不同,使得应用更加灵活方便。
下面来看一个具体例子。我们知道,在电商网站中,PV(页面浏览量)和UV(独立访客数)是非常重要的两个流量指标。一般来说,PV统计的是所有的点击量;而对用户id进行去重之后,得到的就是UV。所以有时我们会用PV/UV这个比值,来表示“人均重复访问量”, 也就是平均每个用户会访问多少次页面,这在一定程度上代表了用户的粘度。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50public class WindowAggregateFunctionExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 从自定义数据源读取数据,并提取时间戳、生成水位线
SingleOutputStreamOperator<Event> stream = env.addSource(new ClickSource())
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
}));
// 所有数据设置相同的 key,发送到同一个分区统计 PV 和 UV,再相除
stream.keyBy(data -> true)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.aggregate(new AvgPv())
.print();
env.execute();
}
public static class AvgPv implements AggregateFunction<Event, Tuple2<HashSet<String>, Long>, Double> {
public Tuple2<HashSet<String>, Long> createAccumulator() {
// 创建累加器
return Tuple2.of(new HashSet<String>(), 0L);
}
public Tuple2<HashSet<String>, Long> add(Event value, Tuple2<HashSet<String>, Long> accumulator) {
// 属于本窗口的数据来一条累加一次,并返回累加器
accumulator.f0.add(value.user);
return Tuple2.of(accumulator.f0, accumulator.f1 + 1L);
}
public Double getResult(Tuple2<HashSet<String>, Long> accumulator) {
// 窗口闭合时,增量聚合结束,将计算结果发送到下游
return (double) accumulator.f1 / accumulator.f0.size();
}
public Tuple2<HashSet<String>, Long> merge(Tuple2<HashSet<String>, Long> a, Tuple2<HashSet<String>, Long> b) {
// 这里没有涉及会话窗口,所以 merge()方法可以不做任何操作。
return null;
}
}
}另外,Flink 也为窗口的聚合提供了一系列预定义的简单聚合方法,可以直接基于WindowedStream调用。主要包括.sum()/max()/maxBy()/min()/minBy(),与KeyedStream的简单聚合非常相似。它们的底层,其实都是通过AggregateFunction来实现的。
4.5.2 全窗口函数(full window functions)
与增量聚合函数不同,全窗口函数需要先收集窗口中的数据,并在内部缓存起来,等到窗口要输出结果的时候再取出数据进行计算。这是因为有些场景下,我们要做的计算必须基于全部的数据才有效,这时做增量聚合就没什么意义了;另外,输出的结果有可能要包含上下文中的一些信息(比如窗口的起始时间),这是增量聚合函数做不到的。所以,我们还需要有更丰富的窗口计算方式,这就可以用全窗口函数来实现。
在Flink中,全窗口函数也有两种:WindowFunction和ProcessWindowFunction。
窗口函数(WindowFunction)
WindowFunction字面上就是“窗口函数”,它其实是老版本的通用窗口函数接口。我们可以基于WindowedStream调用.apply()方法,传入一个WindowFunction的实现类。
1
2
3
4stream
.keyBy(<key selector>)
.window(<window assigner>)
.apply(new MyWindowFunction());这个类中可以获取到包含窗口所有数据的可迭代集合(Iterable),还可以拿到窗口(Window)本身的信息。WindowFunction 接口在源码中实现如下:
1
2
3public interface WindowFunction<IN, OUT, KEY, W extends Window> extends Function, Serializable {
void apply(KEY key, W window, Iterable<IN> input, Collector<OUT> out) throws Exception;
}当窗口到达结束时间需要触发计算时,就会调用这里的apply方法。我们可以从input集合中取出窗口收集的数据,结合key和window信息,通过收集器(Collector)输出结果。这里Collector的用法,与FlatMapFunction中相同。
不过我们也看到了,WindowFunction能提供的上下文信息较少,也没有更高级的功能。事实上,它的作用可以被ProcessWindowFunction全覆盖,所以之后可能会逐渐弃用。一般在实际应用,直接使用ProcessWindowFunction就可以了。
处理窗口函数(ProcessWindowFunction)
ProcessWindowFunction是Window API中最底层的通用窗口函数接口。之所以说它“最底层”,是因为除了可以拿到窗口中的所有数据之外,ProcessWindowFunction还可以获取到一个“上下文对象”(Context)。这个上下文对象非常强大,不仅能够获取窗口信息,还可以访问当前的时间和状态信息。这里的时间就包括了处理时间(processing time)和事件时间水位线(event time watermark)。这就使得ProcessWindowFunction更加灵活、功能更加丰富。
当然,这些好处是以牺牲性能和资源为代价的。作为一个全窗口函数,ProcessWindowFunction同样需要将所有数据缓存下来、等到窗口触发计算时才使用。它其实就是一个增强版的WindowFunction。具体使用跟WindowFunction非常类似,我们可以基于WindowedStream调用.process()方法,传入一个ProcessWindowFunction的实现类。下面是一个电商网站统计每小时UV的例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42public class UvCountByWindowExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 从自定义数据源读取数据,并提取时间戳、生成水位线
SingleOutputStreamOperator<Event> stream = env.addSource(new ClickSource())
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
}));
// 将数据全部发往同一分区,按窗口统计 UV
stream.keyBy(data -> true)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.process(new UvCountByWindow())
.print();
env.execute();
}
// 自定义窗口处理函数
public static class UvCountByWindow extends ProcessWindowFunction<Event,
String, Boolean, TimeWindow> {
public void process(Boolean aBoolean, Context context, Iterable<Event> elements, Collector<String> out)
throws Exception {
HashSet<String> userSet = new HashSet<>(); // 遍历所有数据,放到 Set 里去重
for (Event event : elements) {
userSet.add(event.user);
}
// 结合窗口信息,包装输出内容
Long start = context.window().getStart();
Long end = context.window().getEnd();
out.collect(" 窗 口 : " + new Timestamp(start) + " ~ " + new Timestamp(end)
+ " 的独立访客数量是:" + userSet.size());
}
}
}
- 这里我们使用的是事件时间语义。定义10秒钟的滚动事件窗口后,直接使用ProcessWindowFunction来定义处理的逻辑。我们可以创建一个HashSet,将窗口所有数据的userId写入实现去重,最终得到HashSet的元素个数就是UV值。
- 当然,这里我们并没有用到上下文中其他信息,所以其实没有必要使用ProcessWindowFunction。全窗口函数因为运行效率较低,很少直接单独使用,往往会和增量聚合函数结合在一起,共同实现窗口的处理计算。

4.5.3 增量聚合和全窗口函数的结合使用
增量聚合函数处理计算会更高效。举一个最简单的例子,对一组数据求和。大量的数据连续不断到来,全窗口函数只是把它们收集缓存起来,并没有处理;到了窗口要关闭、输出结果的时候,再遍历所有数据依次叠加,得到最终结果。而如果我们采用增量聚合的方式,那么只需要保存一个当前和的状态,每个数据到来时就会做一次加法,更新状态;到了要输出结果的时候,只要将当前状态直接拿出来就可以了。增量聚合相当于把计算量“均摊”到了窗口收集数据的过程中,自然就会比全窗口聚合更加高效、输出更加实时。
而全窗口函数的优势在于提供了更多的信息,可以认为是更加“通用”的窗口操作。它只负责收集数据、提供上下文相关信息,把所有的原材料都准备好,至于拿来做什么我们完全可以任意发挥。这就使得窗口计算更加灵活,功能更加强大。
所以在实际应用中,我们往往希望兼具这两者的优点,把它们结合在一起使用。Flink的Window API就给我们实现了这样的用法。
我们之前在调用WindowedStream的.reduce()和.aggregate()方法时,只是简单地直接传入了一个ReduceFunction或AggregateFunction进行增量聚合。除此之外,其实还可以传入第二个参数:一个全窗口函数,可以是WindowFunction或者ProcessWindowFunction。这样调用的处理机制是:基于第一个参数(增量聚合函数)来处理窗口数据,每来一个数据就做一次聚合;等到窗口需要触发计算时,则调用第二个参数(全窗口函数)的处理逻辑输出结果。需要注意的是,这里的全窗口函数就不再缓存所有数据了,而是直接将增量聚合函数的结果拿来当作了Iterable类型的输入。一般情况下,这时的可迭代集合中就只有一个元素了。
下面我们举一个具体的实例来说明。在网站的各种统计指标中,一个很重要的统计指标就是热门的链接;想要得到热门的url,前提是得到每个链接的“热门度”。一般情况下,可以用url的浏览量(点击量)表示热门度。我们这里统计10秒钟的url浏览量,每5秒钟更新一次;另外为了更加清晰地展示,还应该把窗口的起始结束时间一起输出。我们可以定义滑动窗口,并结合增量聚合函数和全窗口函数来得到统计结果。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66public class UrlViewCountExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 从自定义数据源读取数据,并提取时间戳、生成水位线
SingleOutputStreamOperator<Event> stream = env.addSource(new ClickSource())
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
}));
stream.print("input");
// 需要按照 url 分组,开滑动窗口统计
stream.keyBy(data -> data.url)
.window(TumblingEventTimeWindows.of(Time.seconds(10),
Time.seconds(5)))
// 同时传入增量聚合函数和全窗口函数
.aggregate(new UrlViewCountAgg(), new UrlViewCountResult()).print();
env.execute();
}
// 自定义增量聚合函数,来一条数据就加一
public static class UrlViewCountAgg implements AggregateFunction<Event, Long,
Long> {
public Long createAccumulator() {
return 0L;
}
public Long add(Event value, Long accumulator) {
return accumulator + 1;
}
public Long getResult(Long accumulator) {
return accumulator;
}
public Long merge(Long a, Long b) {
return null;
}
}
// 自定义窗口处理函数,只需要包装窗口信息
public static class UrlViewCountResult extends ProcessWindowFunction<Long,
UrlViewCount, String, TimeWindow> {
public void process(String url, Context context, Iterable<Long> elements, Collector<UrlViewCount> out)
throws Exception {
// 结合窗口信息,包装输出内容
Long start = context.window().getStart();
Long end = context.window().getEnd();
// 迭代器中只有一个元素,就是增量聚合函数的计算结果
out.collect(new UrlViewCount(url, elements.iterator().next(), start, end));
}
}
}
- 代码中用一个AggregateFunction来实现增量聚合,每来一个数据就计数加一;得到的结果交给ProcessWindowFunction,结合窗口信息包装成我们想要的UrlViewCount,最终输出统计结果。
- 窗口处理的主体还是增量聚合,而引入全窗口函数又可以获取到更多的信息包装输出,这样的结合兼具了两种窗口函数的优势,在保证处理性能和实时性的同时支持了更加丰富的应用场景。

4.6 其他API
- 对于一个窗口算子而言,窗口分配器和窗口函数是必不可少的。除此之外,Flink还提供了其他一些可选的API,让我们可以更加灵活地控制窗口行为。
4.6.1 触发器(Trigger)
触发器主要是用来控制窗口什么时候触发计算。所谓的“触发计算”,本质上就是执行窗口函数,所以可以认为是计算得到结果并输出的过程。
基于WindowedStream调用.trigger()方法,就可以传入一个自定义的窗口触发器(Trigger)。
1
2
3stream.keyBy(...)
.window(...)
.trigger(new MyTrigger())Trigger是窗口算子的内部属性,每个窗口分配器(WindowAssigner)都会对应一个默认的触发器;对于Flink内置的窗口类型,它们的触发器都已经做了实现。例如,所有事件时间窗口,默认的触发器都是EventTimeTrigger;类似还有ProcessingTimeTrigger和CountTrigger。 所以一般情况下是不需要自定义触发器的,不过我们依然有必要了解它的原理。Trigger是一个抽象类,自定义时必须实现下面四个抽象方法:
- onElement():窗口中每到来一个元素,都会调用这个方法。
- onEventTime():当注册的事件时间定时器触发时,将调用这个方法。
- onProcessingTime():当注册的处理时间定时器触发时,将调用这个方法。
- clear():当窗口关闭销毁时,调用这个方法。一般用来清除自定义的状态。
可以看到,除了clear()比较像生命周期方法,其他三个方法其实都是对某种事件的响应。 onElement()是对流中数据元素到来的响应;而另两个则是对时间的响应。这几个方法的参数中都有一个“触发器上下文”(TriggerContext)对象,可以用来注册定时器回调(callback)。这里提到的“定时器”(Timer),其实就是我们设定的一个“闹钟”,代表未来某个时间点会执行的事件;当时间进展到设定的值时,就会执行定义好的操作。
上面的前三个方法可以响应事件,那它们又是怎样跟窗口操作联系起来的呢?这就需要了解一下它们的返回值。这三个方法返回类型都是TriggerResult,这是一个枚举类型(enum), 其中定义了对窗口进行操作的四种类型。
- CONTINUE(继续):什么都不做。
- FIRE(触发):触发计算,输出结果。
- PURGE(清除):清空窗口中的所有数据,销毁窗口。
- FIRE_AND_PURGE(触发并清除):触发计算输出结果,并清除窗口。
我们可以看到,Trigger除了可以控制触发计算,还可以定义窗口什么时候关闭(销毁)。 上面的四种类型,其实也就是这两个操作交叉配对产生的结果。一般我们会认为,到了窗口的结束时间,那么就会触发计算输出结果,然后关闭窗口——似乎这两个操作应该是同时发生的;但TriggerResult的定义告诉我们,两者可以分开。
4.6.2 移除器(Evictor)
移除器主要用来定义移除某些数据的逻辑。基于WindowedStream调用.evictor()方法,就可以传入一个自定义的移除器(Evictor)。Evictor是一个接口,不同的窗口类型都有各自预实现的移除器。
1
2
3stream.keyBy(...)
.window(...)
.evictor(new MyEvictor())Evictor接口定义了两个方法:
- evictBefore():定义执行窗口函数之前的移除数据操作。
- evictAfter():定义执行窗口函数之后的以处数据操作。
默认情况下,预实现的移除器都是在执行窗口函数(window fucntions)之前移除数据的。
4.6.3 允许延迟(Allowed Lateness)
Flink提供了一个特殊的接口,可以为窗口算子设置一个“允许的最大延迟”(Allowed Lateness)。也就是说,我们可以设定允许延迟一段时间,在这段时间内,窗口不会销毁,继续到来的数据依然可以进入窗口中并触发计算。直到水位线推进到了窗口结束时间 + 延迟时间,才真正将窗口的内容清空,正式关闭窗口。
基于WindowedStream调用.allowedLateness()方法,传入一个Time类型的延迟时间,就可以表示允许这段时间内的延迟数据。
1
2
3stream.keyBy(...)
.window(TumblingEventTimeWindows.of(Time.hours(1)))
.allowedLateness(Time.minutes(1))- 从这里我们就可以看到,窗口的触发计算(Fire)和清除(Purge)操作确实可以分开。不过在默认情况下,允许的延迟是0,这样一旦水位线到达了窗口结束时间就会触发计算并清除窗口,两个操作看起来就是同时发生了。当窗口被清除(关闭)之后,再来的数据就会被丢弃。
4.6.4 将迟到的数据放入侧输出流
我们自然会想到,即使可以设置窗口的延迟时间,终归还是有限的,后续的数据还是会被丢弃。如果不想丢弃任何一个数据,又该怎么做呢?
Flink还提供了另外一种方式处理迟到数据。我们可以将未收入窗口的迟到数据,放入“侧输出流”(side output)进行另外的处理。所谓的侧输出流,相当于是数据流的一个“分支”, 这个流中单独放置那些错过了该上的车、本该被丢弃的数据。
基于WindowedStream调用.sideOutputLateData() 方法,就可以实现这个功能。方法需要传入一个“输出标签”(OutputTag),用来标记分支的迟到数据流。因为保存的就是流中的原始数据,所以OutputTag的类型与流中数据类型相同。
1
2
3
4
5DataStream<Event> stream = env.addSource(...);
OutputTag<Event> outputTag = new OutputTag<Event>("late") {};
stream.keyBy(...)
.window(TumblingEventTimeWindows.of(Time.hours(1)))
.sideOutputLateData(outputTag)将迟到数据放入侧输出流之后,还应该可以将它提取出来。基于窗口处理完成之后的DataStream,调用.getSideOutput()方法,传入对应的输出标签,就可以获取到迟到数据所在的流了。
1
2
3
4
5SingleOutputStreamOperator<AggResult> winAggStream = stream.keyBy(...)
.window(TumblingEventTimeWindows.of(Time.hours(1)))
.sideOutputLateData(outputTag)
.aggregate(new MyAggregateFunction())
DataStream<Event> lateStream = winAggStream.getSideOutput(outputTag);- 这里注意,getSideOutput()是SingleOutputStreamOperator的方法,获取到的侧输出流数据类型应该和OutputTag指定的类型一致,与窗口聚合之后流中的数据类型可以不同。
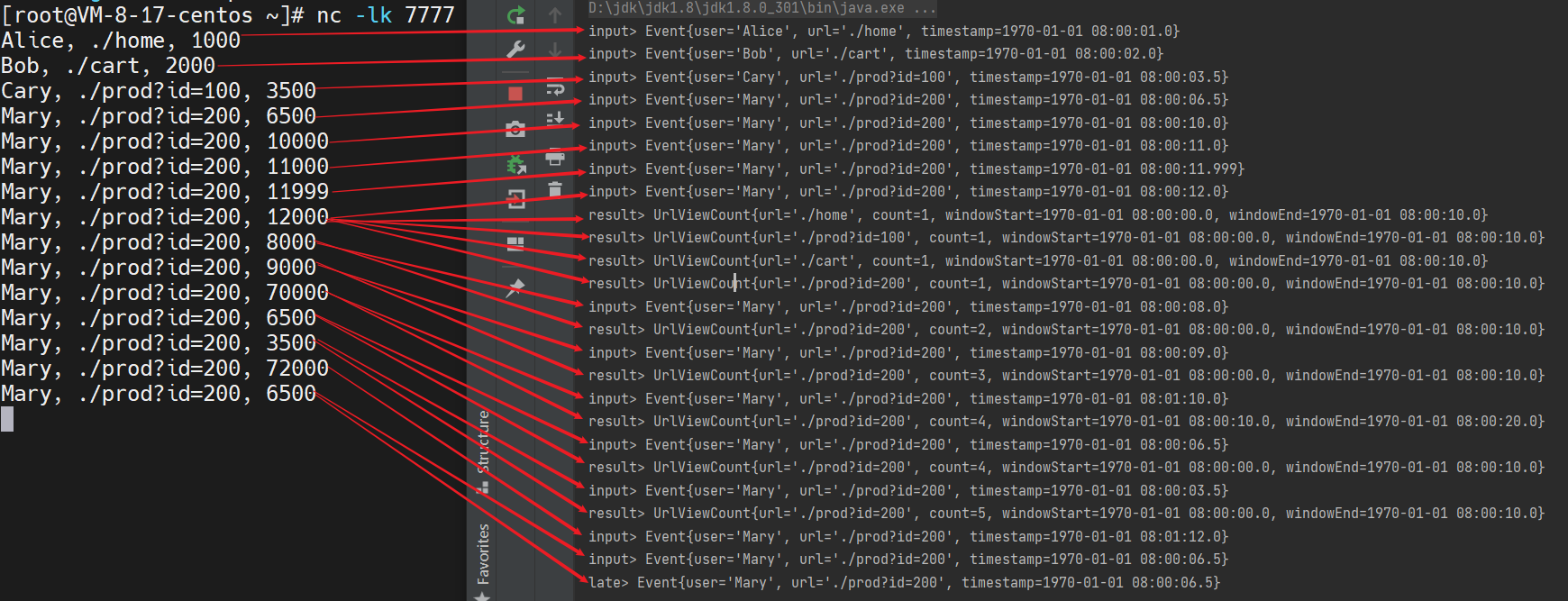
综合测试案例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114public class LateDataTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.getConfig().setAutoWatermarkInterval(100);
// 从自定义数据源读取数据,并提取时间戳、生成水位线
SingleOutputStreamOperator<Event> stream = env.socketTextStream("42.194.164.65", 7777).map(
new MapFunction<String, Event>() {
public Event map(String value) throws Exception {
String[] fields = value.split(",");
return new Event(fields[0].trim(), fields[1].trim(), Long.valueOf(fields[2].trim()));
}
})
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ofSeconds(2))
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
}));
stream.print("input");
// 定义一个输出标签,使用匿名内部类的方式避免泛型擦除
OutputTag<Event> late = new OutputTag<Event>("late"){};
// 需要按照 url 分组,开滑动窗口统计
SingleOutputStreamOperator<UrlViewCount> result = stream.keyBy(data -> data.url)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
// 方式二:允许窗口处理迟到数据,设置 1 分钟的等待时间
.allowedLateness(Time.minutes(1))
// 方式三:将最后的迟到数据输出到侧输出流
.sideOutputLateData(late)
// 同时传入增量聚合函数和全窗口函数
.aggregate(new UrlViewCountAgg(), new UrlViewCountResult());
result.print("result");
result.getSideOutput(late).print("late");
env.execute();
}
// 自定义增量聚合函数,来一条数据就加一
public static class UrlViewCountAgg implements AggregateFunction<Event, Long,
Long> {
public Long createAccumulator() {
return 0L;
}
public Long add(Event value, Long accumulator) {
return accumulator + 1;
}
public Long getResult(Long accumulator) {
return accumulator;
}
public Long merge(Long a, Long b) {
return null;
}
}
// 自定义窗口处理函数,只需要包装窗口信息
public static class UrlViewCountResult extends ProcessWindowFunction<Long,
UrlViewCount, String, TimeWindow> {
public void process(String url, Context context, Iterable<Long> elements, Collector<UrlViewCount> out)
throws Exception {
// 结合窗口信息,包装输出内容
Long start = context.window().getStart();
Long end = context.window().getEnd();
// 迭代器中只有一个元素,就是增量聚合函数的计算结果
out.collect(new UrlViewCount(url, elements.iterator().next(), start, end));
}
}
public static class UrlViewCount {
public String url;
public Long count;
public Long windowStart;
public Long windowEnd;
public UrlViewCount() {
}
public UrlViewCount(String url, Long count, Long windowStart, Long windowEnd) {
this.url = url;
this.count = count;
this.windowStart = windowStart;
this.windowEnd = windowEnd;
}
public String toString() {
return "UrlViewCount{" +
"url='" + url + '\'' +
", count=" + count +
", windowStart=" + new Timestamp(windowStart) +
", windowEnd=" + new Timestamp(windowEnd) +
'}';
}
}
}![]()