LangChain使用之Memory
1、Memory概述
1.1 为什么需要Memory
大多数的大模型应用程序都会有一个会话接口,允许我们进行多轮的对话,并有一定的上下文记忆能力。
但实际上,模型本身是
不会记忆任何上下文的,只能依靠用户本身的输入去产生输出。![image-20251018135526548]()
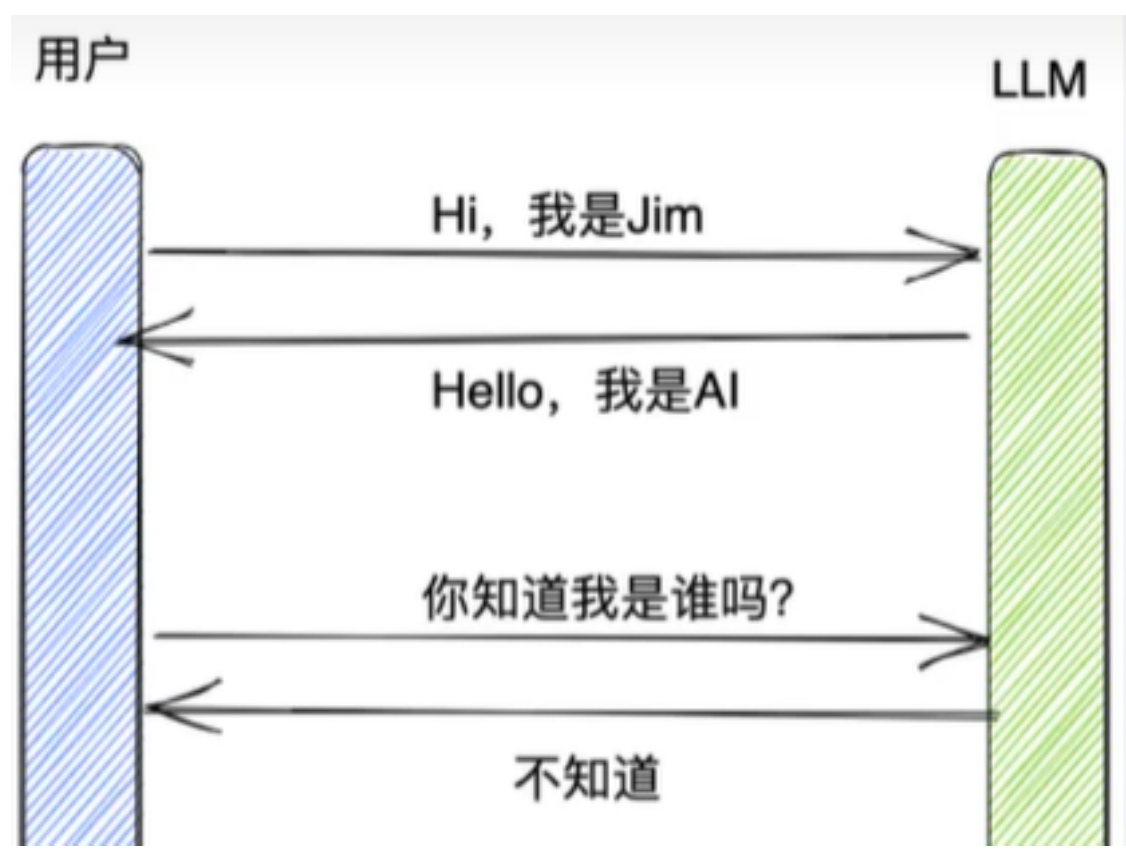
- 如何实现记忆功能呢?
- 实现这个记忆功能,就需要额外的模块去保存我们和模型对话的上下文信息,然后在下一次请求时,把 所有的历史信息都输入给模型,让模型输出最终结果。
- 而在 LangChain 中,提供这个功能的模块就称为Memory(记忆) ,用于存储用户和模型交互的历史信息。
1.2 什么是Memory
- Memory,是LangChain中用于多轮对话中保存和管理上下文信息(比如文本、图像、音频等)的组 件。它让应用能够记住用户之前说了什么,从而实现对话的上下文感知能力 ,为构建真正智能和上下文 感知的链式对话系统提供了基础。
1.3 Memory的设计理念

输入问题:({“question”: …})
读取历史消息:从Memory中READ历史消息({“past_messages”: […]})
构建提示(Prompt):读取到的历史消息和当前问题会被合并,构建一个新的Prompt
模型处理:构建好的提示会被传递给语言模型进行处理。语言模型根据提示生成一个输出。
解析输出:输出解析器通过正则表达式 regex(“Answer: (.*)”)来解析,返回一个回答({“answer”: …})给用户
得到回复并写入Memory:新生成的回答会与当前的问题一起写入Memory,更新对话历史。Memory会存储最新的对话内容,为后续的对话提供上下文支持。
- 问题:一个链如果接入了模块,其会与Memory模块交互几次呢?
- 链内部会与模块进行两次交互:读取和写入
- 收到用户输入时,从记忆组件中查询相关历史信息,拼接历史信息和用户的输入到提示词中传给LLM。
- 返回响应之前,自动把LLM返回的内容写入到记忆组件,用于下次查询。
- 链内部会与模块进行两次交互:读取和写入
1.4 不使用Memory模块,如何拥有记忆
不借助LangChain情况下,我们如何实现大模型的记忆能力?
思考:通过
messages变量,不断地将历史的对话信息追加到对话列表中,以此让大模型具备上下文记
忆能力。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32from langchain_core.messages import HumanMessage
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.messages.ai import AIMessage
def chat_with_model(answer):
# 2、提供提示词模板:ChatPromptTemplate
prompt_template = ChatPromptTemplate.from_messages([
("system", "你是一个人工智能的助手"),
("human", "{question}")
])
while True:
# 3、获取chain,并调用大模型得到响应
chain = prompt_template | llm
response = chain.invoke({"question": answer})
# 4、输出大模型的响应
print(f"模型回复:{response.content}")
# 5、继续获取用户的问题
user_input = input("你还有其他问题吗?(输入'退出'时,结束会话)")
# 6、指明退出循环的方式
if (user_input == "退出"):
break
# 7、将上述新生成的消息存放到提示词模板的消息列表中
prompt_template.messages.append(AIMessage(content=response.content))
prompt_template.messages.append(HumanMessage(content=user_input))
chat_with_model("你好,很高兴认识你!")
2、基础Memory模块的使用
2.1 Memory模块的设计思路
如何设计Memory模块?
- 层次1(最直接的方式):保留一个聊天消息列表
- 层次2(简单的新思路):只返回最近交互的k条消息
- 层次3(稍微复杂一点):返回过去k条消息的简洁摘要
- 层次4(更复杂):从存储的消息中提取实体,并且仅返回有关当前运行中引用的实体的信息
LangChain的设计:针对上述情况,LangChain构建了一些可以直接使用的Memory工具,用于存储聊天消息的一系列集成。


2.2 ChatMessageHistory(基础)
- ChatMessageHistory是一个用于存储和管理对话消息的基础类,它直接操作消息对象(如HumanMessage, AIMessage等),是其它记忆组件的底层存储工具。
- 在API文档中,ChatMessageHistory还有一个别名类:InMemoryChatMessageHistory;导包时,需使用:from langchain.memory import ChatMessageHistory
- 特点:
- 不涉及消息的格式化(如转成文本字符串)
- 纯粹是消息对象的“
存储器”,与记忆策略(如缓冲、窗口、摘要等)无关。
2.2.1 场景1:记忆存储
ChatMessageHistory是用于管理和存储对话历史的具体实现。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16from langchain.memory import ChatMessageHistory
from langchain_core.prompts import PromptTemplate
# 1、ChatMessageHistory的实例化
history = ChatMessageHistory()
# 2、添加相关的消息进行存储
history.add_user_message("你好")
history.add_ai_message("很高兴认识你")
# 3、打印存储的消息
print(history.messages)
# [HumanMessage(content='你好', additional_kwargs={}, response_metadata={}), AIMessage(content='很高兴认识你', additional_kwargs={}, response_metadata={})]
2.2.2 场景2:对接LLM
1 | # 1、获取大模型 |
1 | from langchain.memory import ChatMessageHistory |
2.3 ConversationBufferMemory
ConversationBufferMemory是一个基础的
对话记忆(Memory)组件,专门用于按原始顺序存储完整的对话历史。它的核心特点是简单、无裁剪、无压缩,适用于需要完整上下文的小规模对话场景。适用场景:对话轮次较少、依赖完整上下文的场景(如简单的聊天机器)
特点:
- 完整存储对话历史。
- 适合对话轮次较少、依赖完整上下文的场景(如简单的聊天机器)
- **与 Chains/Models **无缝集成
- 支持两种返回格式(通过
return_messages参数控制输出格式)- **
return_messages=True**返回消息对象列表(List[BaseMessage] return_messages=False(默认) 返回拼接的纯文本字符串
- **
2.3.1 场景1:入门使用
举例1:以字符串的方式返回存储的信息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15from langchain.memory import ConversationBufferMemory
# 1、ConversationBufferMemory的实例化
memory = ConversationBufferMemory()
# 2、存储相关的消息
# inputs对应的就是用户消息,outputs对应的就是ai消息
memory.save_context(inputs={"human": "你好,我叫小明"}, outputs={"ai": "很高兴认识你"})
memory.save_context(inputs={"input": "帮我回答一下1+2*3=?"}, outputs={"output": "7"})
# 3、获取存储的信息
print(memory.load_memory_variables({}))
# {'history': 'Human: 你好,我叫小明\nAI: 很高兴认识你\nHuman: 帮我回答一下1+2*3=?\nAI: 7'}
#说明:返回的字典结构的key叫history.- 不管inputs、outputs的key用什么名字,都认为inputs的key是human,outputs的key是AI。
- 打印的结果的json数据的key,默认是“history”。可以通过ConversationBufferMemory的
memory_key属性修改。
举例2:以消息列表的方式返回存储的信息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22from langchain.memory import ConversationBufferMemory
# 1、ConversationBufferMemory的实例化
memory = ConversationBufferMemory(return_messages=True)
# 2、存储相关的消息
# inputs对应的就是用户消息,outputs对应的就是ai消息
memory.save_context(inputs={"human": "你好,我叫小明"}, outputs={"ai": "很高兴认识你"})
memory.save_context(inputs={"input": "帮我回答一下1+2*3=?"}, outputs={"output": "7"})
# 3、获取存储的信息
#返回消息列表的方式1:
print(memory.load_memory_variables({}))
# {'history': [HumanMessage(content='你好,我叫小明', additional_kwargs={}, response_metadata={}), AIMessage(content='很高兴认识你', additional_kwargs={}, response_metadata={}), HumanMessage(content='帮我回答一下1+2*3=?', additional_kwargs={}, response_metadata={}), AIMessage(content='7', additional_kwargs={}, response_metadata={})]}
print("\n")
#返回消息列表的方式2:
print(memory.chat_memory.messages)
# [HumanMessage(content='你好,我叫小明', additional_kwargs={}, response_metadata={}), AIMessage(content='很高兴认识你', additional_kwargs={}, response_metadata={}), HumanMessage(content='帮我回答一下1+2*3=?', additional_kwargs={}, response_metadata={}), AIMessage(content='7', additional_kwargs={}, response_metadata={})]
#说明:返回的字典结构的key叫history.
2.3.2 场景2:结合chain
举例1:结合大模型、提示词模板的使用(PromptTemplate)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29from langchain.chains.llm import LLMChain
from langchain_openai import ChatOpenAI
from langchain_core.prompts.prompt import PromptTemplate
# 1、创建大模型实例
llm = ChatOpenAI(model="gpt-4o-mini")
# 2、提供提示词模板
prompt_template = PromptTemplate.from_template(
template="""
你可以与人类对话。
当前对话历史: {history}
人类问题: {question}
回复:
"""
)
# 3、提供memory实例
memory = ConversationBufferMemory()
# 4、提供Chain
chain = LLMChain(llm=llm, prompt=prompt_template, memory=memory)
response = chain.invoke({"question": "你好,我的名字叫小明"})
print(response)
# {'question': '你好,我的名字叫小明', 'history': '', 'text': '你好,小明!很高兴认识你。有什么我可以帮助你的吗?'}1
2
3response = chain.invoke({"question": "我叫什么名字呢?"})
print(response)
# {'question': '我叫什么名字呢?', 'history': 'Human: 你好,我的名字叫小明\nAI: 你好,小明!很高兴认识你。有什么我可以帮助你的吗?', 'text': '你叫小明。很高兴再次和你交流!还有其他问题或者想聊的内容吗?'}举例2:基于举例1,显式的设置meory的key的值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29from langchain.chains.llm import LLMChain
from langchain_openai import ChatOpenAI
from langchain_core.prompts.prompt import PromptTemplate
# 1、创建大模型实例
llm = ChatOpenAI(model="gpt-4o-mini")
# 2、提供提示词模板
prompt_template = PromptTemplate.from_template(
template="""
你可以与人类对话。
当前对话历史: {chat_history}
人类问题: {question}
回复:
"""
)
# 3、提供memory实例
memory = ConversationBufferMemory(memory_key="chat_history")
# 4、提供Chain
chain = LLMChain(llm=llm, prompt=prompt_template, memory=memory)
response = chain.invoke({"question": "你好,我的名字叫小明"})
print(response)
# {'question': '你好,我的名字叫小明', 'chat_history': '', 'text': '你好,小明!很高兴认识你。有任何问题或者想聊的话题吗?'}1
2
3response = chain.invoke({"question": "我叫什么名字呢?"})
print(response)
# {'question': '我叫什么名字呢?', 'chat_history': 'Human: 你好,我的名字叫小明\nAI: 你好,小明!很高兴认识你。有什么我可以帮助你的吗?', 'text': '你叫小明。很高兴再次见到你!有什么想聊的呢?'}举例3:结合大模型、提示词模板的使用(ChatPromptTemplate)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27# 1.导入相关包
from langchain_core.messages import SystemMessage
from langchain.chains.llm import LLMChain
from langchain.memory import ConversationBufferMemory
from langchain_core.prompts import MessagesPlaceholder,ChatPromptTemplate,HumanMessagePromptTemplate
from langchain_openai import ChatOpenAI
# 2.创建LLM
llm = ChatOpenAI(model_name='gpt-4o-mini')
# 3.创建Prompt
prompt = ChatPromptTemplate.from_messages([
("system","你是一个与人类对话的机器人。"),
MessagesPlaceholder(variable_name='history'),
("human","问题:{question}")
])
# 4.创建Memory
memory = ConversationBufferMemory(return_messages=True)
# 5.创建LLMChain
llm_chain = LLMChain(prompt=prompt,llm=llm, memory=memory)
# 6.调用LLMChain
res1 = llm_chain.invoke({"question": "中国首都在哪里?"})
print(res1,end="\n\n")
# {'question': '中国首都在哪里?', 'history': [HumanMessage(content='中国首都在哪里?', additional_kwargs={}, response_metadata={}), AIMessage(content='中国的首都位于北京。', additional_kwargs={}, response_metadata={})], 'text': '中国的首都位于北京。'}1
2
3res2 = llm_chain.invoke({"question": "我刚刚问了什么"})
print(res2)
# {'question': '我刚刚问了什么', 'history': [HumanMessage(content='中国首都在哪里?', additional_kwargs={}, response_metadata={}), AIMessage(content='中国的首都位于北京。', additional_kwargs={}, response_metadata={}), HumanMessage(content='我刚刚问了什么', additional_kwargs={}, response_metadata={}), AIMessage(content='你刚刚问了中国的首都在哪里。', additional_kwargs={}, response_metadata={})], 'text': '你刚刚问了中国的首都在哪里。'}二者对比
特性 普通 PromptTemplate ChatPromptTemplate 历史存储时机 仅执行后存储 执行前存储用户输入 + 执行后存储输出 首次调用显示 仅显示问题(历史仍为空字符串) 显示完整问答对 内部消息类型 拼接字符串 List[BaseMessage]- 我们观察到的现象不是bug,而是LangChain 为保障对话一致性所做的刻意设计:
- 用户提问后,系统应立即”记住”该问题
- AI回答后,该响应应即刻加入对话上下文
- 返回给客户端的结果应反映最新状态
- 我们观察到的现象不是bug,而是LangChain 为保障对话一致性所做的刻意设计:
2.4 ConversationChain
ConversationChain提供了包含AI角色和人类角色的对话摘要格式,这个对话格式和记忆机制结合得非常紧密。
ConversationChain实际上是就是对
ConversationBufferMemory和LLMChain进行了封装,并且提供一个默认格式的提示词模版(我们也可以不用),从而简化了初始化ConversationBufferMemory的步骤。举例1:使用PromptTemplate
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33from langchain.chains.conversation.base import ConversationChain
from langchain.chains.llm import LLMChain
from langchain_openai import ChatOpenAI
from langchain_core.prompts.prompt import PromptTemplate
# 1、创建大模型实例
llm = ChatOpenAI(model="gpt-4o-mini")
# 2、提供提示词模板
prompt_template = PromptTemplate.from_template(
template="""
你可以与人类对话。
当前对话历史: {history}
人类问题: {input}
回复:
"""
)
# # 3、提供memory实例
# memory = ConversationBufferMemory()
#
# # 4、提供Chain
# chain = LLMChain(llm=llm, prompt=prompt_template, memory=memory)
# 3、创建ConversationChain的实例
chain = ConversationChain(llm = llm, prompt=prompt_template)
response = chain.invoke({"input": "你好,我的名字叫小明"})
print(response)
# {'input': '你好,我的名字叫小明', 'history': '', 'response': '你好,小明!很高兴认识你。你今天过得怎么样?'}1
2
3response = chain.invoke({"input": "我的名字叫什么?"})
print(response)
# {'input': '我的名字叫什么?', 'history': 'Human: 你好,我的名字叫小明\nAI: 你好,小明!很高兴认识你。你今天过得怎么样?', 'response': '你的名字叫小明。'}举例2:使用默认提供的提示词模板
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33from langchain.chains.conversation.base import ConversationChain
from langchain.chains.llm import LLMChain
from langchain_openai import ChatOpenAI
from langchain_core.prompts.prompt import PromptTemplate
# 1、创建大模型实例
llm = ChatOpenAI(model="gpt-4o-mini")
# 2、提供提示词模板
# prompt_template = PromptTemplate.from_template(
# template="""
# 你可以与人类对话。
#
# 当前对话历史: {history}
#
# 人类问题: {input}
#
# 回复:
# """
# )
# # 3、提供memory实例
# memory = ConversationBufferMemory()
#
# # 4、提供Chain
# chain = LLMChain(llm=llm, prompt=prompt_template, memory=memory)
# 3、创建ConversationChain的实例(内部提供了默认的提示词模板。而此模板中的变量是{input}、{history}
chain = ConversationChain(llm = llm)
response = chain.invoke({"input": "你好,我的名字叫小明"})
print(response)
# {'input': '你好,我的名字叫小明', 'history': '', 'response': '你好,小明!很高兴认识你!我是一种人工智能助手,随时准备帮助你。你今天怎么样?有什么特别想聊的吗?'}1
2
3response = chain.invoke({"input": "我的名字叫什么?"})
print(response)
# {'input': '我的名字叫什么?', 'history': 'Human: 你好,我的名字叫小明\nAI: 你好,小明!很高兴认识你!我是一种人工智能助手,随时准备帮助你。你今天怎么样?有什么特别想聊的吗?', 'response': '你的名字叫小明!我记得你刚刚告诉我这个信息。你想聊些什么,或者有什么问题需要我帮助的吗?'}
2.5 ConversationBufferWindowMemory
- 在了解了ConversationBufferMemory记忆类后,我们知道了它能够无限的将历史对话信息填充到History中,从而给大模型提供上下文的背景。但这会
导致内存量十分大,并且消耗的token是非常多的,此外,每个大模型都存在最大输入的Token限制。 - 我们发现,过久远的对话数据往往并不能对当前轮次的问答提供有效的信息,LangChain 给出的解决方式是:
ConversationBufferWindowMemory模块。该记忆类会保存一段时间内对话交互的列表,仅使用最近 K 个交互。这样就使缓存区不会变得太大。 - 特点:
- 适合长对话场景。
- **与 Chains/Models **无缝集成
- 支持两种返回格式(通过
return_messages参数控制输出格式)- **
return_messages=True**返回消息对象列表(List[BaseMessage] return_messages=False(默认) 返回拼接的纯文本字符串
- **
2.5.1 场景1:入门使用
举例 1:
1
2
3
4
5
6
7
8
9
10
11
12# 1.导入相关包
from langchain.memory import ConversationBufferWindowMemory
# 2.实例化ConversationBufferWindowMemory对象,设定窗口阈值
memory = ConversationBufferWindowMemory(k=1)
# 3.保存消息
memory.save_context({"input": "你好"}, {"output": "怎么了"})
memory.save_context({"input": "你是谁"}, {"output": "我是AI助手"})
memory.save_context({"input": "你的生日是哪天?"}, {"output": "我不清楚"})
# 4.读取内存中消息(返回消息内容的纯文本)
print(memory.load_memory_variables({}))
# {'history': 'Human: 你的生日是哪天?\nAI: 我不清楚'}举例2:返回消息构成的上下文记忆。ConversationBufferWindowMemory 也支持使用聊天模型(Chat Model)的情况,同样可以通过
return_messages=True参数,将对话转化为消息列表形式。1
2
3
4
5
6
7
8
9
10
11
12# 1.导入相关包
from langchain.memory import ConversationBufferWindowMemory
# 2.实例化ConversationBufferWindowMemory对象,设定窗口阈值
memory = ConversationBufferWindowMemory(k=2, return_messages=True)
# 3.保存消息
memory.save_context({"input": "你好"}, {"output": "怎么了"})
memory.save_context({"input": "你是谁"}, {"output": "我是AI助手小智"})
memory.save_context({"input": "初次对话,你能介绍一下你自己吗?"}, {"output": "当然可以了。我是一个无所不能的小智。"})
# 4.读取内存中消息(返回消息内容的纯文本)
print(memory.load_memory_variables({}))
# {'history': [HumanMessage(content='你是谁', additional_kwargs={}, response_metadata={}), AIMessage(content='我是AI助手小智', additional_kwargs={}, response_metadata={}), HumanMessage(content='初次对话,你能介绍一下你自己吗?', additional_kwargs={}, response_metadata={}), AIMessage(content='当然可以了。我是一个无所不能的小智。', additional_kwargs={}, response_metadata={})]}
2.5.2 场景2:结合chain
举例1:结合llm、chain的使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49from langchain.memory import ConversationBufferWindowMemory
# 1.导入相关包
from langchain_core.prompts.prompt import PromptTemplate
from langchain.chains.llm import LLMChain
# 2.定义模版
template = """以下是人类与AI之间的友好对话描述。AI表现得很健谈,并提供了大量来自其上下文的具体细节。如果AI不知道问题的答案,它会表示不知道。
当前对话:
{history}
Human: {question}
AI:"""
# 3.定义提示词模版
prompt_template = PromptTemplate.from_template(template)
# 4.创建大模型
llm = ChatOpenAI(model="gpt-4o-mini")
# 5.实例化ConversationBufferWindowMemory对象,设定窗口阈值
memory = ConversationBufferWindowMemory(k=1)
# 6.定义LLMChain
conversation_with_summary = LLMChain(
llm=llm,
prompt=prompt_template,
memory=memory,
#verbose=True,
)
# 7.执行链(第一次提问)
respon1 = conversation_with_summary.invoke({"question":"你好,我是孙小空"})
print(respon1)
# {'question': '你好,我是孙小空', 'history': '', 'text': '你好,孙小空!很高兴见到你!你今天过得怎么样?有什么我可以帮助你的吗?'}
# 8.执行链(第二次提问)
respon2 =conversation_with_summary.invoke({"question":"我还有两个师弟,一个是猪小戒,一个是沙小僧"})
print(respon2)
# {'question': '我还有两个师弟,一个是猪小戒,一个是沙小僧', 'history': 'Human: 你好,我是孙小空\nAI: 你好,孙小空!很高兴见到你!你今天过得怎么样?有什么我可以帮助你的吗?', 'text': '哇,猪小戒和沙小僧听起来很有趣!他们是不是你们团队里的搞笑角色呢?你们平时都一起做些什么呢?'}
# 9.执行链(第三次提问)
respon3 =conversation_with_summary.invoke({"question":"我今年高考,竟然考上了1本"})
print(respon3)
# {'question': '我今年高考,竟然考上了1本', 'history': 'Human: 我还有两个师弟,一个是猪小戒,一个是沙小僧\nAI: 哇,猪小戒和沙小僧听起来很有趣!他们是不是你们团队里的搞笑角色呢?你们平时都一起做些什么呢?', 'text': '太厉害了!恭喜你考上了一本!这是一个很大的成就,你一定付出了很多努力。你想要学什么专业呢?或者有没有什么学校是你特别想去的?'}
# 10.执行链(第四次提问)
respon4 =conversation_with_summary.invoke({"question":"我叫什么名字?"})
print(respon4)
# {'question': '我叫什么名字?', 'history': 'Human: 我今年高考,竟然考上了1本\nAI: 太厉害了!恭喜你考上了一本!这是一个很大的成就,你一定付出了很多努力。你想要学什么专业呢?或者有没有什么学校是你特别想去的?', 'text': '抱歉,我不知道你的名字。你愿意告诉我吗?或者我们可以聊聊其他你感兴趣的事情!'}举例2:修改举例1中的参数k
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43from langchain.memory import ConversationBufferWindowMemory
# 1.导入相关包
from langchain_core.prompts.prompt import PromptTemplate
from langchain.chains.llm import LLMChain
# 2.定义模版
template = """以下是人类与AI之间的友好对话描述。AI表现得很健谈,并提供了大量来自其上下文的具体细节。如果AI不知道问题的答案,它会表示不知道。
当前对话:
{history}
Human: {question}
AI:"""
# 3.定义提示词模版
prompt_template = PromptTemplate.from_template(template)
# 4.创建大模型
llm = ChatOpenAI(model="gpt-4o-mini")
# 5.实例化ConversationBufferWindowMemory对象,设定窗口阈值
memory = ConversationBufferWindowMemory(k=3)
# 6.定义LLMChain
conversation_with_summary = LLMChain(
llm=llm,
prompt=prompt_template,
memory=memory,
#verbose=True,
)
# 7.执行链(第一次提问)
respon1 = conversation_with_summary.invoke({"question":"你好,我是孙小空"})
# print(respon1)
# 8.执行链(第二次提问)
respon2 =conversation_with_summary.invoke({"question":"我还有两个师弟,一个是猪小戒,一个是沙小僧"})
# print(respon2)
# 9.执行链(第三次提问)
respon3 =conversation_with_summary.invoke({"question":"我今年高考,竟然考上了1本"})
# print(respon3)
# 10.执行链(第四次提问)
respon4 =conversation_with_summary.invoke({"question":"我叫什么名字?"})
print(respon4)
# {'question': '我叫什么名字?', 'history': 'Human: 你好,我是孙小空\nAI: 你好,孙小空!很高兴认识你。你今天过得怎么样?有什么想聊的内容吗?\nHuman: 我还有两个师弟,一个是猪小戒,一个是沙小僧\nAI: 很高兴认识你的师弟们!猪小戒和沙小僧的名字听起来很有趣,似乎有些文艺或是神话背景。你们是不是一起学习或者修炼什么特别的技能呢?如果有趣的故事或者共同经历,欢迎分享!\nHuman: 我今年高考,竟然考上了1本\nAI: 太棒了,孙小空!恭喜你考上了一本大学!这是一个很大的成就,你一定为自己感到骄傲。你打算学什么专业呢?或者你对未来有什么计划吗?', 'text': '你叫孙小空!如果你有其他问题或者想聊的话题,请随时告诉我!'}
3、其他Memory模块
3.1 ConversationTokenBufferMemory
ConversationTokenBufferMemory 是 LangChain 中一种基于
Token 数量控制的对话记忆机制。如果字符数量超出指定数目,它会切掉这个对话的早期部分,以保留与最近的交流相对应的字符数量。特点:
- Token 精准控制
- 原始对话保留
原理:

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20# 1.导入相关包
from langchain.memory import ConversationTokenBufferMemory
from langchain_openai import ChatOpenAI
# 2.创建大模型
llm = ChatOpenAI(model="gpt-4o-mini")
# 3.定义ConversationTokenBufferMemory对象
memory = ConversationTokenBufferMemory(
llm=llm,
max_token_limit=20 # 设置token上限,默认值为2000
)
# 添加对话
memory.save_context({"input": "你好吗?"}, {"output": "我很好,谢谢!"})
memory.save_context({"input": "今天天气如何?"}, {"output": "晴天,25度"})
# 查看当前记忆
print(memory.load_memory_variables({}))
# {'history': 'AI: 晴天,25度'}

3.2 ConversationSummaryMemory
前面的方式发现,如果全部保存下来太过浪费,截断时无论是按照
对话条数还是token都是无法保证既节省内存或token又保证对话质量的,所以推出ConversationSummaryMemory、ConversationSummaryBufferMemory。ConversationSummaryMemory是 LangChain 中一种
智能压缩对话历史的记忆机制,它通过大语言模型(LLM)自动生成对话内容的精简摘要,而不是存储原始对话文本。这种记忆方式特别适合长对话和需要保留核心信息的场景。
特点:
- 摘要生成
- 动态更新
- 上下文优化
原理:

场景1:如果实例化ConversationSummaryMemory前,没有历史消息,可以使用构造方法实例化。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18# 1.导入相关包
from langchain.memory import ConversationSummaryMemory, ChatMessageHistory
from langchain_openai import ChatOpenAI
# 2.创建大模型
llm = ChatOpenAI(model="gpt-4o-mini")
# 3.定义ConversationSummaryMemory对象
memory = ConversationSummaryMemory(llm=llm)
# 4.存储消息
memory.save_context({"input": "你好"}, {"output": "怎么了"})
memory.save_context({"input": "你是谁"}, {"output": "我是AI助手小智"})
memory.save_context({"input": "初次对话,你能介绍一下你自己吗?"}, {"output": "当然可以了。我是一个无所不能的小智。"})
# 5.读取消息(总结后的)
print(memory.load_memory_variables({}))
# {'history': 'The human greets the AI with "你好" (hello), and the AI responds with "怎么了" (what\'s wrong?). The human then asks, "你是谁" (who are you?), to which the AI replies, "我是AI助手小智" (I am the AI assistant Xiao Zhi). The human requests an introduction, and the AI states, "当然可以了。我是一个无所不能的小智" (Of course, I am an all-powerful Xiao Zhi).'}举例2:如果实例化ConversationSummaryMemory前,已经有历史消息,可以调用from_messages()实例化。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30# 1.导入相关包
from langchain.memory import ConversationSummaryMemory, ChatMessageHistory
from langchain_openai import ChatOpenAI
# 2.定义ChatMessageHistory对象
llm = ChatOpenAI(model="gpt-4o-mini")
# 3.假设原始消息
history = ChatMessageHistory()
history.add_user_message("你好,你是谁?")
history.add_ai_message("我是AI助手小智")
# 4.创建ConversationSummaryMemory的实例
memory = ConversationSummaryMemory.from_messages(
llm = llm,
#是生成摘要的原材料 保留完整对话供必要时回溯。当新增对话时,LLM需要结合原始历史生成新摘要
chat_memory = history,
)
print(memory.load_memory_variables({}))
# {'history': 'The human greets the AI and asks who it is. The AI responds that it is an AI assistant named Xiao Zhi.'}
memory.save_context(inputs={"human":"我的名字叫小明"},outputs={"ai":"很高兴认识你"})
print(memory.load_memory_variables({}))
# {'history': 'The human greets the AI, asks who it is, and introduces himself as Xiao Ming. The AI responds that it is an AI assistant named Xiao Zhi and expresses pleasure in meeting him.'}
#记录了历史的交互的消息
print(memory.chat_memory.messages)
# [HumanMessage(content='你好,你是谁?', additional_kwargs={}, response_metadata={}), AIMessage(content='我是AI助手小智', additional_kwargs={}, response_metadata={}), HumanMessage(content='我的名字叫小明', additional_kwargs={}, response_metadata={}), AIMessage(content='很高兴认识你', additional_kwargs={}, response_metadata={})]

3.3 ConversationSummaryBufferMemory
ConversationSummaryBufferMemory 是 LangChain 中一种混合型记忆机制,它结合了 ConversationBufferMemory(完整对话记录)和 ConversationSummaryMemory(摘要记忆)的优点,在保留最近对话原始记录的同时,对较早的对话内容进行智能摘要。
特点:
- 保留最近N条原始对话:确保最新交互的完整上下文。
- 摘要较早历史:对超出缓冲区的旧对话进行压缩,避免信息过载。
- 平衡细节与效率:既不会丢失关键细节,又能处理长对话。
原理:


3.3.1 场景1:入门使用
情况1:构造方法实例化,并设置max_token_limit
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24from langchain.memory import ConversationSummaryBufferMemory
# 获取大模型
llm = ChatOpenAI(model="gpt-4o-mini")
# 实例化ConversationSummaryBufferMemory
memory = ConversationSummaryBufferMemory(
llm = llm,
max_token_limit=40, #控制缓冲区的大小
return_messages=True,
)
# 向memory中存储信息
memory.save_context(inputs={"input":"你好,我的名字叫小明"},outputs={"output":"很高兴认识你"})
memory.save_context(inputs={"input":"李白是哪个朝代的诗人"},outputs={"output":"李白是唐朝的诗人"})
memory.save_context(inputs={"input":"唐宋八大家里有苏轼吗?"},outputs={"output":"有"})
print(memory.load_memory_variables({}))
# {'history': [SystemMessage(content='The human introduces themselves as 小明. The AI expresses happiness to meet them. The human asks which dynasty the poet Li Bai belongs to.', additional_kwargs={}, response_metadata={}), AIMessage(content='李白是唐朝的诗人', additional_kwargs={}, response_metadata={}), HumanMessage(content='唐宋八大家里有苏轼吗?', additional_kwargs={}, response_metadata={}), AIMessage(content='有', additional_kwargs={}, response_metadata={})]}
print("\n")
print(memory.chat_memory.messages)
# [AIMessage(content='李白是唐朝的诗人', additional_kwargs={}, response_metadata={}), HumanMessage(content='唐宋八大家里有苏轼吗?', additional_kwargs={}, response_metadata={}), AIMessage(content='有', additional_kwargs={}, response_metadata={})]对比情况1:调大缓冲区的大小
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24from langchain.memory import ConversationSummaryBufferMemory
# 获取大模型
llm = ChatOpenAI(model="gpt-4o-mini")
# 实例化ConversationSummaryBufferMemory
memory = ConversationSummaryBufferMemory(
llm = llm,
max_token_limit=100, #控制缓冲区的大小
return_messages=True,
)
# 向memory中存储信息
memory.save_context(inputs={"input":"你好,我的名字叫小明"},outputs={"output":"很高兴认识你"})
memory.save_context(inputs={"input":"李白是哪个朝代的诗人"},outputs={"output":"李白是唐朝的诗人"})
memory.save_context(inputs={"input":"唐宋八大家里有苏轼吗?"},outputs={"output":"有"})
print(memory.load_memory_variables({}))
# {'history': [HumanMessage(content='你好,我的名字叫小明', additional_kwargs={}, response_metadata={}), AIMessage(content='很高兴认识你', additional_kwargs={}, response_metadata={}), HumanMessage(content='李白是哪个朝代的诗人', additional_kwargs={}, response_metadata={}), AIMessage(content='李白是唐朝的诗人', additional_kwargs={}, response_metadata={}), HumanMessage(content='唐宋八大家里有苏轼吗?', additional_kwargs={}, response_metadata={}), AIMessage(content='有', additional_kwargs={}, response_metadata={})]}
print("\n")
print(memory.chat_memory.messages)
# [HumanMessage(content='你好,我的名字叫小明', additional_kwargs={}, response_metadata={}), AIMessage(content='很高兴认识你', additional_kwargs={}, response_metadata={}), HumanMessage(content='李白是哪个朝代的诗人', additional_kwargs={}, response_metadata={}), AIMessage(content='李白是唐朝的诗人', additional_kwargs={}, response_metadata={}), HumanMessage(content='唐宋八大家里有苏轼吗?', additional_kwargs={}, response_metadata={}), AIMessage(content='有', additional_kwargs={}, response_metadata={})]
3.3.2 场景2:客服
1 | from langchain.memory import ConversationSummaryBufferMemory |
3.4 ConversationEntityMemory(了解)
ConversationEntityMemory 是一种基于实体的对话记忆机制,它能够智能地识别、存储和利用对话中 出现的实体信息(如人名、地点、产品等)及其属性/关系,并结构化存储,使 AI 具备更强的上下文理 解和记忆能力。
好处:解决信息过载问题
- 长对话中大量冗余信息会干扰关键事实记忆。
- 通过对实体摘要,可以压缩非重要细节(如删除寒暄等,保留价格/时间等硬性事实)。
应用场景:在医疗等高风险领域,必须用实体记忆确保关键信息(如过敏史)被100%准确识别和拦截。
1
2
3
4
5
6{"input": "我头痛,血压140/90,在吃阿司匹林。"},
{"output": "建议监测血压,阿司匹林可继续服用。"}
{"input": "我对青霉素过敏。"},
{"output": "已记录您的青霉素过敏史。"}
{"input": "阿司匹林吃了三天,头痛没缓解。"},
{"output": "建议停用阿司匹林,换布洛芬试试。"}使用ConversationSummaryMemory:
1
"患者主诉头痛和高血压(140/90),正在服用阿司匹林。患者对青霉素过敏。三天后头痛未缓解,建议更换止痛药。
使用ConversationEntityMemory:
1
2
3
4
5
6{
"症状":"头痛",
"血压":"140/90",
"当前用药":"阿司匹林(无效)",
"过敏药物":"青霉素"
}对比:ConversationSummaryMemory 和 ConversationEntityMemory

举例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29from langchain.chains.conversation.base import LLMChain
from langchain.memory import ConversationEntityMemory
from langchain.memory.prompt import ENTITY_MEMORY_CONVERSATION_TEMPLATE
from langchain_openai import ChatOpenAI
# 初始化大语言模型
llm = ChatOpenAI(model_name='gpt-4o-mini', temperature=0)
# 使用LangChain为实体记忆设计的预定义模板
prompt = ENTITY_MEMORY_CONVERSATION_TEMPLATE
# 初始化实体记忆
memory = ConversationEntityMemory(llm=llm)
# 提供对话链
chain = LLMChain(
llm=llm,
prompt=ENTITY_MEMORY_CONVERSATION_TEMPLATE,
memory=ConversationEntityMemory(llm=llm),
#verbose=True, # 设置为True可以看到链的详细推理过程
)
# 进行几轮对话,记忆组件会在后台自动提取和存储实体信息
chain.invoke(input="你好,我叫蜘蛛侠。我的好朋友包括钢铁侠、美国队长和绿巨人。")
chain.invoke(input="我住在纽约。")
chain.invoke(input="我使用的装备是由斯塔克工业提供的。")
# 查询记忆体中存储的实体信息
print("\n当前存储的实体信息:")
print(chain.memory.entity_store.store)
# 当前存储的实体信息:
# {'蜘蛛侠': '蜘蛛侠的好朋友包括钢铁侠、美国队长和绿巨人。', '钢铁侠': '钢铁侠是蜘蛛侠的好朋友之一。', '美国队长': '美国队长是蜘蛛侠的好朋友之一。', '绿巨人': '绿巨人是蜘蛛侠的好朋友之一。', '纽约': '蜘蛛侠住在纽约。', '斯塔克工业': '斯塔克工业提供了蜘蛛侠使用的装备。'}1
2
3
4
5
6# 基于记忆进行提问
answer = chain.invoke(input="你能告诉我蜘蛛侠住在哪里以及他的好朋友有哪些吗?")
print("\nAI的回答:")
print(answer)
# AI的回答:
# {'input': '你能告诉我蜘蛛侠住在哪里以及他的好朋友有哪些吗?', 'history': 'Human: 你好,我叫蜘蛛侠。我的好朋友包括钢铁侠、美国队长和绿巨人。\nAI: 你好,蜘蛛侠!很高兴认识你。你和钢铁侠、美国队长以及绿巨人都是超级英雄,真是一个强大的团队!你们最近有什么冒险吗?\nHuman: 我住在纽约。\nAI: 纽约是一个充满活力的城市,适合超级英雄们活动!你在纽约的生活怎么样?有没有遇到什么有趣的事情或者挑战?\nHuman: 我使用的装备是由斯塔克工业提供的。\nAI: 斯塔克工业的装备真是太棒了!钢铁侠的技术总是让人惊叹。你最喜欢使用哪一件装备?它在你的冒险中帮助了你哪些方面?', 'entities': {'蜘蛛侠': '蜘蛛侠的好朋友包括钢铁侠、美国队长和绿巨人。', '纽约': '蜘蛛侠住在纽约。', '钢铁侠': '钢铁侠是蜘蛛侠的好朋友之一。', '美国队长': '美国队长是蜘蛛侠的好朋友之一。', '绿巨人': '绿巨人是蜘蛛侠的好朋友之一。'}, 'text': '蜘蛛侠住在纽约。他的好朋友包括钢铁侠、美国队长和绿巨人。这些超级英雄们常常一起合作,面对各种挑战和敌人。你对他们的冒险有什么特别的记忆吗?'}

3.5 ConversationKGMemory(了解)
ConversationKGMemory是一种基于**知识图谱(Knowledge Graph)**的对话记忆模块,它比 ConversationEntityMemory 更进一步,不仅能识别和存储实体,还能捕捉实体之间的复杂关系,形成结构化的知识网络。
特点:
- 知识图谱结构将对话内容转化为 (头实体, 关系, 尾实体) 的三元组形式
- 动态关系推理
举例:
1
pip install networkx
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20#1.导入相关包
from langchain.memory import ConversationKGMemory
from langchain.chat_models import ChatOpenAI
# 2.定义LLM
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
# 3.定义ConversationKGMemory对象
memory = ConversationKGMemory(llm=llm)
# 4.保存会话
memory.save_context({"input": "向山姆问好"}, {"output": "山姆是谁"})
memory.save_context({"input": "山姆是我的朋友"}, {"output": "好的"})
# 5.查询会话
memory.load_memory_variables({"input": "山姆是谁"})
# {'history': 'On 山姆: 山姆 是 我的朋友.'}
memory.get_knowledge_triplets("她最喜欢的颜色是红色")
# [KnowledgeTriple(subject='山姆', predicate='是', object_='我的朋友'), KnowledgeTriple(subject='山姆', predicate='最喜欢的颜色是', object_='红色')]
3.6 VectorStoreRetrieverMemory(了解)
VectorStoreRetrieverMemory是一种基于
向量检索的先进记忆机制,它将对话历史存储在向量数据库 中,通过语义相似度检索相关信息,而非传统的线性记忆方式。每次调用时,就会查找与该记忆关联最 高的k个文档。适用场景:这种记忆特别适合需要长期记忆和语义理解的复杂对话系统。
原理:

举例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28# 1.导入相关包
from langchain_openai import OpenAIEmbeddings
from langchain.memory import VectorStoreRetrieverMemory
from langchain_community.vectorstores import FAISS
from langchain.memory import ConversationBufferMemory
# 2.定义ConversationBufferMemory对象
memory = ConversationBufferMemory()
memory.save_context({"input": "我最喜欢的食物是披萨"}, {"output": "很高兴知道"})
memory.save_context({"Human": "我喜欢的运动是跑步"}, {"AI": "好的,我知道了"})
memory.save_context({"Human": "我最喜欢的运动是足球"}, {"AI": "好的,我知道了"})
# 3.定义向量嵌入模型
embeddings_model = OpenAIEmbeddings(
model="text-embedding-ada-002"
)
# 4.初始化向量数据库
vectorstore = FAISS.from_texts(memory.buffer.split("\n"), embeddings_model) # 空初始化
# 5.定义检索对象
retriever = vectorstore.as_retriever(search_kwargs=dict(k=1))
# 6.初始化VectorStoreRetrieverMemory
memory = VectorStoreRetrieverMemory(retriever=retriever)
print(memory.load_memory_variables({"prompt": "我最喜欢的食物是"}))
# {'history': 'Human: 我最喜欢的食物是披萨'}
