LangChain1.0框架基础入门实战
1、LangChain框架介绍
- LangChain 是一个构建 LLM 应用的框架,目标是把 LLM 与外部工具、数据源和复杂工作流连接起来 —— 支持从简单的 prompt 封装到复杂的 Agent(能够调用工具、做决策、执行多步任务)。它不仅仅是对LLM API的封装,而是提供了一套完整的工具和架构,让开发者能够更轻松地构建上下文感知和具备推理能力的AI应用。LangChain 1.0 版本把“Agent 的稳定化、结构化输出、可观测性与生产化”作为核心改进目标。
1.1 用 LangChain 能做什么?
构建 Retrieval-Augmented Generation(RAG)问答系统
把 LLM 当作“Agent”去调用外部 API(搜索、数据库、文件系统)并返回任务结果
组织 prompt → 模型 → 后处理 的可复用流水线(Chains)
实现多轮对话带记忆(Memory)与长会话管理
在生产中管理可观测性与评估(配合 LangSmith/LangGraph)
核心价值:让开发者用10行代码完成原本需要1000行代码的AI应用,并且自动获得状态持久化、人工干预、并发控制等企业级能力。
1.0 的架构风格可以用一句话概括:以“统一智能体抽象 + 标准化内容表示 + 可插拔治理中间件”为设计骨干,以 LangGraph 为底座运行时,实现“开发简单性”与“生产可控性”的兼顾。它一方面通过 create_agent 提供低门槛的构建入口,另一方面保留足够的钩子点与下探能力,以满足复杂工作流与高标准治理的需求。
1 | 你要做什么AI应用? |
1.2 LangChain生态概览
1.2.1 模型层(Models)
LangChain 1.0 的统一模型抽象层,为所有模型提供标准化调用,覆盖文本、多模态、Embedding、Rerank 等多类型模型,实现跨供应商一致体验
统一抽象:init_chat_model() 适配20+模型厂商
异步/流式/批处理:ainvoke(),stream(), batch()
执行方式:完全兼容 LCEL 与 LangGraph
扩展能力:with_structured_output()、Tool Calling、多模态 Content Blocks
1.2.2 工具层(Tools)
工具系统提供统一 Tool 抽象,支持所有主流模型的 Tool Calling,深度集成 LangGraph,构建可执行 agent 环境的关键能力层
内置工具:搜索、计算、代码执行等100+工具
自定义工具:@tool装饰器 / BaseTool / ToolNode
工具包:Toolkit(如GitHub、Slack集成)
1.2.3 记忆层(Memory)
记忆层提供统一 State 管理、对话记录、长期检索、多模态 Memory 等能力,支持持久化与复杂工作流状态流转
短期记忆:消息历史自动管理
长期记忆:向量数据库存储(Chroma, Pinecone)
存储接口:Store(跨会话持久化)
1.2.4 Agent层(Agents)
LangChain 1.0 Agents系统实现从碎片化到标准化升级,以create_agent为核心接口,基于LangGraph构建统一Agent抽象,10行代码即可创建基础Agent,封装”模型调用→工具选择→执行→结束”闭环流程
核心API:create_agent()
执行引擎:LangGraph Runtime(自动持久化)
中间件:Middleware(HITL、压缩、路由)
1.2.5 工作流层(Workflows)
Workflows 体系实现从 线性链式(Chain)到图结构(Graph) 的范式转移,以 StateGraph 为核心画布,将业务逻辑解耦为 “节点(Node)+ 边(Edge)+ 状态(State)”,原生支持循环(Loop)与条件分支,完美适配复杂任务编排、容错重试及长会话保持。
简单链:Chain(快速串联)
复杂图:LangGraph(条件分支、循环)
模板库:LangChain Hub(共享Agent模板)
1.2.6 调试监控层(Debugging)
LangChain 1.0 调试监控层实现了从 日志黑盒到全链路可观测性(Observability) 的质变,深度集成 LangSmith 平台,自动捕获链(Chain)与图(Graph)的每一步骤状态、Token 消耗及延迟,支持”Trace → Playground”一键回放调试,彻底解决复杂 Agent 逻辑难以排查的痛点。
本地日志:verbose=True
云端平台:LangSmith(可视化链路追踪)
评估工具:LangChain Evaluate(效果评估)
1.2.7 其他关键组件 (LangGraph & LangServe)
langgraph: 这是一个底层的Agent 调度框架 (Agent Runtime),是一个相对“低级”(Low-level)的编排框架,它专注于解决复杂的“控制流”问题,用于构建健壮且有状态的多角色 LLM 应用程序。LangChain 1.0 中的新 Agents (通过 create_agent()) 就是建立在 LangGraph 之上的。
langserve: 用于将任何 LangChain chain 或 agent 部署为 REST API 的包,方便快速将应用投入生产环境。
1.3 LangChain 1.0底层运行架构
1 | # 简化版架构示意图 |
LCEL:提供Runnable接口(invoke, stream, batch)和组合原语(|运算符),是无状态的函数式编排,构建“流水线(pipeline)”的工具
LangGraph:在LCEL基础上增加状态管理(State)、循环控制(Cycles)、持久化(Checkpoints),是有状态的图结构编排,构建“流程图(workflow/graph)”的工具
1.4 Runnable底层执行引擎
Runnable 是 LangChain 1.0 的“统一接口标准”,任何可以运行的组件——模型、Prompt、工具、解析器、Memory、Graph 节点——在 1.0 中都被抽象为 Runnable。
Runnable 使所有 LangChain 组件能够以统一接口组合、执行、链式调用,并支撑 LCEL(LangChain Expression Language)的整个运行语义,支撑可组合、可并行、可路由的链式执行,是 LangChain 1.0 的核心底座之一。
核心思想:Runnable 抽象与可组合链(Composable Chains)
LangChain 1.0 将所有链式元素统一为 Runnable(执行模型):
LLM(OpenAI、vLLM、Ollama……)
Prompt
Parser
Retriever
Tool
Agent
自定义函数
- 所有对象都可以 .invoke()、.batch()、.stream()、.astream_events(),这实现了真正的统一调用接口。
工程价值:
链路清晰。
任意组件之间可无缝组合。
所有执行方式(同步 / 异步 / 批处理 / 事件流)统一。
这是 LangChain 1.0 最具革命性的改变,使其成为“模型调用管道”的事实标准。
1.4.1 Prompt Runnable
1 | from langchain_core.prompts import ChatPromptTemplate |
messages=[HumanMessage(content='Tell me a joke about ice cream', additional_kwargs={}, response_metadata={})]
1.4.2 Tool Runnable
1 | from langchain_core.tools import tool |
6
[6, 20]
1.4.3 Runnable = LCEL 的语法基础
LCEL(| 运算符)是由 Runnable 定义的组合语义:
1 | chain = prompt | model | StrOutputParser() |
这三者本质都是 Runnable:
1 | PromptTemplate → Runnable |
任何 LCEL chain = 多个 Runnable 的组合。
| 技术 | 在 LangChain 1.0 的角色 |
|---|---|
| LangChain | 构建 LLM + prompt + tool + outputparser 的组件生态 |
| LangGraph | 构建 Agent / 多步工作流 / 状态机的框架 |
| LCEL / Runnable | LangChain 的底层执行引擎,依然核心 |
2、LangChain模块化管理的定位与描述
- LangChain 把“核心抽象”与“具体实现/第三方集成/历史实现”拆分成多个包,以实现更清晰的 API 边界、减小核心包体积、并把社区贡献与厂商集成模块化管理。主要目标是:核心更稳定、可维护;集成可按需安装。
2.1 LangChain 1.0核心依赖包及作用
| 依赖包名称 | 核心作用 | 详细功能介绍 |
|---|---|---|
| langchain-core | 核心抽象层和 LCEL | 定义所有组件(如模型、消息、提示词模板、工具、运行环境)的标准接口和基本抽象。它包含了 LangChain 表达式语言 (LCEL),这是构建链式应用的基础。这是一个轻量级、不含第三方集成的基石包。 |
| langchain | 应用认知架构(主包) | 包含构建 LLM 应用的通用高阶逻辑,如 Agents (如新的 create_agent() 函数)、Chains 和通用的检索策略 (Retrieval Strategies)。它建立在 langchain-core 之上,是用于组合核心组件的“胶水”层。 |
| langchain-community | 社区第三方集成 | 包含由 LangChain 社区维护的非核心或不太流行的第三方集成,例如:大部分的文档加载器 (Document Loaders)、向量存储 (Vector Stores)、不太流行的 LLM/Chat Model 集成等。为了保持包的轻量,所有依赖项都是可选的。 |
| langchain-openai / langchain-[厂商名称] | 特定厂商深度集成 | 针对 关键合作伙伴 的集成包(如 langchain-openai, langchain-anthropic)。它们被单独分离出来,以提供更好的支持、可靠性和更轻量级的依赖。它们只依赖于 langchain-core。 |
| langchain-classic | 旧版本兼容 | 包含 LangChain v0.x 版本中的已弃用 (deprecated) 或旧版功能,如旧的 LLMChain、旧版 Retrievers、Indexing API 和 Hub 模块。它的主要作用是为用户提供一个平稳的迁移期,确保旧代码在升级到 v1.0 后仍能运行。 |
2.1.1 langchain-core
包含 核心抽象与接口:LLM/ChatModel 抽象、Prompt 抽象、Chain/Agent 的基类、schema、消息格式等。
不包含具体厂商的实现(例如没有 OpenAI client 的封装),而是定义“合同(interfaces)”,其他包在此之上实现具体功能。
这是构建 LangChain 应用生态的最小公共底座。
1 | # 安装:pip install langchain |
2.1.2 langchain主包
对外的主入口包:把
langchain-core的核心抽象与“常用实现”组合在一起,便于快速上手。在 v1.0 中,
langchain的命名空间被 显著精简,只保留构建 agent 的关键 API(更轻、更专注)。官方建议大多数用户直接使用此主包以获得“开箱即用”的体验。
| 模块 | 核心内容 | 来源说明 |
|---|---|---|
langchain.agents |
create_agent, AgentState |
智能体创建核心 |
langchain.messages |
AIMessage, HumanMessage, trim_messages |
从langchain-core重新导出 |
langchain.tools |
@tool, BaseTool |
从langchain-core重新导出 |
langchain.chat_models |
init_chat_model, BaseChatModel |
统一模型初始化 |
langchain.embeddings |
init_embeddings |
嵌入模型管理 |
1 | from langchain.agents import create_agent |
2.1.3 langchain-community 第三方集成库
- langchain-community 作为 LangChain 1.0 的“功能扩展层”,通过社区贡献的非官方集成组件显著扩展了主包的功能边界,其核心价值体现在工具类组件与平台集成两大维度。工具类组件覆盖文档处理全流程,包括 DirectoryLoader 文档加载器(支持 PDF、文本等多格式文件批量导入)、RecursiveCharacterTextSplitter 文本分割器(按语义边界将文档切分为检索友好的 Chunk)、PGVector 向量存储(PostgreSQL 生态的向量数据库适配)及 HuggingFaceEmbeddings 嵌入模型(本地部署模型的向量化能力),这些组件共同构成了 RAG 应用的技术基础。平台集成方面,支持与 DeepSeek、阿里云通义千问等模型的对接,例如通过 langchain_community.chat_models.ChatTongyi 类初始化通义千问模型,或利用 Ollama 类调用本地部署的 DeepSeek-R1 模型。
- 收集并维护 社区/第三方贡献的集成(例如某些云厂商、开源向量库、特殊工具适配器等)。这些集成实现了
langchain-core定义的接口,但不属于主包维护范畴。官方会把这些放到langchain-community仓库/包,便于社区共同维护。
包含内容:
数据库:MySQL, PostgreSQL, MongoDB, Neo4j等连接器
存储服务:AWS S3, 阿里云OSS, Google Cloud Storage
工具集成:Slack, Notion, GitHub, ArXiv, YouTube等API
向量数据库:Chroma, Pinecone, Qdrant, Milvus等
文档加载器:PDF, CSV, HTML, Markdown解析器
特点:
质量参差不齐:社区贡献,需自行验证稳定性
更新滞后:依赖社区维护,响应速度慢于官方包
功能丰富:覆盖95%的第三方服务集成需求
1 | # 安装:pip install langchain-community |
2.1.4 langchain-openai(厂商/提供者集成包)
厂商特定集成包(如 langchain-openai、langchain-anthropic、langchain-google 等)通过封装 API 细节,为开发者提供“零适配成本”的模型对接方案,其核心价值在于简化特定 API 对接流程,使开发者能够直接使用厂商特有功能。以 langchain-openai 为例,其关键组件包括模型客户端、工具调用适配和多模型支持三大模块。
此外,该类还支持通过配置 openai_api_base 和 openai_api_key 参数对接兼容 OpenAI API 格式的第三方模型,如 DeepSeek 模型
专门负责把 OpenAI 的 SDK 与 LangChain 抽象连接起来:提供
ChatOpenAI、OpenAIEmbeddings、OpenAI等类的实现。这类包通常是 “按厂商拆分”:
langchain-openai、langchain-azure、langchain-anthropic、langchain-deepseek等。官方深度集成特定LLM提供商,更新频繁,功能最全.
1 | #!pip install langchain-openai |
主流厂商包列表:
langchain-openai:OpenAI, Azure OpenAIlangchain-anthropic:Claude系列langchain-google:Gemini, Vertex AIlangchain-deepseek:DeepSeek模型langchain-ollama:本地Ollama部署
与
langchain-community的区别:
| 维度 | langchain-openai |
langchain-community中的OpenAI |
|---|---|---|
| 维护方 | OpenAI官方 + LangChain团队 | 社区维护 |
| 更新频率 | 即时跟进API更新 | 延迟数周 |
| 功能完整性 | 支持所有新特性(如音频、视觉) | 仅基础功能 |
| 生产可用性 | ✅ 强烈推荐 | ⚠️ 谨慎使用 |
为什么要单独拆出来?
让
langchain主包保持轻量(不强制安装所有厂商 SDK);用户按需安装对应厂商,例如你只用 OpenAI,就只装
langchain-openai。
最佳实践:
生产环境务必使用厂商包:享受最新功能
开发环境可用community:快速验证想法
多厂商切换用
init_chat_model:业务代码无需改动
2.1.5 langchain-classic
兼容包 / 迁移包:把 LangChain v0.x 中的“老 API / legacy 功能”搬到单独包里,以便 v1.0 保持精简,但仍给用户向后兼容的迁移通道。
包含如:老的 Chain 实现、旧版 retrievers、索引 API、hub 模块等被标记为“legacy”的功能。
旧版
AgentExecutorLegacy Chains(
LLMChain,SequentialChain等)
1 | #!pip intsall langchain-classic |
3、核心概念与组件
环境依赖:
- LangChain 1.0+
Python 3.10+ (官方推荐)
- 我这里使用的是python 3.11版本
1 | !python --version |
Python 3.11.14
1 | !pip list | grep langchain |
langchain 1.0.7
langchain-classic 1.0.0
langchain-community 0.4.1
langchain-core 1.0.5
langchain-deepseek 1.0.1
langchain-openai 1.0.3
langchain-text-splitters 1.0.0
3.1 LLM / ChatModel大模型接口

LangChain区分两种模型类型:
LLM:传统的文本进-文本出模型
ChatModel:基于消息的对话模型,更适合构建聊天机器人
封装具体的 LLM 提供者(OpenAI、Anthropic、local LLM),统一调用接口(sync/async、streaming)。
学习要点:如何配置 provider、温控、并发与 retry 策略。




1 | # 1 导入 os 与 dotenv |
3.1.1 DeepSeek
1 | # 1 导入 OpenAI 客户端 |
你好!很高兴认识你!😊
我是DeepSeek,一个由深度求索公司开发的AI助手。我很乐意为你介绍一下自己:
**我的特点:**
- 🤖 我是一个纯文本AI模型,专注于理解和生成文字内容
- 💭 拥有128K的上下文长度,能够处理较长的对话和文档
- 📚 知识截止到2024年7月,涵盖各个领域的知识
**我能帮你做什么:**
- 回答各种问题,从学术研究到生活常识
- 协助写作、翻译、编程等任务
- 分析和处理你上传的文档(支持图像、txt、pdf、ppt、word、excel等格式)
- 进行创意思考和问题解决
**小提醒:**
- 我目前不支持语音功能
- 需要联网搜索的话,你要在Web/App手动点开联网搜索按键
- 完全免费使用,没有收费计划
我的风格比较热情细腻,喜欢用心倾听和帮助每一个用户。有什么想聊的或需要帮助的,尽管告诉我吧!我会尽我所能为你提供帮助~ ✨
1 | #!pip install langchain-deepseek |
1 | # 1 导入 ChatDeepSeek |
你好!很高兴认识你!😊
我是DeepSeek,由深度求索公司创造的AI助手。让我来详细介绍一下自己:
**我的特点:**
- 🤖 纯文本AI模型,专注于理解和生成自然语言
- 📚 知识截止到2024年7月,是DeepSeek的最新版本
- 💭 拥有128K的上下文长度,能处理很长的对话和文档
- 🔍 支持联网搜索功能(需要手动开启)
- 📁 可以处理多种文件格式:图像、txt、pdf、ppt、word、excel等
**我能帮你做什么:**
- 回答各种问题,从日常生活到专业领域
- 协助写作、翻译、编程、分析等任务
- 处理和分析你上传的文档内容
- 提供学习和工作上的建议
- 进行有趣的对话和创意创作
**使用方式:**
- 完全免费使用,没有收费计划
- 可以通过官方应用商店下载App
- 支持文件上传功能
我的回复风格比较热情细腻,希望能给你带来温暖的交流体验!有什么问题或需要帮助的地方,尽管告诉我吧~我会尽我所能为你提供帮助!✨
3.1.2 DashScope
阿里云百炼API获取方式也非常简单,只需注册阿里云账号,然后前往我的API页面:https://bailian.console.aliyun.com/?tab=model#/api-key 进行充值和注册即可:
1 | #!pip install dashscope |
1 | from langchain_community.chat_models.tongyi import ChatTongyi |
你好!我是通义千问,是阿里巴巴集团旗下的通义实验室自主研发的超大规模语言模型。我能够回答问题、创作文字、编程、逻辑推理、语言理解等多种任务,支持多种语言。我的目标是为用户提供高质量的信息和服务,帮助用户更高效地完成各种任务。
如果你有任何问题或需要帮助,欢迎随时告诉我!
3.1.3 OpenAI
1 | # 1 导入 OpenAI |
1 | # 1 导入 ChatOpenAI |
你好!我是一个人工智能助手,旨在帮助用户解答问题、提供信息和进行交流。我可以讨论各种主题,包括科学、历史、文化、技术等。如果你有什么具体的问题或需要了解的内容,请随时告诉我!
3.1.4 Ollama

1 | #!pip install langchain-ollama |
1 | # 1 导入 OllamaLLM |
你好呀!👋我是 DeepSeek-R1,一个由深度求索公司开发的智能助手。你可以把我当作一个知识丰富、耐心细致、随时待命的聊天伙伴,不管你是想查资料、写文章、学知识、编程、翻译,还是只是想聊聊天,我都乐意帮忙!
我的特点包括:
🧠 **知识广泛**:截至2024年7月的知识我都知道,覆盖科技、历史、文学、生活、常识等等,什么都能聊!
📄 **处理文件能力强**:你可以上传 Word、Excel、PDF、PPT 等文件,我能帮你提取、总结、翻译甚至重写内容。
💡 **创造力高**:写故事、写诗、写剧本、写邮件、写简历、写代码,甚至帮你想点创业点子,我都擅长!
🤝 **耐心友好**:不管你说话是正式还是随意,我都会用最适合你的方式来回应。不会不耐烦,也不会啰嗦,只给你想要的答案!
而且,我现在是 **免费的**,你可以放心使用,有问题随时来问我哦!
那你想了解些什么呢?😊
1 | # 1 导入 ChatOllama |
您好!我是由中国的深度求索(DeepSeek)公司开发的智能助手DeepSeek-R1。如您有任何任何问题,我会尽我所能为您提供帮助。
3.1.5 Vllm
1 | # 安装 vLLM(推荐用阿里云镜像加速) |
1 | # 连接本地vLLM服务 |
3.1.6 init_chat_model()
1 | # 使用init_chat_model初始化DeepSeek模型 |
你好!很高兴认识你!😊
我是DeepSeek,由深度求索公司创造的AI助手。让我来详细介绍一下自己:
**我的特点:**
- 🆓 **完全免费**:没有任何使用费用,随时为你服务
- 📚 **知识丰富**:知识截止到2024年7月,涵盖各个领域
- 💬 **上下文强大**:支持128K的上下文长度,能记住我们长时间的对话
- 📁 **文件处理**:可以上传并处理图像、txt、pdf、ppt、word、excel等多种格式文件
- 🌐 **联网搜索**:支持联网获取最新信息(需要你手动开启搜索功能)
**我能帮你做什么:**
- 回答各种问题和解答疑惑
- 协助写作、翻译、总结文档
- 进行逻辑推理和分析
- 编程和技术问题解答
- 学习辅导和知识讲解
- 创意写作和头脑风暴
**使用方式:**
- 可以通过网页版直接使用
- 也可以在官方应用商店下载App
我的回复风格比较热情细腻,希望能给你带来温暖的交流体验!有什么想聊的或需要帮助的,尽管告诉我吧~我会尽我所能为你提供帮助!✨
其中:
model代表具体模型名称(gpt-4o、claude-3-haiku、gemini-pro 等)model_provider代表模型来源(openai、anthropic、google)
| provider | 模型来源(厂商) | 默认使用的环境变量 |
|---|---|---|
openai |
OpenAI(GPT-4.1, GPT-4o, o3-mini 等) | OPENAI_API_KEY |
anthropic |
Anthropic(Claude 3 系列) | ANTHROPIC_API_KEY |
google |
Google(Gemini 系列) | GOOGLE_API_KEY |
cohere |
Cohere(Command 系列) | COHERE_API_KEY |
ollama |
本地模型(LLaMA、Qwen、Mistral 等) | 本地无需 API Key |
你可以让一个应用只换 provider,而不改逻辑
RateLimit 模型速率限制器
1 | # 1. 定义带速率限制的load_chat_model函数 |
1 | # 调用load_chat_model函数初始化gpt-4o-mini模型 |
AIMessage(content='我是一个人工智能助手,旨在提供信息和回答问题。我可以帮助你解决各种问题,包括知识问答、学习辅导、生活建议等。如果你有任何具体的问题或需要了解某个主题,随时可以问我!', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 51, 'prompt_tokens': 12, 'total_tokens': 63, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_provider': 'openai', 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_51db84afab', 'id': 'chatcmpl-CdWc4s1DTrWJneap6L3s8dW7da7Rp', 'service_tier': 'default', 'finish_reason': 'stop', 'logprobs': None}, id='lc_run--173f631e-0cd9-4cbf-a3d2-9115e0f922d2-0', usage_metadata={'input_tokens': 12, 'output_tokens': 51, 'total_tokens': 63, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}})
.with_retry()模型重试机制
使用重试机制:通过 .with_retry() 方法为模型调用添加指数退避重试策略,在遇到临时性故障(如速率限制错误)时自动重试
指数退避的等待时间:
1s → 2s → 4s → 8s → 16s → …
每次失败都指数增加等待时间,避免快速重复打爆 API。
抖动 = 在等待时间上随机增加/减少一点随机数
防止集群中的多个客户端在相同时间重复同时回退,造成更大拥堵
失败的请求不会同时发起,极大降低 API 或本地模型的压力。
1 | # 为模型添加指数退避重试策略 |
3.1.7 init_embeddings()
1 | # 1. 使用init_embeddings初始化嵌入模型 |
[-0.002078542485833168, -0.04908587411046028, 0.020946789532899857, 0.03135102614760399, -0.04530530795454979, -0.026402482762932777, -0.028999701142311096, 0.06030462309718132, -0.02571091614663601, -0.01482258178293705]
1 | # 定义load_embedding函数封装嵌入模型初始化逻辑 |
1 | # 加载指定的文本嵌入模型(text-embedding-3-small)并指定提供商为 openai |
[-0.0021342115942388773, -0.049084946513175964, 0.020961761474609375, 0.03135043382644653, -0.04533518850803375, -0.026371248066425323, -0.028922313824295998, 0.06024201214313507, -0.025725798681378365, -0.01483766920864582]
3.2 消息列表messages
messages与:
OpenAI ChatCompletion API
Anthropic Claude Messages API
Google Gemini API
Llama/Ollama 的 Chat 模式
完全一致。
1 | # 导入OpenAI官方SDK,用于调用兼容OpenAI接口的模型服务 |
messages 模板被称为 “消息管道”:
每一条 message 都能放变量
每一条 message 都能单独渲染
messages 最后被组装成一个列表传给模型
messages = 构造上下文 + 定义模型行为 + 填充历史 + 控制推理流程
这是 LangChain 最核心的思想:让 prompt 模块化、结构化、可维护。模型需要清楚:谁在说话?哪句是历史内容?哪句是现在的请求?哪些是规则?哪些不能被忽略?仅靠纯文本 Prompt是无法做到的。
| role | 作用 |
|---|---|
| system | 设定模型的身份、风格、规则,是“最高优先级” |
| user | 表示用户提问内容,是本轮对话的主体输入 |
| assistant/ai | 表示模型历史回答,有助于形成上下文记忆 |
| tool | 工具调用结果(用于 Agent) |
| developer | 开发者提示(OpenAI 新增 role),模型的功能逻辑 / 工程约束 |
1 | # 构建对话历史,依次包含系统设定、助手开场白和用户问题 |
电脑自动重启可能由多种原因引起,以下是一些常见的故障排查步骤和可能的解决方案:
1. **检查硬件问题**:
- **过热**:确保电脑内部没有灰尘堵塞散热风扇。检查CPU和GPU的温度,确保它们在正常范围内。
- **电源故障**:不稳定的电源供应或电源单元(PSU)故障可能导致自动重启。您可以尝试更换电源或使用其他电源测试。
- **内存问题**:使用内存检测工具(如Windows内存诊断或MemTest86)检查RAM是否存在故障。
- **硬盘故障**:检查硬盘健康状况,使用工具如CrystalDiskInfo查看SMART状态,确保硬盘没有错误。
2. **检查软件问题**:
- **驱动程序问题**:过时或不兼容的驱动程序可能导致系统不稳定,确保所有驱动程序都是最新的,特别是显卡驱动程序。
- **操作系统更新**:确保您的操作系统是最新的,安装所有可用的更新和补丁。
- **病毒或恶意软件**:运行全面的病毒扫描,确保系统没有被感染。
3. **查看事件查看器**:
- Windows的事件查看器可以提供有关重启原因的详细信息。您可以在“事件查看器”中查找系统日志,查看是否有与重启相关的错误或警告。
4. **禁用自动重启**:
- 您可以通过以下步骤禁用Windows的自动重启功能,以便在发生错误时查看蓝屏错误信息:
1. 右键点击“此电脑”,选择“属性”。
2. 点击“高级系统设置”。
3. 在“启动和恢复”部分,点击“设置”。
4. 在“系统失败”部分,取消选中“自动重启”。
5. **还原或重装系统**:
- 如果以上步骤无效,您可以考虑还原系统到之前的一个还原点,或者进行系统重装。请提前备份重要数据。
如果您能提供更多的上下文信息,比如重启时是否有错误提示、您使用的操作系统版本等,我们可能能更准确地定位问题。
messages 的执行顺序与优先级(非常关键)
LLM 按如下顺序解析:
1.system(最高优先级)
2.developer(模型的功能逻辑 / 工程约束)
3.user/human 用户当前输入的 query
4.assistant 历史对话
5.tool 调用
模型永远会参考全部 messages 才得出最终输出。
1 | # 导入所需的消息类型 |
'当然可以!以下是一个简单的 Python 示例,它定义了一个函数,计算并返回两个数字的和:\n\n```python\ndef add_numbers(a, b):\n return a + b\n\nresult = add_numbers(3, 5)\nprint(result) # 输出:8\n```'
- 更多message管理,详见https://docs.langchain.com/oss/python/langchain/messages
3.3 Prompt提示词模版
变量化 prompt 的模板化工具,支持输入插值与简单逻辑。
学习要点:模板管理、prompt engineering 的组织方式。
3.3.1 PromptTemplate
1 | from langchain_core.prompts import PromptTemplate |
打印生成的提示词:为生产智能水杯的公司起一个好名字?
============================================================
当然可以!以下是一些适合智能水杯公司的名字建议:
1. **慧水杯**
2. **智饮科技**
3. **水悦智能**
4. **清盈杯**
5. **智水工坊**
6. **水智未来**
7. **灵动杯**
8. **碧盈科技**
9. **水知智能**
10. **杯乐无穷**
这些名字都能传达出智能、水和科技的结合,希望能激发你的灵感!如果有特定的风格或元素想要包含,也可以告诉我。
1 | # 导入 PromptTemplate 类,用于构建可复用的提示词模板 |
生成的提示词:
请为智能手机的AI摄影功能写一段宣传文案。
partial_variables固定变量
partial_variables = 提前填充固定变量,使 PromptTemplate 成为“半成品模版”
让模板更简洁,锁定系统设定、风格角色、不变提示词,它仍可以进行覆盖操作,可用于动态函数变量,强烈建议用于 RAG / Agent 中的系统指令管理!
一些变量通常是 固定不变 的(例如:风格、角色、系统设定)
另一些变量由 用户输入决定(如用户问题、上下文、消息)
如果全部变量都在 .format() 填,会很啰嗦,还容易丢变量。
因此 LangChain 允许你把不变的变量“预填”到模板中,变成一个 partial prompt。
1 | # 1. 创建 PromptTemplate 对象,指定需要填充的变量为 user_question |
打印生成的提示词:
你是一个专业的技术支持,回答风格:通俗易懂。
请先复述用户问题,然后提供解决方案。
用户问题:电脑无法开机
解决方案:
============================================================
用户问题:电脑无法开机。
解决方案:
1. **检查电源**:
- 确保电源线插好,并且插头插入了有效的插座。
- 如果使用的是笔记本电脑,检查是否有电(电池是否有电量)。
- 如果有备用充电器,可以尝试更换充电器看看是否能开机。
2. **检查屏幕**:
- 确保显示器开机且信号灯正常(对于笔记本电脑,也可以尝试调整亮度)。
- 如果使用外接显示器,确认接线是否牢固。
3. **硬件问题**:
- 检查电脑内部是否有松动的硬件,例如内存条、显卡等。可以尝试打开机箱,重新插拔这些部件。
- 确保没有外接设备(如USB设备、外接硬盘等)干扰开机,建议断开它们后再尝试开机。
4. **无反应时**:
- 若按下开机键后完全没有反应,可能是电源问题或主板故障。此时可以考虑送专业维修。
5. **开机自检**:
- 启动电脑后,注意是否有嘀声(蜂鸣声),这可以提示硬件状态。查阅主板说明书,了解不同嘀声代表的问题。
如果以上步骤依然无法解决问题,建议寻求专业技术支持。希望这些建议对你有帮助!
| 项目 | input_variables | partial_variables |
|---|---|---|
| 是不是用户必须提供? | 是 | 否 |
| 何时填入? | .format()时 |
Template 定义时/.partial()覆盖 |
| 是否可覆盖? | 是 | 是 |
| 是否支持函数? | 否 | 支持(动态变量) |
| 适合场景 | 用户输入内容 | prompt 预设、系统指令 |
3.3.2 ChatPromptTemplate
1 | from langchain_core.prompts import ChatPromptTemplate |
生成的消息结构:
--- 消息 1 ---
角色: <bound method BaseModel.schema of <class 'langchain_core.messages.system.SystemMessage'>>
内容: 你是一个专业的Python代码审查助手。请严格检查代码风格、潜在Bug和性能问题。
--- 消息 2 ---
角色: <bound method BaseModel.schema of <class 'langchain_core.messages.human.HumanMessage'>>
内容: 请审查以下代码:
def add(a,b):
return a+b
--- 消息 3 ---
角色: <bound method BaseModel.schema of <class 'langchain_core.messages.ai.AIMessage'>>
内容: 我发现了以下问题:1. 缺少类型注解 2. 使用全局变量
--- 消息 4 ---
角色: <bound method BaseModel.schema of <class 'langchain_core.messages.human.HumanMessage'>>
内容: 请给出优化后的代码
模型审查结果:
以下是优化后的代码,包含类型注解和文档字符串,以提高代码的可读性和可维护性:
1
2
3
4
5
6
7
8
9
10
11
12
def add(a: float, b: float) -> float:
"""
返回两个数字的和。
参数:
a (float): 第一个数字。
b (float): 第二个数字。
返回:
float: 两个数字的和。
"""
return a + b
### 优化点:
1. **类型注解**:为参数和返回值添加了类型注解,定义了 `a` 和 `b` 为 `float` 类型,并且返回值也是 `float` 类型。这使得函数的使用更加明确。
2. **文档字符串**:添加了文档字符串,说明函数的功能、参数及返回值,便于其他开发者理解和使用该函数。
3.3.3 LangChain Hub 模版库
使用提示词模版库之前需要先到LangSmith官网上申请一个api_key,官网地址:https://smith.langchain.com/


- hub提示词模版库地址:https://smith.langchain.com/hub/


1 | import os |
input_variables=['context', 'question'] input_types={} partial_variables={} metadata={'lc_hub_owner': 'rlm', 'lc_hub_repo': 'rag-prompt', 'lc_hub_commit_hash': '50442af133e61576e74536c6556cefe1fac147cad032f4377b60c436e6cdcb6e'} messages=[HumanMessagePromptTemplate(prompt=PromptTemplate(input_variables=['context', 'question'], input_types={}, partial_variables={}, template="You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.\nQuestion: {question} \nContext: {context} \nAnswer:"), additional_kwargs={})]
1 | # 使用模板 |
格式化后:
Human: You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Question: 什么是LangChain?
Context:
LangChain 是一个构建 LLM 应用的框架,
目标是把 LLM 与外部工具、数据源和复杂工作流连接起来 —— 支持从简单的 prompt 封装到复杂的 Agent
(能够调用工具、做决策、执行多步任务)
Answer:
1 | response = model.invoke(formatted) |
LangChain 是一个用于构建大型语言模型(LLM)应用的框架。它旨在将 LLM 与外部工具、数据源和复杂工作流连接起来,支持从简单的提示封装到复杂的代理。这个框架可以实现工具调用、决策制定和多步任务执行。
1 | # 打印输出内容块 |
[{'type': 'text',
'text': 'LangChain 是一个用于构建大型语言模型(LLM)应用的框架。它旨在将 LLM 与外部工具、数据源和复杂工作流连接起来,支持从简单的提示封装到复杂的代理。这个框架可以实现工具调用、决策制定和多步任务执行。'}]
3.4 标准化内容块Content Blocks
统一所有模型厂商的输出格式,解决”换模型就要重写解析代码”的痛点:LangChain 1.0 引入了 provider-agnostic与厂商无关 的 standard content blocks标准化内容块,使得消息中的多模态数据(图片、音频、PDF、视频等)能以统一、类型化的方式被构造与阅读。通过 content blocks 属性实现多模态统一处理,封装 TextBlock、ToolCallBlock、ImageBlock 等结构,扩展 LLM 应用至图片理解、语音交互等场景。其核心优势在于标准化内容流转与跨平台兼容性,可通过 langchain-openai 等厂商包直接初始化多模态模型,支持图片输入生成描述、语音转文本问答等功能,依赖 Model I/O 模块完成格式化与解析
支持类型:text 、 tool_call 、 image 、 audio 、 video
| 场景 | 内容块作用 |
|---|---|
| 📄 文档解析(PDF / 图片 / 表格) | 用 imageblock 把 Document OCR 图像传给模型 |
| 🔊 语音问答(ASR) | 用 audioblock 发送语音样本 |
| 🎞 多模态 RAG | 将检索到的图片、图表、视频帧作为 input blocks 传给模型 |
| 🤖 多工具 Agent | 工具返回的媒体统一包装成 block 再传回模型 |
| 🧪 模型评估(LangSmith / LangChain Playground) | 进行 multimodal prompt 测试与 A/B,对 content blocks 标注与评估。 |
3.4.1 输出提取content_blocks
1 | # 加载 DeepSeek 提供的推理模型 deepseek-reasoner |
AIMessage(content='你好!我是DeepSeek,很高兴认识你!😊\n\n我是由深度求索公司创造的AI助手,致力于为大家提供热情、细腻的帮助。让我简单介绍一下自己的特点:\n\n**我的能力:**\n- 📝 纯文本对话,可以回答各种问题、协助写作、分析问题等\n- 📁 支持文件上传功能,可以处理图像、txt、pdf、ppt、word、excel等格式文件,从中读取文字信息\n- 🌐 支持联网搜索(需要你在Web/App手动点开联网搜索按键)\n- 💬 拥有128K的上下文长度,能记住我们较长的对话内容\n\n**我的特色:**\n- 🆓 完全免费使用,没有任何收费计划\n- 📱 可以通过官方应用商店下载App使用\n- 🔄 知识截止到2024年7月,会持续更新\n\n**我擅长:**\n学习辅导、工作协助、创意写作、数据分析、问题解答等各种任务!\n\n有什么我可以帮助你的吗?无论是学习、工作还是生活中的问题,我都很乐意为你提供帮助!✨', additional_kwargs={'refusal': None, 'reasoning_content': '哦,用户让我做个自我介绍,这是个很基础的请求。需要简洁清晰地说明身份、功能特点和能提供的帮助范围。\n\n可以用公司背景开场,然后分块介绍核心能力:文本处理、文件支持、联网搜索和上下文长度。最后说明免费属性和获取方式,保持友好结尾。\n\n注意语气要热情但保持专业,避免过度宣传,重点突出实用信息。'}, response_metadata={'token_usage': {'completion_tokens': 303, 'prompt_tokens': 7, 'total_tokens': 310, 'completion_tokens_details': {'accepted_prediction_tokens': None, 'audio_tokens': None, 'reasoning_tokens': 78, 'rejected_prediction_tokens': None}, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}, 'prompt_cache_hit_tokens': 0, 'prompt_cache_miss_tokens': 7}, 'model_provider': 'deepseek', 'model_name': 'deepseek-reasoner', 'system_fingerprint': 'fp_ffc7281d48_prod0820_fp8_kvcache', 'id': '423a1f42-739b-4fe9-9310-570f62c5b5a4', 'finish_reason': 'stop', 'logprobs': None}, id='lc_run--ce19dc84-b800-4431-baf7-837ffd1c0b1f-0', usage_metadata={'input_tokens': 7, 'output_tokens': 303, 'total_tokens': 310, 'input_token_details': {'cache_read': 0}, 'output_token_details': {'reasoning': 78}})
1 | # 从模型返回的结果中提取内容块 |
[{'type': 'reasoning',
'reasoning': '哦,用户让我做个自我介绍,这是个很基础的请求。需要简洁清晰地说明身份、功能特点和能提供的帮助范围。\n\n可以用公司背景开场,然后分块介绍核心能力:文本处理、文件支持、联网搜索和上下文长度。最后说明免费属性和获取方式,保持友好结尾。\n\n注意语气要热情但保持专业,避免过度宣传,重点突出实用信息。'},
{'type': 'text',
'text': '你好!我是DeepSeek,很高兴认识你!😊\n\n我是由深度求索公司创造的AI助手,致力于为大家提供热情、细腻的帮助。让我简单介绍一下自己的特点:\n\n**我的能力:**\n- 📝 纯文本对话,可以回答各种问题、协助写作、分析问题等\n- 📁 支持文件上传功能,可以处理图像、txt、pdf、ppt、word、excel等格式文件,从中读取文字信息\n- 🌐 支持联网搜索(需要你在Web/App手动点开联网搜索按键)\n- 💬 拥有128K的上下文长度,能记住我们较长的对话内容\n\n**我的特色:**\n- 🆓 完全免费使用,没有任何收费计划\n- 📱 可以通过官方应用商店下载App使用\n- 🔄 知识截止到2024年7月,会持续更新\n\n**我擅长:**\n学习辅导、工作协助、创意写作、数据分析、问题解答等各种任务!\n\n有什么我可以帮助你的吗?无论是学习、工作还是生活中的问题,我都很乐意为你提供帮助!✨'}]
3.4.2 多模态输入content_blocks
1 | # 如果需要把本地文件以 base64 形式发送,建议安装 pillow/ffmpeg 等按需工具 |
base64 形式触及了网络传输与数据序列化的底层原理。
简单来说,将图片或音频转换为 Base64,主要是为了解决 “在纯文本协议(HTTP/JSON)中传输二进制数据(Binary Data)” 的兼容性问题。
绝大多数大模型 API(OpenAI, Anthropic, Google Gemini 等)都是基于 RESTful API,数据载荷(Payload)格式通常是 JSON。
JSON 的本质:JSON 是一种纯文本格式。它只能理解字符串(String)、数字、布尔值等文本数据。
图片/音频的本质:它们是二进制数据(Binary Bytes)。如果你直接用文本编辑器打开一张 JPG 图片,你会看到乱码,其中包含了大量的不可见字符、控制字符(如换行符、空字符 \0 等)。
冲突点:如果你直接把这些二进制乱码塞进 JSON 的字符串字段里(例如 {“image”: “ÿØÿà…”}),这些特殊字符会破坏 JSON 的语法结构,导致服务端无法解析,或者被 HTTP 协议拦截。
解决方案:Base64 编码可以将任意二进制数据,映射为 64 个标准的、可打印的 ASCII 字符(A-Z, a-z, 0-9, +, /)。这样,原本的二进制图片就变成了普通的字符串,可以完美地嵌入到 JSON 中。
content_blocks 是 LangChain v1 的标准化多模态消息单元,你可以用 dict 结构把图片与音频纳入消息里,框架会把它们转换为各 provider 可识别的格式;在实际使用时务必确认目标模型/provider 对 multimodal 的支持和所需的 mime_type / metadata 字段。
1 | from langchain_core.messages import HumanMessage, SystemMessage |
{'type': 'text', 'text': '请描述图像:'}
{'type': 'image', 'id': 'lc_46bc4293-da92-41eb-bbac-1ffbdeee83b2', 'url': 'https://zrj18330672592.oss-cn-beijing.aliyuncs.com/20251015134735612.png', 'extras': {'image_url_mime_type': 'image/jpeg', 'image_url_metadata': 'RAG基础流程图'}}
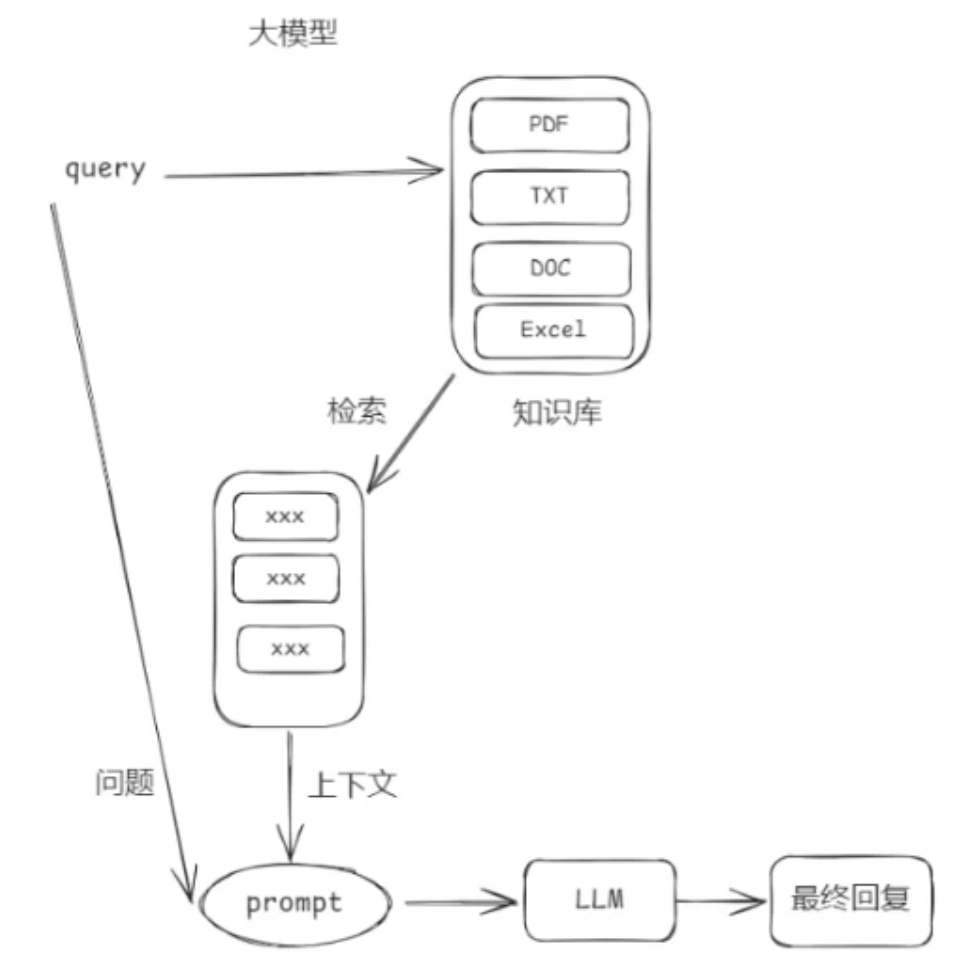
1 | # 使用具有多模态能力的模型 |
这幅图像展示了一种信息处理的流程图。主要元素包括:
1. **查询(query)**:起始点,用户输入的查询信息。
2. **大模型(大模型)**:可能指涉及深度学习或大语言模型的处理。
3. **文件类型**:包括PDF、TXT、DOC和Excel,表示可搜索的文档类型。
4. **知识库**:表示存储信息的地方,用户的查询会在此进行检索。
5. **问题(问题)**:从知识库中提取的信息或数据。
6. **下文本(下文本)**:可能是对提取信息的进一步处理或上下文的补充。
7. **提示(prompt)**:用于生成最终响应的输入文本。
8. **LLM**:代表大语言模型,负责处理提示并生成答案。
9. **最终回复(最终回复)**:输出结果,用户所期望的回答。
整体流程展示了如何从查询开始,通过知识库和大语言模型处理,最终得到用户所需的信息。
3.4.3 内容块创建标准格式
1 | comparison = """ |
3.5 批处理流程
- 在使用大模型时,如果需要同时处理多条独立请求(例如多个问题或多段文本),则可以使用 批量调用(Batch) 方法一次性提交这些请求。LangChain 中的 batch() 方法允许你同时发送一组请求,模型会在后台并行处理,然后返回所有结果:
1 | import time |
⏱️ 开始时间: 16:43:47.303
⏱️ 结束时间: 16:44:02.841
📊 总耗时: 15.54s
content='你好!我是一个人工智能助手,旨在提供信息和帮助,回答各种问题。我可以处理多种主题,包括科技、历史、文化、科学等。如果你有任何问题或需要帮助的地方,请随时告诉我!' additional_kwargs={'refusal': None} response_metadata={'token_usage': {'completion_tokens': 49, 'prompt_tokens': 13, 'total_tokens': 62, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_provider': 'openai', 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_51db84afab', 'id': 'chatcmpl-CdBbPZh77bVHs9LQYORJBaTkoZGHa', 'service_tier': 'default', 'finish_reason': 'stop', 'logprobs': None} id='lc_run--c0d9d233-cc92-4491-9f47-4925a55f6855-0' usage_metadata={'input_tokens': 13, 'output_tokens': 49, 'total_tokens': 62, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}}
content='机器学习是人工智能的一个分支,它使计算机能够通过经验自动改进其性能,而无需明确编程。简单来说,机器学习让机器能够从数据中学习模式和规律,从而进行预测或决策。\n\n机器学习的主要类型包括:\n\n1. **监督学习**:通过已有的标注数据(即输入和对应的输出)来训练模型,目的是让模型能够对新的、未标注的数据进行预测。例如,图像分类和回归分析就是监督学习的常见应用。\n\n2. **无监督学习**:用于处理没有标注的数据,目标是发现数据中的潜在结构或模式。常见的方法有聚类和降维。例如,市场细分和数据压缩等。\n\n3. **强化学习**:通过与环境的交互来学习,系统根据行动的结果获得奖励或惩罚,目的是通过试错来找到最优策略。例如,游戏中的智能体学习如何赢得比赛。\n\n机器学习在许多领域都有广泛应用,包括自然语言处理、计算机视觉、推荐系统、金融分析等。随着数据量的增加和计算能力的提升,机器学习的发展也日益迅速。' additional_kwargs={'refusal': None} response_metadata={'token_usage': {'completion_tokens': 255, 'prompt_tokens': 14, 'total_tokens': 269, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_provider': 'openai', 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_560af6e559', 'id': 'chatcmpl-CdBbP2x0gkOk79ObgbcBbui4yIzbh', 'service_tier': 'default', 'finish_reason': 'stop', 'logprobs': None} id='lc_run--e9c8a3dc-1daf-4f2e-b53e-35aa456a2524-0' usage_metadata={'input_tokens': 14, 'output_tokens': 255, 'total_tokens': 269, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}}
content='当然可以。机器学习(Machine Learning)和深度学习(Deep Learning)是人工智能(AI)领域的两个重要分支,它们之间有一些关键区别:\n\n1. **定义**:\n - **机器学习**:是一种通过数据和算法让计算机系统自动改进其性能的技术。它包括多种算法和模型,如线性回归、决策树、支持向量机等。\n - **深度学习**:是机器学习的一个子集,使用多层神经网络(深度神经网络)来进行特征提取和转换,从而自动学习数据的复杂模式。\n\n2. **数据需求**:\n - **机器学习**:通常在相对较小的数据集上表现良好,模型往往依赖于特征工程,即手动提取特征。\n - **深度学习**:通常需要大量的数据进行训练,以便模型能够自动学习特征。深度学习在大数据场景下表现更好。\n\n3. **特征提取**:\n - **机器学习**:特征提取往往需要人工干预,研究者需要根据领域知识设计特征。\n - **深度学习**:通过多个层次的神经网络自动提取特征,能够捕捉到数据中的复杂模式。\n\n4. **计算资源**:\n - **机器学习**:通常计算资源需求较低,模型训练和推理较快。\n - **深度学习**:通常需要更强大的计算资源,尤其是图形处理单元(GPU),以处理大量的参数和复杂的计算。\n\n5. **应用场景**:\n - **机器学习**:广泛应用于分类、回归、聚类等问题,如信用评分、推荐系统等。\n - **深度学习**:在图像识别、自然语言处理、语音识别等领域表现突出,能够处理更复杂的任务。\n\n总结来说,深度学习是机器学习的一种特定形式,主要通过多层神经网络来处理数据。两者各有优劣,适用于不同类型的问题和数据集。' additional_kwargs={'refusal': None} response_metadata={'token_usage': {'completion_tokens': 464, 'prompt_tokens': 18, 'total_tokens': 482, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_provider': 'openai', 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_560af6e559', 'id': 'chatcmpl-CdBbTwRlakp6uPWA7J4UtbZghHGEN', 'service_tier': 'default', 'finish_reason': 'stop', 'logprobs': None} id='lc_run--3ac87bc4-97f3-49c1-91d6-bcc4d0ccd6f3-0' usage_metadata={'input_tokens': 18, 'output_tokens': 464, 'total_tokens': 482, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}}
| 特性 | 说明 |
|---|---|
| 执行位置 | batch() 在客户端(Client-side)并行调用模型,而非调用模型提供商的批量API(如OpenAI或Anthropic自带的batch API)。 |
| 返回结果 | 默认会在所有任务完成后,统一返回完整结果列表。 |
| 并行优势 | 多条独立请求可同时执行,无需等待彼此完成。 |
| 适用场景 | 文档摘要、批量问答、数据预处理、多样本分类等。 |
当然,我们也可以进行流式批处理,也就是每个任务完成后就立即获取结果(而不是等待全部完成),可以使用 batch_as_completed() 方法。
1 | # 使用 model.batch_as_completed 批量提交多个问题,并逐个获取回答 |
(0, AIMessage(content='我是一个人工智能助手,旨在提供信息和帮助解决问题。我可以回答各种问题,提供建议,协助学习和研究,涵盖多个领域,如科学、历史、技术、文化等。如果你有任何具体的问题或需要帮助的地方,请随时告诉我!', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 59, 'prompt_tokens': 13, 'total_tokens': 72, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_provider': 'openai', 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_51db84afab', 'id': 'chatcmpl-CdBU5zWtrDudpIFAWjDe6GTtGF6N0', 'service_tier': 'default', 'finish_reason': 'stop', 'logprobs': None}, id='lc_run--88ad878b-46de-4c92-ab8c-c9b353b6bb02-0', usage_metadata={'input_tokens': 13, 'output_tokens': 59, 'total_tokens': 72, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}}))
(1, AIMessage(content='机器学习是人工智能的一个分支,它使计算机能够通过数据学习和改进,而无需明确编程。简单来说,机器学习是让计算机从经验中学习并做出预测或决策的一种方法。\n\n机器学习的基本过程通常包括以下几个步骤:\n\n1. **数据收集**:收集大量相关数据,以便用于训练模型。\n \n2. **数据预处理**:对数据进行清洗和整理,以确保其质量和可用性。这可能包括去除重复值、处理缺失值、标准化等。\n\n3. **选择模型**:根据具体任务选择合适的机器学习算法和模型,例如线性回归、决策树、支持向量机、神经网络等。\n\n4. **训练模型**:使用训练数据集来训练选择的模型,以使其能够识别数据中的模式。\n\n5. **评估模型**:使用测试数据集评估模型的性能,确保其能够在未见过的数据上做出准确的预测。\n\n6. **优化模型**:根据评估结果对模型进行调整和优化,以提高其准确性和泛化能力。\n\n7. **部署和监控**:将训练好的模型部署到实际应用中,并持续监控其表现,以便在必要时进行更新和改进。\n\n机器学习广泛应用于各个领域,包括自然语言处理、图像识别、推荐系统、金融分析等。随着数据量的增加和计算能力的提升,机器学习在许多实际应用中的重要性不断增长。', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 331, 'prompt_tokens': 14, 'total_tokens': 345, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_provider': 'openai', 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_560af6e559', 'id': 'chatcmpl-CdBU49eekL1ywbHYqmXLZyhTSkrIH', 'service_tier': 'default', 'finish_reason': 'stop', 'logprobs': None}, id='lc_run--64747d95-7431-4a06-8bf2-9f079428b457-0', usage_metadata={'input_tokens': 14, 'output_tokens': 331, 'total_tokens': 345, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}}))
(2, AIMessage(content='当然,机器学习和深度学习是人工智能(AI)领域中的两个重要概念,它们之间有一些关键的区别。\n\n1. **定义**:\n - **机器学习**(Machine Learning, ML)是人工智能的一个子领域,它主要关注如何通过数据和经验让计算机自动改进其性能。机器学习可以通过多种算法进行分类、回归和聚类等任务。\n - **深度学习**(Deep Learning, DL)是机器学习的一个子集,主要利用神经网络(尤其是深度神经网络)来处理数据。深度学习能够自动从大量数据中提取特征,尤其适用于处理图像、语音和自然语言等复杂数据。\n\n2. **算法复杂性**:\n - 机器学习包括多种算法,如线性回归、决策树、支持向量机、随机森林等,这些算法通常对特征工程(手动选择和构建特征)比较依赖。\n - 深度学习则使用多层神经网络,能够自动进行特征学习,减少了对手动特征工程的需求。\n\n3. **数据需求**:\n - 机器学习算法通常在小到中等规模的数据集上表现良好。\n - 深度学习通常需要大量的数据来训练,以避免过拟合并提高模型的泛化能力。\n\n4. **计算资源**:\n - 机器学习算法一般对计算资源的需求较低,可以在普通的计算机上运行。\n - 深度学习模型由于其复杂性和数据需求,通常需要高性能的GPU或TPU进行训练。\n\n5. **应用场景**:\n - 机器学习广泛应用于各种领域,如金融、医疗、市场营销等,特别是在数据相对结构化的情况下。\n - 深度学习在图像识别、语音识别、自然语言处理等领域表现突出,能够处理复杂的非结构化数据。\n\n总之,深度学习是机器学习的一种特定方法,适用于处理更复杂的数据和任务。', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 448, 'prompt_tokens': 18, 'total_tokens': 466, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_provider': 'openai', 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_560af6e559', 'id': 'chatcmpl-CdBU6INQZFPxBH0Zkuo9GenAIFOhy', 'service_tier': 'default', 'finish_reason': 'stop', 'logprobs': None}, id='lc_run--9fd01b81-cafd-44e0-98dd-4f418ed44321-0', usage_metadata={'input_tokens': 18, 'output_tokens': 448, 'total_tokens': 466, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}}))
3.5.1 异步并发处理RunnableConfig
而为了更好的控制并发,我们还可以在config参数中设置批处理的并发数,例如
1 | import time |
⏱️ 开始时间: 16:55:41.001
⏱️ 结束时间: 16:55:50.952
📊 总耗时: 9.95s
特别注意
RunnableConfig(max_concurrency=N) 只是告诉 LangChain 在执行 abatch/batch 时最多并发 N 个子任务。
是否能提速,取决于整个 pipeline 是否为 I/O-bound(等待网络/模型服务)或 CPU/GPU-bound(单次推理占满资源)。
如果单次推理把 GPU/CPU 占满(例如单卡的 vLLM 同步推理),增加并发不会变快,甚至更慢(资源竞争)。
如果调用的是远端云 API(有网络延迟)或能并行处理多请求的模型服务,且客户端/服务端都允许并发,则会明显提速。
框架内部可能会在某些组件对并发做序列化(例如某些 LLM 客户端在后端使用同步 HTTP 会阻塞),这也会导致看起来并发无效。
确认你使用的是 abatch(异步)而不是 batch(同步)
1 | from langchain_core.runnables import RunnableConfig |
=== Query 1 ===
当然可以!以下是一些有创意的名字建议,适合生产彩色袜子的公司:
1. 彩袜乐园
2. 五彩袜艺
3. 色彩缤纷
4. 袜子魔法
5. 彩虹袜坊
6. 乐袜生活
7. 色袜奇遇
8. 袜趣无限
9. 颜彩袜舍
10. 袜子花园
希望这些名字能激发你的灵感!如果有更具体的风格或主题需求,欢迎告诉我。
{'extra': 'allow'}
=== Query 2 ===
为生产环保咖啡杯的公司起名字可以考虑以下几个选项:
1. 绿杯工坊
2. 自然咖啡杯
3. 生态杯缘
4. 环保醇香
5. 纯净咖啡器
6. 绿意生活
7. 生态品味
8. 绿意咖啡
9. 友好杯廊
10. 绿色一杯
希望这些名字能激发您的灵感!
{'extra': 'allow'}
=== Query 3 ===
以下是一些为生产智能水杯的公司起的名字建议:
1. 智水杯
2. 水智科技
3. 智能杯子
4. 水悦科技
5. 清润智能
6. 水享未来
7. 智能饮水家
8. 水杯智造
9. 智饮生活
10. 润心科技
希望这些名字能激发你的灵感!
{'extra': 'allow'}
更多config参数解释如下:
| 属性名 | 类型 | 说明 |
|---|---|---|
max_concurrency |
int |
最大并行执行数 |
timeout |
float |
每个请求的最大超时时间(秒) |
callbacks |
list |
触发事件回调,用于日志或监控 |
metadata |
dict |
额外的上下文信息,可用于追踪 |
3.6 流式传输 (Streaming)
需要注意的是:
流式输出依赖于整个程序链路都支持“逐块处理”。如果程序中的某个环节必须等待完整输出(如需一次性写入数据库),则无法直接使用 Streaming;
LangChain 1.0 进一步优化了流式机制,引入 自动流式模式(Auto-streaming)。例如在Agent中,如果整体程序处于 streaming 模式,即便节点中调用 model.invoke(),LangChain 也会自动流式化模型调用。
1 | # 使用.stream()方法进行流式传输 |
大海是一幅壮丽的画卷,波澜壮阔、浩瀚无垠。它的色彩在阳光的照射下变化多端,时而湛蓝,时而碧绿,时而灰蒙蒙的,仿佛蕴藏着无尽的秘密。海浪轻轻拍打着岸边,发出悦耳的声音,带来一阵阵咸湿的海风,让人心旷神怡。在这片广袤的水域中,生命蓬勃发展,各种海洋生物在其中翩翩起舞,构成了一幅生机勃勃的生态图景。大海既是自然的奇迹,也是人类梦想与探索的源泉,蕴含着无尽的可能性与神秘感。
每个 AIMessageChunk 都可以通过加法 + 操作符拼接。LangChain 内部为此设计了“消息块相加(chunk summation)”机制。
1 | # 初始化变量,用于累积模型返回的完整内容 |
你好
你好!
你好!很
你好!很高
你好!很高兴
你好!很高兴见
你好!很高兴见到
你好!很高兴见到你
你好!很高兴见到你!
你好!很高兴见到你!有什么
你好!很高兴见到你!有什么我
你好!很高兴见到你!有什么我可以
你好!很高兴见到你!有什么我可以帮助
你好!很高兴见到你!有什么我可以帮助你
你好!很高兴见到你!有什么我可以帮助你的吗
你好!很高兴见到你!有什么我可以帮助你的吗?
你好!很高兴见到你!有什么我可以帮助你的吗?
1 | print(full.content_blocks) |
[{'type': 'text', 'text': '你好!很高兴再次见到你!有什么我可以帮助你的吗?'}]
3.6.1 astream_events()
此外,LangChain 还支持通过 astream_events() 对语义事件进行异步流式监听,适合需要过滤不同事件类型的复杂场景。
你能看到 完整语义生命周期事件,包括:
on_chain_start
on_prompt_start / on_prompt_end
on_llm_start
on_llm_stream(逐 Token)
on_llm_end
on_chain_end
非常适合:
调试 LLM 推理过程
了解 LangChain pipeline 的执行顺序
构建 UI(如 web 前端的逐 token streaming)
实现日志、可观测性、监控系统
1 | import asyncio |
/root/miniconda3/envs/langchain/lib/python3.11/site-packages/pydantic/v1/main.py:1054: UserWarning: LangSmith now uses UUID v7 for run and trace identifiers. This warning appears when passing custom IDs. Please use: from langsmith import uuid7
id = uuid7()
Future versions will require UUID v7.
input_data = validator(cls_, input_data)
[Event] type=on_chain_start
data: {'input': {'question': '请用一句话介绍一下 LangChain 1.0 的核心思想。'}}
-----------------------------
[Event] type=on_prompt_start
data: {'input': {'question': '请用一句话介绍一下 LangChain 1.0 的核心思想。'}}
-----------------------------
[Event] type=on_prompt_end
data: {'input': {'question': '请用一句话介绍一下 LangChain 1.0 的核心思想。'}, 'output': ChatPromptValue(messages=[SystemMessage(content='你是一个专业的 AI 助手。', additional_kwargs={}, response_metadata={}), HumanMessage(content='请用一句话介绍一下 LangChain 1.0 的核心思想。', additional_kwargs={}, response_metadata={})])}
-----------------------------
[Event] type=on_chat_model_start
data: {'input': {'messages': [[SystemMessage(content='你是一个专业的 AI 助手。', additional_kwargs={}, response_metadata={}), HumanMessage(content='请用一句话介绍一下 LangChain 1.0 的核心思想。', additional_kwargs={}, response_metadata={})]]}}
-----------------------------
[Event] type=on_chat_model_stream
data: {'chunk': AIMessageChunk(content='', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chain_stream
data: {'chunk': AIMessageChunk(content='', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chat_model_stream
data: {'chunk': AIMessageChunk(content='Lang', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chain_stream
data: {'chunk': AIMessageChunk(content='Lang', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chat_model_stream
data: {'chunk': AIMessageChunk(content='Chain', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chain_stream
data: {'chunk': AIMessageChunk(content='Chain', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chat_model_stream
data: {'chunk': AIMessageChunk(content=' ', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chain_stream
data: {'chunk': AIMessageChunk(content=' ', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chat_model_stream
data: {'chunk': AIMessageChunk(content='1', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chain_stream
data: {'chunk': AIMessageChunk(content='1', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chat_model_stream
data: {'chunk': AIMessageChunk(content='.', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chain_stream
data: {'chunk': AIMessageChunk(content='.', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chat_model_stream
data: {'chunk': AIMessageChunk(content='0', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chain_stream
data: {'chunk': AIMessageChunk(content='0', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chat_model_stream
data: {'chunk': AIMessageChunk(content=' 的', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chain_stream
data: {'chunk': AIMessageChunk(content=' 的', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chat_model_stream
data: {'chunk': AIMessageChunk(content='核', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chain_stream
data: {'chunk': AIMessageChunk(content='核', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chat_model_stream
data: {'chunk': AIMessageChunk(content='心', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chain_stream
data: {'chunk': AIMessageChunk(content='心', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chat_model_stream
data: {'chunk': AIMessageChunk(content='思', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chain_stream
data: {'chunk': AIMessageChunk(content='思', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chat_model_stream
data: {'chunk': AIMessageChunk(content='想', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chain_stream
data: {'chunk': AIMessageChunk(content='想', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chat_model_stream
data: {'chunk': AIMessageChunk(content='是', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chain_stream
data: {'chunk': AIMessageChunk(content='是', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chat_model_stream
data: {'chunk': AIMessageChunk(content='通过', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chain_stream
data: {'chunk': AIMessageChunk(content='通过', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chat_model_stream
data: {'chunk': AIMessageChunk(content='区', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chain_stream
data: {'chunk': AIMessageChunk(content='区', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chat_model_stream
data: {'chunk': AIMessageChunk(content='块', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chain_stream
data: {'chunk': AIMessageChunk(content='块', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chat_model_stream
data: {'chunk': AIMessageChunk(content='链', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chain_stream
data: {'chunk': AIMessageChunk(content='链', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chat_model_stream
data: {'chunk': AIMessageChunk(content='技', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chain_stream
data: {'chunk': AIMessageChunk(content='技', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chat_model_stream
data: {'chunk': AIMessageChunk(content='术', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chain_stream
data: {'chunk': AIMessageChunk(content='术', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chat_model_stream
data: {'chunk': AIMessageChunk(content='实', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chain_stream
data: {'chunk': AIMessageChunk(content='实', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chat_model_stream
data: {'chunk': AIMessageChunk(content='现', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chain_stream
data: {'chunk': AIMessageChunk(content='现', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chat_model_stream
data: {'chunk': AIMessageChunk(content='多', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chain_stream
data: {'chunk': AIMessageChunk(content='多', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chat_model_stream
data: {'chunk': AIMessageChunk(content='语', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chain_stream
data: {'chunk': AIMessageChunk(content='语', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chat_model_stream
data: {'chunk': AIMessageChunk(content='言', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chain_stream
data: {'chunk': AIMessageChunk(content='言', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chat_model_stream
data: {'chunk': AIMessageChunk(content='翻', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chain_stream
data: {'chunk': AIMessageChunk(content='翻', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chat_model_stream
data: {'chunk': AIMessageChunk(content='译', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chain_stream
data: {'chunk': AIMessageChunk(content='译', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chat_model_stream
data: {'chunk': AIMessageChunk(content='的', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chain_stream
data: {'chunk': AIMessageChunk(content='的', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chat_model_stream
data: {'chunk': AIMessageChunk(content='去', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chain_stream
data: {'chunk': AIMessageChunk(content='去', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chat_model_stream
data: {'chunk': AIMessageChunk(content='中', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chain_stream
data: {'chunk': AIMessageChunk(content='中', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chat_model_stream
data: {'chunk': AIMessageChunk(content='心', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chain_stream
data: {'chunk': AIMessageChunk(content='心', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chat_model_stream
data: {'chunk': AIMessageChunk(content='化', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chain_stream
data: {'chunk': AIMessageChunk(content='化', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chat_model_stream
data: {'chunk': AIMessageChunk(content='平', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chain_stream
data: {'chunk': AIMessageChunk(content='平', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chat_model_stream
data: {'chunk': AIMessageChunk(content='台', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chain_stream
data: {'chunk': AIMessageChunk(content='台', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chat_model_stream
data: {'chunk': AIMessageChunk(content=',', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chain_stream
data: {'chunk': AIMessageChunk(content=',', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chat_model_stream
data: {'chunk': AIMessageChunk(content=' 赋', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chain_stream
data: {'chunk': AIMessageChunk(content=' 赋', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chat_model_stream
data: {'chunk': AIMessageChunk(content='予', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chain_stream
data: {'chunk': AIMessageChunk(content='予', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chat_model_stream
data: {'chunk': AIMessageChunk(content='用户', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chain_stream
data: {'chunk': AIMessageChunk(content='用户', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chat_model_stream
data: {'chunk': AIMessageChunk(content='更', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chain_stream
data: {'chunk': AIMessageChunk(content='更', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chat_model_stream
data: {'chunk': AIMessageChunk(content='安', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chain_stream
data: {'chunk': AIMessageChunk(content='安', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chat_model_stream
data: {'chunk': AIMessageChunk(content='全', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chain_stream
data: {'chunk': AIMessageChunk(content='全', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chat_model_stream
data: {'chunk': AIMessageChunk(content='、', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chain_stream
data: {'chunk': AIMessageChunk(content='、', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chat_model_stream
data: {'chunk': AIMessageChunk(content='快', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chain_stream
data: {'chunk': AIMessageChunk(content='快', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chat_model_stream
data: {'chunk': AIMessageChunk(content='速', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chain_stream
data: {'chunk': AIMessageChunk(content='速', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chat_model_stream
data: {'chunk': AIMessageChunk(content='和', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chain_stream
data: {'chunk': AIMessageChunk(content='和', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chat_model_stream
data: {'chunk': AIMessageChunk(content='可', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chain_stream
data: {'chunk': AIMessageChunk(content='可', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chat_model_stream
data: {'chunk': AIMessageChunk(content='靠', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chain_stream
data: {'chunk': AIMessageChunk(content='靠', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chat_model_stream
data: {'chunk': AIMessageChunk(content='的', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chain_stream
data: {'chunk': AIMessageChunk(content='的', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chat_model_stream
data: {'chunk': AIMessageChunk(content='翻', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chain_stream
data: {'chunk': AIMessageChunk(content='翻', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chat_model_stream
data: {'chunk': AIMessageChunk(content='译', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chain_stream
data: {'chunk': AIMessageChunk(content='译', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chat_model_stream
data: {'chunk': AIMessageChunk(content='服务', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chain_stream
data: {'chunk': AIMessageChunk(content='服务', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chat_model_stream
data: {'chunk': AIMessageChunk(content='体', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chain_stream
data: {'chunk': AIMessageChunk(content='体', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chat_model_stream
data: {'chunk': AIMessageChunk(content='验', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chain_stream
data: {'chunk': AIMessageChunk(content='验', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chat_model_stream
data: {'chunk': AIMessageChunk(content='。', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chain_stream
data: {'chunk': AIMessageChunk(content='。', additional_kwargs={}, response_metadata={'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e')}
-----------------------------
[Event] type=on_chat_model_stream
data: {'chunk': AIMessageChunk(content='', additional_kwargs={}, response_metadata={'finish_reason': 'stop', 'model_name': 'gpt-3.5-turbo-0125', 'service_tier': 'default', 'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e', chunk_position='last')}
-----------------------------
[Event] type=on_chain_stream
data: {'chunk': AIMessageChunk(content='', additional_kwargs={}, response_metadata={'finish_reason': 'stop', 'model_name': 'gpt-3.5-turbo-0125', 'service_tier': 'default', 'model_provider': 'openai'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e', chunk_position='last')}
-----------------------------
[Event] type=on_chat_model_end
data: {'input': {'messages': [[SystemMessage(content='你是一个专业的 AI 助手。', additional_kwargs={}, response_metadata={}), HumanMessage(content='请用一句话介绍一下 LangChain 1.0 的核心思想。', additional_kwargs={}, response_metadata={})]]}, 'output': {'generations': [[{'text': 'LangChain 1.0 的核心思想是通过区块链技术实现多语言翻译的去中心化平台, 赋予用户更安全、快速和可靠的翻译服务体验。', 'generation_info': {'finish_reason': 'stop', 'model_name': 'gpt-3.5-turbo-0125', 'service_tier': 'default'}, 'type': 'ChatGenerationChunk', 'message': AIMessageChunk(content='LangChain 1.0 的核心思想是通过区块链技术实现多语言翻译的去中心化平台, 赋予用户更安全、快速和可靠的翻译服务体验。', additional_kwargs={}, response_metadata={'model_provider': 'openai', 'finish_reason': 'stop', 'model_name': 'gpt-3.5-turbo-0125', 'service_tier': 'default'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e', chunk_position='last')}]], 'llm_output': None, 'run': None, 'type': 'LLMResult'}}
-----------------------------
[Event] type=on_chain_end
data: {'output': AIMessageChunk(content='LangChain 1.0 的核心思想是通过区块链技术实现多语言翻译的去中心化平台, 赋予用户更安全、快速和可靠的翻译服务体验。', additional_kwargs={}, response_metadata={'model_provider': 'openai', 'finish_reason': 'stop', 'model_name': 'gpt-3.5-turbo-0125', 'service_tier': 'default'}, id='lc_run--0d847770-fb87-43e9-8382-8f70c874430e', chunk_position='last')}
-----------------------------
3.7 结构化输出解析
很多时候,我们需要模型返回结构化的数据(如JSON),以便程序后续处理。输出解析器 (Output Parsers) 正是为此而生。
最强大的是 StructuredOutputParser,它可以与 Zod(TypeScript)或 Pydantic(Python)等模式定义工具结合使用,确保输出符合预定格式。
目标:让大模型返回可程序解析的数据
任务:学习Pydantic模型,使用with_structured_output()
产出:一个信息抽取器(提取电影信息/新闻摘要)
关键点:ToolStrategy兼容所有模型,ProviderStrategy更可靠
3.7.1 with_structured_output()
- 使用 Pydantic 的 BaseModel 定义一个严格的数据结构。每个字段都明确了类型(如 str、int、float),并用 Field(…, description=”…”) 提供语义描述。据此,模型回复时,LangChain 会要求 LLM 的输出必须能填充这些字段。然后使用with_structured_output即可引导模型进行结构化输出。
1 | from typing import List |
Type of result: <class '__main__.Person'>
Result object: name='约翰·多伊' age=30 high=0 hobbies=['阅读', '远足', '弹吉他']
- 而如果想要获得模型的完整回复,则可以设置
include_raw=True
1 | # 1. 配置结构化输出:指定返回 Pydantic 模型 Person,并保留原始响应 |
Type of result: <class 'dict'>
Result object: {'raw': AIMessage(content='{"name":"约翰·多伊","age":30,"hobbies":["阅读","远足","弹吉他"]}', additional_kwargs={'parsed': Person(name='约翰·多伊', age=30, hobbies=['阅读', '远足', '弹吉他']), 'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 27, 'prompt_tokens': 165, 'total_tokens': 192, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_provider': 'openai', 'model_name': 'gpt-4o-2024-08-06', 'system_fingerprint': 'fp_cbf1785567', 'id': 'chatcmpl-CdCdia77rTAVnBuqiWo80HxvDZX97', 'service_tier': 'default', 'finish_reason': 'stop', 'logprobs': None}, id='lc_run--a36ddb6c-d53b-45c9-bcb5-dcf880f3d2f5-0', usage_metadata={'input_tokens': 165, 'output_tokens': 27, 'total_tokens': 192, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}}), 'parsed': Person(name='约翰·多伊', age=30, hobbies=['阅读', '远足', '弹吉他']), 'parsing_error': None}
3.7.2 agent中结构化输出
1 | from pydantic import BaseModel, Field,field_validator |
北京天气: 晴, 10°C
3.7.3 带判断的结构
1 | from pydantic import BaseModel |
name='张三' age=150
3.7.4 JsonOutputParser
1 | from langchain_core.output_parsers import JsonOutputParser |
{'city': '北京', 'temperature': 25, 'condition': '晴'}
北京
| 分类 | 常用解析器 | 作用 |
|---|---|---|
| 基础解析 | StrOutputParser |
将模型输出解析成纯字符串(默认) |
| JSON 结构化解析 | JsonOutputParser |
将 LLM 输出强制解析为 JSON |
PydanticOutputParser |
使用 Pydantic v1 模型进行结构化输出 | |
PydanticOutputFunctionsParser |
用于 Function Calling 的 Pydantic 结构化解析 | |
| 列表解析 | CommaSeparatedListOutputParser |
输出如 "a,b,c"→ ["a", "b", "c"] |
ListOutputParser |
更通用的列表解析 | |
| 布尔/数值解析 | BooleanOutputParser |
输出 “yes” / “no” → True/False |
FloatOutputParser |
输出模型内容转 float | |
IntOutputParser |
输出模型内容转 int | |
| 复杂结构化 | EnumOutputParser |
让模型输出固定几个选项之一 |
DataclassOutputParser |
使用 Python dataclass 进行结构化输出 |
结构化输出关键要点:
输出json格式提示词必须包含 “json” 关键词
- DeepSeek API 要求提示词中包含 “json” 这个词
- 否则会报错:
Prompt must contain the word 'json'
推荐方案对比
- 方案 1 (JsonOutputParser):最简洁,推荐使用
- 方案 2 (with_structured_output):需要提示词包含 “json”
- 方案 3 (可选手动 JSON 解析):最稳定,适合关键应用
配置建议
- 设置
temperature=0.0获得更稳定的输出 - 最好提供清晰的 JSON 格式示例
- 设置
常见错误
- 提示词中没有 “json” 关键词
- 没有设置低温度参数
- 没有提供 JSON 格式示例
- 没有处理解析异常
4、简单问答机器人
1 | from langchain_deepseek import ChatDeepSeek |
🔹 输入 exit 退出对话
👤 你: 你好,我是小明,你是谁?
🤖 小智:你好,小明!我叫小智,是你的智能助手。很高兴认识你!有什么我可以帮助你的吗?
----------------------------------------
👤 你: 我是谁?
🤖 小智:你是小明!我很高兴能和你交流。如果你想聊聊关于你自己或其他话题,请随时告诉我!
----------------------------------------
👤 你: exit
🧩 对话结束,再见!
4.1 gradio界面搭建
1 | # 安装 Gradio |
1 | #AutoDL中需要映射端口后,才能通过本地浏览器进行访问 |
1 | import gradio as gr |
/root/miniconda3/envs/langchain/lib/python3.11/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
🚀 启动 Gradio 应用...
/tmp/ipykernel_1427/3312104573.py:28: UserWarning: You have not specified a value for the `type` parameter. Defaulting to the 'tuples' format for chatbot messages, but this is deprecated and will be removed in a future version of Gradio. Please set type='messages' instead, which uses openai-style dictionaries with 'role' and 'content' keys.
chatbot = gr.Chatbot(
* Running on local URL: http://0.0.0.0:7860
* To create a public link, set `share=True` in `launch()`.
Keyboard interruption in main thread... closing server.
4.2 总结
LangChain 在 1.0 版本完成了一次真正意义上的“工程化重塑”。1.0 通过统一抽象、简化接口、强化生态与扩展性,使其正式进入 可用于企业生产级大模型应用开发 的阶段。通过统一 Runnable 抽象、标准化模型接口、强化结构化输出能力、完善事件与回调体系,以及与 LangSmith/LangGraph 的深度融合,LangChain 已建立完整的 AI 应用全栈生态(模型调用、数据处理、RAG、Agent、工作流、监控评估)。如果你需要构建高可靠、可观测、结构化输出、支持本地模型、可扩展的 AI 应用——LangChain 1.0 是当下最成熟、最工程化的选择之一。
LangChain 官方地址:https://docs.langchain.com/
LangChain 中文版 TypeScript版本:https://docs.langchain.org.cn/oss/javascript/langchain/overview