LangChain1.0搭建Agent智能体应用实战
1、Agent核心概念与技术架构
Agent智能体是一种以大语言模型(LLM)为”大脑”,能够自主感知环境、进行推理规划,并调用外部工具执行复杂任务的系统。它不仅仅是简单的程序,而是具备一系列高级特征的复杂系统。根据LangChain框架的定义,Agent的核心是以大语言模型(LLM)作为其推理引擎,并依据LLM的推理结果来决定如何与外部工具进行交互以及采取何种具体行动。这种架构将LLM的强大语言理解与生成能力,与外部工具的实际执行能力相结合,从而突破了单一LLM的知识限制和功能边界。Agent的本质可以被理解为一种高级的提示工程(Prompt Engineering)应用范式,开发者通过精心设计的提示词模板,引导LLM模仿人类的思考与执行方式,使其能够自主地分解任务、选择工具、调用工具并整合结果,最终完成复杂的任务。
Agent(智能体)已超越传统AI模型,成为能够自主完成多步骤复杂任务的智能数字助手。其核心特征在于自主性增强、执行能力和持续学习。


1.1 能力维度对比
| 对比维度 | 传统AI模型 | Agent智能体 |
|---|---|---|
| 交互能力 | 被动响应用户输入 | 主动感知环境变化 |
| 决策模式 | 基于概率预测 | 基于目标导向的主动规划 |
| 执行能力 | 仅生成文本/内容 | 能够调用工具、访问外部系统 |
| 学习方式 | 静态知识更新 | 动态记忆积累和经验反思 |
| 任务处理 | 单次对话完成 | 支持多步骤、复杂任务序列 |
| 自主程度 | 高度依赖人类指导 | 具备一定程度的自主决策能力 |
2、Agent的核心特征
- Agent智能体通常具备以下几个核心特征,这些特征共同构成了其强大的能力基础:
2.1 自主性 (Autonomy)
- 自主性是Agent最核心的特征之一,指的是Agent能够在没有人类直接干预的情况下,独立地完成任务的感知、规划、决策和行动的全过程。在LangChain框架中,这种自主性体现在Agent能够根据用户的输入,自动判断是否需要调用外部工具,选择哪个工具,以及如何组织调用参数。例如,当用户询问”北京的天气怎么样?”时,Agent能够自主识别出这是一个需要实时信息查询的任务,并自动调用天气查询工具来获取答案,而无需开发者显式地编写”如果问题是关于天气,则调用天气API”这样的硬编码逻辑。这种自主性使得Agent能够处理更加开放和动态的问题,极大地提升了应用的灵活性和智能水平。
2.2 感知能力 (Perception)
- 感知能力是指Agent获取和理解环境信息的能力。在基于LLM的Agent中,环境信息主要以文本形式存在,包括用户的输入、工具的输出以及系统状态等。Agent通过其底层的LLM来解析和理解这些文本信息,从中提取关键指令、实体和上下文。例如,在接收到用户问题后,Agent需要感知问题的意图和关键实体(如地点、时间、人物),以便决定后续的行动。LangChain框架通过提供标准化的消息格式(如
HumanMessage,AIMessage)和工具描述机制,为Agent的感知能力提供了坚实的基础,使其能够清晰地理解来自不同来源的信息。
2.3 推理与规划 (Reasoning & Planning)
- 推理与规划是Agent智能的核心。Agent需要能够分析任务目标,并将其分解为一系列可执行的子步骤。LangChain中的Agent,特别是基于ReAct(Reasoning and Acting)范式的Agent,展现了强大的推理和规划能力。ReAct框架要求LLM在每一步都生成一个”思考”(Thought)过程,解释其当前的理解和下一步的计划,然后生成一个”行动”(Action),即调用某个工具。这个过程会循环进行,直到Agent认为已经收集了足够的信息来回答原始问题。例如,面对一个复杂的多步骤数学问题,Agent会先规划出解题步骤,如”首先计算A,然后用A的结果计算B”,并按此规划逐步调用计算工具来完成任务。
2.4 行动能力 (Action)
- 行动能力是指Agent执行具体操作以影响环境的能力。在LangChain框架中,Agent的行动能力主要通过调用外部工具(Tools)来实现。这些工具可以是API调用、数据库查询、代码执行器,甚至是其他Agent。Agent通过LLM来决定调用哪个工具,并生成符合工具要求的输入参数。工具执行后,其输出结果会作为新的环境信息反馈给Agent,供其进行下一步的推理和决策。这种”思考-行动-观察”的循环,使得Agent能够与外部世界进行有效的交互,从而完成各种复杂的实际任务,如信息检索、数据处理和自动化流程控制。
2.5 学习能力 (Learning)
一个真正的智能体不仅仅是执行预设的程序,它还应该具备从经验中学习并不断优化自身行为的能力。这种学习能力通常通过强化学习、反馈机制或记忆系统来实现。智能体在每次行动后,会观察行动的结果,并根据结果(例如,用户的反馈或环境的奖励/惩罚信号)来调整其内部的决策模型或策略。例如,如果一个智能体推荐的商品被用户频繁购买,它就会学习到这种推荐是有效的;反之,如果推荐被用户忽略或拒绝,它就会调整其推荐策略。这种持续学习和优化的能力使得智能体能够随着时间的推移变得越来越”聪明”,更好地适应复杂多变的环境。


3、Agent技术架构核心
理解 Agent(智能体) 最难的地方在于理解它”如何自主决策“。在LangChain 1.0框架中,Agent不再只是一个简单的问答机器人,它更像是一个”拥有万能工具箱的超级项目经理”。
LLM(大模型) = 大脑(项目经理):它负责思考、规划、决定下一步做什么,但它不能联网,也不能算复杂的数学(如果不借助工具)。
Tools(工具) = 手脚(执行专员):比如谷歌搜索(负责看世界)、计算器(负责算数)、数据库(负责查档案)。
Agent = 大脑 + 手脚 + 循环机制:把大脑和手脚结合起来,通过不断的”思考-行动-观察”循环来解决问题。


现代Agent的技术架构由五个核心模块构成,形成完整的”感知-思考-行动”闭环。
感知模块 (Perception):负责接收文本、图像、语音等多模态输入。
认知中枢 (Brain/Planning):基于大语言模型(LLM)和检索增强生成(RAG)技术,进行推理和决策,弥补LLM无法获取实时信息和执行具体操作的缺陷。
记忆系统 (Memory):通过短期记忆维持对话连贯,长期记忆积累经验与偏好。
工具生态 (Tools):通过API调用、数据库访问等方式与外部系统交互。
执行引擎 (Action):负责执行具体任务并反馈结果。
这一机制使得Agent能够构建一个完整的执行闭环:环境感知 → 任务规划 → 工具调用 → 执行反馈 → 自我反思 → 优化调整,从而在复杂环境中持续学习和改进。
4、Agent与LangChain结合机制
- LangChain 1.0通过将Agent的决策与LangGraph的图式执行相结合,提供了生产级的Agent运行时。其结合机制体现在以下几个方面:
4.1 核心结合点:create_agent + LangGraph
create_agent作为上层统一入口,其内部实现依赖于LangGraph。当调用create_agent时,LangChain会自动构建一个基于ReAct(推理+行动)范式的图结构。这个图包含了Agent决策、工具调用、状态更新等核心节点,并通过边来控制逻辑流转。这种设计将Agent的”思考”过程映射为图的遍历,使得整个执行流程变得透明、可控。

LangChain 1.0 的 create_agent 通过这 9 个核心参数,实现了从快速原型到生产部署的全覆盖,开发者可根据场景灵活组合。
create_agent 的核心价值在于它通过 “三要素 + 三扩展” 的极简抽象,彻底重构了 Agent 的开发范式。所谓三要素,即模型(Model)、工具(Tools)与提示词(System Prompt),这三者构成了 Agent 的”灵魂”——决定了它能思考什么、能做什么以及行为边界何在。而三扩展——中间件(Middleware)、内存管理(Memory)与状态管理(State)——则构建了 Agent 的”神经系统”,使其具备生产级应用所需的可靠性、可观测性与可维护性。
这一设计将开发者从繁琐的 ReAct 循环手写、工具调用异常处理、上下文压缩等底层细节中解放出来,转而采用声明式编程模式:只需描述”Agent 应该做什么”,框架自动编译为高效、可靠、安全的执行计划。其本质是 LangGraph 的编译器前端 ,将高层意图转换为优化的图结构,自动集成持久化、流式输出、断点恢复等运行时能力。
这种架构带来了三重革命性影响:首先,开发效率提升 10 倍,10 行代码即可构建一个可投产的智能客服或数据分析 Agent;其次,运维成本降低 60%,中间件机制将 PII 检测、人工审批、自动重试等横切关注点解耦,无需侵入业务代码;最后,可扩展性实现质的飞跃,通过 TypedDict 扩展 State,可无缝集成用户画像、多模态输入、性能监控等复杂场景。
| 参数 | 类型 | 必填 | 默认值 | 核心作用 | 最佳实践 |
|---|---|---|---|---|---|
model |
str/实例 | ✅ | - | 推理引擎 | 生产环境实例化配置 |
tools |
list | ✅ | [] | 执行能力 | 描述清晰,按需添加 |
system_prompt |
str | ❌ | None | 行为准则 | 明确角色和约束 |
middleware |
list | ❌ | [] | 功能扩展 | 组合日志、安全、摘要 |
checkpointer |
Saver | ❌ | None | 短期记忆 | 生产用 PostgresSaver |
store |
Store | ❌ | None | 长期记忆 | 跨会话用 PostgresStore |
state_schema |
TypedDict | ❌ | AgentState | 扩展状态 | 用 TypedDict 非 Pydantic |
context_schema |
TypedDict | ❌ | None | 动态上下文 | 配合 middleware 使用 |
response_format |
BaseModel | ❌ | None | 结构化输出 | API 对接场景启用 |
1 | from langchain.agents import create_agent |
4.2 ReAct范式与执行循环
ReAct(Reasoning + Acting)范式强调”推理—行动—观察”的闭环:Agent先形成Thought(推理),据此选择并调用工具(Action),再吸收工具返回的Observation(观察),进入下一轮决策。闭环在达到最终答案、迭代上限或时间上限时终止。在LangGraph中,这一闭环由状态机与检查点驱动,保证每次行动的原子性、状态的可见性与轨迹的可回放性。并且推理与规划不是代码逻辑,而是LLM的生成行为,关键的 Thought: 步骤并非由确定性算法执行,而是prompt触发LLM生成推理文本。模型能力是ReAct性能的天花板

Agent的认知循环本质上是一个闭环反馈系统。每一次”行动”的执行结果都会作为新的输入反馈到系统,影响下一轮的”思考”和”行动”。这种反馈机制使得Agent能够动态调整策略,应对不确定的环境和复杂任务。在LangChain中,这一循环被实现为:
**Thought (推理)**:大模型基于当前输入和历史记录进行思考,决定下一步行动。
**Action (行动)**:大模型选择一个工具并构造输入参数,形成一个
AgentAction。**Observation (观察)**:工具被执行,其返回结果作为观察值,并与
AgentAction一起被添加到中间步骤(intermediate_steps)中。循环决策:Agent将新的观察结果纳入上下文,进入下一轮”推理-行动”循环,直至达到最终目标或触发终止条件(如达到最大迭代次数)。
5、工具(Tools)的集成与调用
工具是Agent与外部世界交互的桥梁。在LangChain中,工具的name、description和args_schema至关重要,它们共同决定了模型是否以及如何选择和调用工具。一个设计良好的工具描述是提示工程的关键部分。
工具注册:通过
@tool装饰器或继承BaseTool类来定义工具。工具调用:Agent在决策时,会根据工具描述选择最合适的工具。执行引擎负责调用该工具并处理其返回结果或异常。
安全与治理:在生产环境中,应对工具的调用进行严格的风险控制,如速率限制、权限隔离、输入校验等,这些可以通过中间件或在工具实现中直接加入。
LangChain内置工具列表:https://python.langchain.com/docs/integrations/tools/
| 工具名 | Python 类 | 作用 |
|---|---|---|
| python_repl | PythonREPLTool |
执行 Python |
| shell | ShellTool |
执行命令行 |
| human | HumanTool |
人工输入 |
| requests_get | RequestsGetTool |
GET 请求 |
| requests_post | RequestsPostTool |
POST 请求 |
| bing_search | BingSearchRun |
Bing 搜索 |
| serper | GoogleSerperRun |
Google 搜索 |
| tavily_search | TavilySearchResults |
Tavily 搜索 |
| web_loader | WebBaseLoader |
网页加载 |
| apify | ApifyActorTool |
网页爬虫 |
| gmail | Gmail 工具 | 邮件管理 |
| google_calendar | GoogleCalendar 工具 | 日程管理 |
| python_ast | PythonAstREPLTool | 数据分析安全执行器 |
| read_file | ReadFileTool | 读取文件 |
| write_file | WriteFileTool | 写入文件 |
| sql_db_query | QuerySQLDatabaseTool | SQL 查询 |
| retriever | VectorStoreTool | RAG 检索 |
1 | # 环境依赖版本 |
langchain 1.0.8
langchain-chroma 1.0.0
langchain-classic 1.0.0
langchain-community 0.4.1
langchain-core 1.0.7
langchain-deepseek 1.0.0
langchain-experimental 0.4.0
langchain-google-genai 3.0.3
langchain-mcp-adapters 0.1.13
langchain-ollama 1.0.0
langchain-openai 1.0.2
langchain-tavily 0.2.13
langchain-text-splitters 1.0.0
1 | #python 版本 |
Python 3.11.14
1 | # 加载环境 |
1 | # 1. 定义带速率限制的load_chat_model函数 |
5.1 使用网络搜索工具
1 | #!pip install langchain-tavily |
优先使用支持 Function Calling 的模型(如 GPT-4o、Qwen)
1 | # 1.导入相关库 |
1 | result['messages'][-1].content |
'根据搜索结果,2024年诺贝尔物理学奖得主已经揭晓:\n\n**2024年诺贝尔物理学奖得主:**\n\n1. **约翰·霍普菲尔德 (John J. Hopfield)** - 美国科学家,普林斯顿大学教授\n2. **杰弗里·欣顿 (Geoffrey E. Hinton)** - 英国裔加拿大科学家,多伦多大学教授\n\n**获奖理由:**\n他们因"为利用人工神经网络进行机器学习做出的基础性发现和发明"而获奖。\n\n**主要贡献:**\n- 约翰·霍普菲尔德创建了一种联想记忆方法,可以存储和重构图像或其他类型的数据模式\n- 杰弗里·欣顿发明了一种可以自动发现数据中属性的方法,可用于识别图片中的特定元素等任务\n\n这两位科学家利用统计物理的基本概念设计了人工神经网络,构建了机器学习的基础,相关技术已被广泛应用于粒子物理、材料科学、天体物理以及日常生活中的人脸识别和语言翻译等领域。'
5.2 自定义tool工具使用
1 | #!pip install langchain-experimental |
5.2.1 使用@tool装饰器来定义工具
@tool装饰器是LangChain中最简单、最直观的工具创建方式。它通过装饰器语法将普通Python函数转换为Agent可调用的工具,适合快速原型开发和简单工具实现。
技术概述:
自动参数推断:基于函数签名自动生成工具的参数schema
简化配置:只需提供工具名称和描述即可快速创建
同步执行:默认支持同步函数调用,异步需要单独定义
快速验证:适合概念验证和快速迭代开发
核心优势:
代码简洁,一行装饰器即可完成工具注册
无需复杂的类继承和配置
与Python函数无缝集成,开发效率高
适用场景:
快速原型验证
简单工具实现
开发测试阶段
1 | from langchain_core.tools import tool |
[HumanMessage(content='帮我计算12乘以6等于多少?', additional_kwargs={}, response_metadata={}, id='4affefe8-ac01-43be-8bf0-69a03e522620'),
AIMessage(content='', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 17, 'prompt_tokens': 58, 'total_tokens': 75, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_provider': 'openai', 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_51db84afab', 'id': 'chatcmpl-Cfjik4cyFztADP2KyZz5aKCzJQXOF', 'service_tier': 'default', 'finish_reason': 'tool_calls', 'logprobs': None}, id='lc_run--82b0f1bf-b44e-499e-9c5c-b42c06ee4393-0', tool_calls=[{'name': 'multiply', 'args': {'a': 12, 'b': 6}, 'id': 'call_uxZ021ueCjN0msopABE4jnEy', 'type': 'tool_call'}], usage_metadata={'input_tokens': 58, 'output_tokens': 17, 'total_tokens': 75, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}}),
ToolMessage(content='72', name='multiply', id='ceec0bf1-7652-4604-bf81-22618a74ed68', tool_call_id='call_uxZ021ueCjN0msopABE4jnEy'),
AIMessage(content='12乘以6等于72。', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 9, 'prompt_tokens': 83, 'total_tokens': 92, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_provider': 'openai', 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_560af6e559', 'id': 'chatcmpl-CfjilH3C1GrmmIx1D2zuu0QNIZWZG', 'service_tier': 'default', 'finish_reason': 'stop', 'logprobs': None}, id='lc_run--8a6fbd4a-1a4c-47c4-b94d-2a1e4f5587eb-0', usage_metadata={'input_tokens': 83, 'output_tokens': 9, 'total_tokens': 92, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}})]
1 | response["messages"][-1].content |
'12乘以6等于72。'
使用LangGraph Studio 查看Agent结构
![image-20260131124511288]()
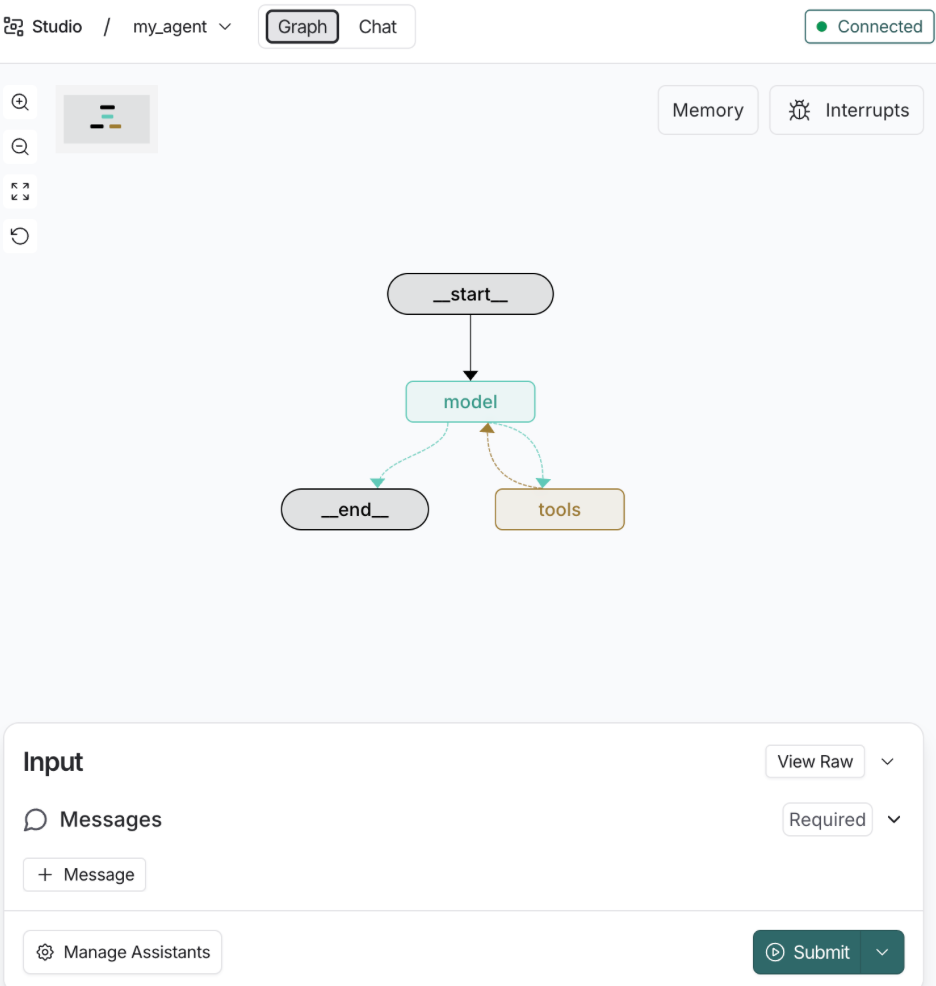
5.2.2 基础用法:StructuredTool.from_function()
- 这是最常用的方式,通过函数直接创建结构化工具,支持同步和异步双重实现。
StructuredTool.from_function()方法提供了更强大的工具创建能力,支持完整的参数校验和异步执行,适合生产环境使用。
技术概述:
强类型校验:支持Pydantic模型进行参数验证
异步支持:通过
coroutine参数支持异步函数完整元数据:支持name、description、return_direct等完整配置
生产就绪:内置错误处理和参数校验机制
核心特性:
参数schema完全可控,支持复杂数据结构
异步执行支持,适合I/O密集型操作
完整的工具元数据配置
生产环境级别的错误处理
适用场景:
生产环境工具开发
需要严格参数校验的场景
异步操作需求
企业级应用
1 | from pydantic import BaseModel, Field |
参数校验失败:2 validation errors for DivideInput
dividend
Field required [type=missing, input_value={'a': 10, 'b': 2}, input_type=dict]
For further information visit https://errors.pydantic.dev/2.11/v/missing
divisor
Field required [type=missing, input_value={'a': 10, 'b': 2}, input_type=dict]
For further information visit https://errors.pydantic.dev/2.11/v/missing
除法结果:5.0
5.2.3 继承StructuredTool
通过继承StructuredTool类创建工具提供了最大的灵活性和控制力,适合复杂业务逻辑和状态管理需求。
技术概述:
完全自定义:可以完全控制工具的所有行为
状态管理:支持工具内部状态维护
复杂逻辑:适合实现复杂的业务逻辑
企业级特性:支持完整的生命周期管理
核心能力:
完整的Pydantic集成和类型系统
自定义错误处理和重试机制
工具内部状态管理
复杂的业务逻辑封装
适用场景:
企业级复杂工具开发
需要状态管理的工具
复杂的业务逻辑封装
高性能要求的场景
1 | import os |
================================[1m Human Message [0m=================================
请帮我查订单 ORD-2024-1234 的详细状态,包括商品明细
--------------------------------------------------
==================================[1m Ai Message [0m==================================
Tool Calls:
query_order (call_LeB3cv96YvuLlrVUILZmNQWC)
Call ID: call_LeB3cv96YvuLlrVUILZmNQWC
Args:
order_id: ORD-2024-1234
include_details: True
--------------------------------------------------
=================================[1m Tool Message [0m=================================
Name: query_order
{"status": "已发货", "express": "顺丰", "amount": 299, "items": ["商品A × 2", "商品B × 1"]}
--------------------------------------------------
==================================[1m Ai Message [0m==================================
您的订单 **ORD-2024-1234** 的状态如下:
- **订单状态**:已发货
- **快递公司**:顺丰
- **订单金额**:299元
- **商品明细**:
- 商品A × 2
- 商品B × 1
如果您还有其他问题,欢迎随时询问!
--------------------------------------------------
核心要点总结
参数校验:始终使用 args_schema 定义 Pydantic 模型,确保输入合法
异步优先:为网络 I/O 操作提供 _arun 实现,提升 Agent 并发性能
文档清晰:description 字段是 LLM 选择工具的唯一依据,必须详细描述功能和参数
返回值控制:return_direct=True 适合无需 LLM 润色的确定性格式数据
调试友好:使用 tool.invoke() 单独测试工具,确保逻辑正确后再集成到 Agent
5.2.4 三种方法对比与选择
| 特性 | @tool装饰器 | StructuredTool.from_function() | 继承StructuredTool |
|---|---|---|---|
| 代码简洁度 | ⭐⭐⭐⭐⭐(极简) | ⭐⭐⭐⭐(简洁) | ⭐⭐(较繁琐) |
| 参数控制 | 自动推断,弱控制 | 支持args_schema,强校验 |
完全自定义 Schema |
| 异步支持 | ❌(需单独定义 async 函数) | ✅(通过coroutine参数) |
✅(实现_arun方法) |
| 元数据定制 | 有限(name, description) | 中等(name, description, return_direct) | 完全定制(所有属性) |
| 适用场景 | 快速原型、简单工具 | 生产环境、需要参数校验的场景 | 复杂业务逻辑、状态管理 |
| 类型提示 | 依赖函数签名 | 结合 Pydantic 强类型 | 完整的 Pydantic 集成 |
5.3 多工具使用
1 | from langchain.agents import create_agent |
用户: 北京和上海的天气怎么样?
Agent: 当前天气情况如下:
- 北京:晴朗,气温25°C
- 上海:多云,气温28°C
--------------------------------------------------
用户: 如果北京气温是25度,上海是28度,那么北京的温度比上海低多少度?
Agent: 北京的温度比上海低3度。
--------------------------------------------------
5.3.1 查看运行流程
1 | import getpass |
开始任务: 查询一下北京和上海气温,并且计算一下北京的温度比上海低多少度?
╭──────────────────────────────────────────── Step 1: 决策 (Decision) ────────────────────────────────────────────╮ │ 🤔 AI 思考决定:需要调用外部工具 │ │ 🔧 工具名称: get_weather │ │ 📥 输入参数: {'city': '北京'} │ ╰─────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯
╭──────────────────────────────────────────── Step 1: 决策 (Decision) ────────────────────────────────────────────╮ │ 🤔 AI 思考决定:需要调用外部工具 │ │ 🔧 工具名称: get_weather │ │ 📥 输入参数: {'city': '上海'} │ ╰─────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯
╭────────────────────────────────────────────── Step 2: 执行与观察 ───────────────────────────────────────────────╮ │ 👀 工具返回结果 (Observation): │ │ 上海的天气是:多云,气温28°C │ ╰─────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯
╭──────────────────────────────────────────── Step 3: 决策 (Decision) ────────────────────────────────────────────╮ │ 🤔 AI 思考决定:需要调用外部工具 │ │ 🔧 工具名称: add │ │ 📥 输入参数: {'a': 25, 'b': -28} │ ╰─────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯
╭────────────────────────────────────────────── Step 4: 执行与观察 ───────────────────────────────────────────────╮ │ 👀 工具返回结果 (Observation): │ │ -3.0 │ ╰─────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯
╭──────────────────────────────────────── Step 5: 最终回复 (Final Answer) ────────────────────────────────────────╮ │ 北京的气温是25°C,上海的气温是28°C。北京的温度比上海低3°C。 │ ╰─────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯
5.4 mcp接入LangChain
1 | # 安装 MCP 适配器(关键依赖)\MCP 服务器开发库(如需自定义工具) |
检查 Node.js
- node –version
检查 npm/npx
- npx –version
手动安装 MCP 服务器包
- npm install -g @amap/amap-maps-mcp-server
5.4.1 本地部署的mcp服务
1 | # mcp_server.py |
1 | from langchain_mcp_adapters.client import MultiServerMCPClient # 导入 MCP 客户端 |
mcp_server.py
✅ 成功加载 3 个 MCP 工具: ['add', 'multiply', 'power']
/root/miniconda3/envs/langchain/lib/python3.11/site-packages/pydantic/v1/main.py:1054: UserWarning: LangSmith now uses UUID v7 for run and trace identifiers. This warning appears when passing custom IDs. Please use: from langsmith import uuid7
id = uuid7()
Future versions will require UUID v7.
input_data = validator(cls_, input_data)
Agent: 北京的天气是晴朗,气温为25°C;上海的天气是多云,气温为28°C。北京的温度比上海低3°C。
5.4.2 远程连接mcp服务器
魔搭社区高德地图mcp服务器:https://www.modelscope.cn/mcp/servers/@amap/amap-maps/tools
申请高德地图的api地址:https://console.amap.com/dev/key/app




| 字段 | 类型 | 说明 | 示例 |
|---|---|---|---|
transport |
string | 传输方式 | "stdio","streamable_http" , "SSE" |
command |
string | 启动命令 | "python", "npx", "node" |
args |
list | 命令参数 | ["mcp_server.py"] |
- LangChain官网mcp接入连接:https://docs.langchain.com/oss/javascript/langchain/mcp#model-context-protocol-mcp
1 | from langchain_mcp_adapters.client import MultiServerMCPClient |
正在连接 MCP 服务器...
成功加载 15 个工具: ['add', 'multiply', 'power', 'maps_regeocode', 'maps_geo', 'maps_ip_location', 'maps_weather', 'maps_search_detail', 'maps_bicycling', 'maps_direction_walking', 'maps_direction_driving', 'maps_direction_transit_integrated', 'maps_distance', 'maps_text_search', 'maps_around_search']
--- 开始测试 Agent ---
[HumanMessage]:
请帮我搜索查询一下北京市今天的天气,并计算一下最大温差是多少度?
[AIMessage]:
>>> 调用工具详情: [{'name': 'maps_weather', 'args': {'city': '北京市'}, 'id': 'call_1l5n0x40mVEXeZmjcxT8cIHZ', 'type': 'tool_call'}]
[ToolMessage]:
{
"city": "北京市",
"forecasts": [
{
"date": "2025-11-24",
"week": "1",
"dayweather": "阴",
"nightweather": "晴",
"daytemp": "11",
"nighttemp": "-2",
"daywind": "西北",
"nightwind": "西北",
"daypower": "1-3",
"nightpower": "1-3",
"daytemp_float": "11.0",
"nighttemp_float": "-2.0"
},
{
"date": "2025-11-25",
"week": "2",
"dayweather": "晴",
"nightweather": "多云",
"daytemp": "7",
"nighttemp": "-2",
"daywind": "西南",
"nightwind": "西南",
"daypower": "1-3",
"nightpower": "1-3",
"daytemp_float": "7.0",
"nighttemp_float": "-2.0"
},
{
"date": "2025-11-26",
"week": "3",
"dayweather": "多云",
"nightweather": "多云",
"daytemp": "7",
"nighttemp": "-2",
"daywind": "西北",
"nightwind": "西北",
"daypower": "1-3",
"nightpower": "1-3",
"daytemp_float": "7.0",
"nighttemp_float": "-2.0"
},
{
"date": "2025-11-27",
"week": "4",
"dayweather": "晴",
"nightweather": "多云",
"daytemp": "5",
"nighttemp": "-3",
"daywind": "西南",
"nightwind": "西南",
"daypower": "1-3",
"nightpower": "1-3",
"daytemp_float": "5.0",
"nighttemp_float": "-3.0"
}
]
}
[AIMessage]:
>>> 调用工具详情: [{'name': 'add', 'args': {'a': 11, 'b': 2}, 'id': 'call_IsbYMjmqAMKDOs6SmPR7yAKP', 'type': 'tool_call'}]
[ToolMessage]:
13.0
[AIMessage]:
今天北京市的天气情况如下:
- **白天气温**:11°C,天气:阴
- **夜间气温**:-2°C,天气:晴
因此,今天的最大温差为 **13°C**。
5.4.3 HTTP传输配置
1 | MCP_CONFIG = { |
5.4.4 对比表
| 特性 | 标准 MCP 配置 | MultiServerMCPClient 配置 |
|---|---|---|
| 顶层结构 | {"mcpServers": {...}} |
{"server_name": {...}} |
| 服务器配置 | 嵌套在 stdio 字段中 |
直接在服务器对象中 |
command 位置 |
server.stdio.command |
server.command |
args 位置 |
server.stdio.args |
server.args |
| 适用场景 | Claude Desktop 等应用 | LangChain MCP 适配器 |
5.5 工具调用错误或者乱调情况
5.5.1 使用Tool Router(最有效)
Tool Router是解决工具调用混乱的最有效方法,它通过专门的工具路由机制来精确匹配用户意图与可用工具。
技术实现:
意图识别:使用专门的分类器识别用户意图
工具匹配:基于意图选择最合适的工具
参数验证:在调用前验证参数有效性
错误处理:提供优雅的降级策略
1 | # 定义意图分类系统提示 |
5.5.2 引入”意图分类模型”(工程最佳方案)
意图分类模型通过机器学习方法识别用户请求的真实意图,从根本上解决工具误用问题。
技术优势:
高精度识别:基于大量训练数据的准确意图识别
动态适应:能够适应新的用户表达方式
多维度分析:综合考虑语义、上下文、用户历史等因素
1 | # 创建一个意图识别模型 |
5.5.3 动态加载工具(避免上下文过长)
动态工具加载机制根据当前对话上下文和用户意图,按需加载相关工具,避免一次性加载所有工具导致的上下文过长问题。
- 模型根据”意图”动态读取特定工具,不把所有工具一次性喂给模型。
实现策略:
1 | # 通过Tool 工具分组 |
5.5.4 统一工具规范(提高准确率)
通过强制化Schema和规范化提示词,建立统一的工具使用规范。
规范要求:
✔ 工具名称必须动词开头
✔ 每个工具使用标准化schema
✔ 工具描述必须包含三件事:能干什么、不能干什么、典型输入示例
1 |
|
5.5.5 采用”工具过滤Prompt”修饰模型行为(成本最低)
通过系统Prompt显式指导模型行为,设置工具使用边界。
Prompt示例:
1 | agent = create_agent( |
5.5.6 层次化/多级Agent架构
通过层次化Agent架构降低单个Agent的工具复杂度,提高系统稳定性。
架构优势:
模块化设计:每个Agent专注于特定领域
降低复杂度:单个Agent工具数量可控
提高稳定性:错误隔离和容错能力更强
1 | from langchain.tools import tool |
1 | from langchain.agents import create_agent |
1 | # 6. 路由智能体函数 |
1 | res = router_agent("请帮我搜索一下今年Google最新的大模型版本的发布会") |
[Router] 检测到意图: search
1 | # 7. 测试智能体 |
====== 用户问题 ======
请帮我搜索一下今年Google最新的大模型版本的发布会
====== Agent 回复 ======
[Router] 检测到意图: search
content='模拟搜索结果:你搜索了 Google 最新大模型版本发布会 2024' name='search_web' id='d55b6d93-550f-4aea-80eb-cce21d708618' tool_call_id='call_00_rl0VUFHw8VyAf0XqdrySG9F0'
====== 用户问题 ======
帮我解析一下这个PDF:/root/files/contract.pdf
====== Agent 回复 ======
[Router] 检测到意图: pdf
content='模拟 PDF 内容:从 /root/files/contract.pdf 中解析出的内容' name='extract_pdf_text' id='1f9b5ad6-d7b5-4c95-af51-c4148e10c934' tool_call_id='call_00_Tc7vQp5YcH8SL6uFUMRp19lo'
====== 用户问题 ======
执行一个SQL:select * from products limit 5
====== Agent 回复 ======
[Router] 检测到意图: database
content='模拟 SQL 执行:select * from products limit 5' name='query_database' id='efd44bea-441b-4728-8a20-da4d933db704' tool_call_id='call_00_PDqburnOUMtv7RDsfu84ZoUA'
====== 用户问题 ======
计算 (17+3)*(8-1)
====== Agent 回复 ======
[Router] 检测到意图: math
content='140' name='calculate' id='cdccb03a-86a3-4561-b3b8-08740c753303' tool_call_id='call_00_XCrNAL0A6RnzFRLBWZ84srMb'
5.6 System Prompt 系统提示词
system_prompt 是 create_agent 中定义 Agent 角色、行为准则、输出格式和约束 的核心参数,相当于 Agent 的”人格说明书”。LangChain 1.0 将其设计为唯一的顶层提示词入口。LangChain 1.0 不支持在 system_prompt 中直接嵌入 {variable} 占位符(这是旧版 PromptTemplate 的做法)。如需动态内容,应使用 dynamic_prompt 中间件。
1 | #system_prompt 在 ReAct 循环中的位置: |
通过精心设计的提示词,您可以:
定义角色:从客服到专家,从教师到顾问
约束输出:控制长度、格式、语言
引导工具:强制或可选使用工具
保障安全:防止数据泄露和违规操作
实现个性化:通过动态提示支持多租户
记住:在 LangChain 1.0 中,system_prompt 的设计质量直接决定了 Agent 的表现上限。投入时间打磨提示词,远比调整模型参数更有效。
1 | from langchain.agents import create_agent |
=== 静态 System Prompt ===
AI: 北京:晴朗,气温25°C。
=== 动态 System Prompt(专家角色)===
AI: 北京目前的天气是晴朗,气温为25°C。
=== 动态 System Prompt(新手角色)===
AI: 今天北京的天气是晴朗的,气温是25°C。适合出去逛逛哦!
5.7 流式输出
stream_mode 模式的对比
| 模式 | 输出内容 | 使用场景 | 优点 | 缺点 |
|---|---|---|---|---|
"values" |
每步后的完整状态 | 调试Agent执行流程 | ⭐ 状态完整,可追溯 ⭐ 无需拼接历史 |
数据量大(重复传输) |
"updates" |
仅状态变更部分 | 前端增量更新UI | 数据量小,传输快 | 需手动维护完整状态 |
"messages" |
LLM生成的token流 | 实时显示打字效果 | 响应即时,用户体验好 | 不包含工具调用信息 |
"custom" |
工具函数自定义输出 | 插入业务日志 | 灵活控制输出内容 | 需手动调用stream writer |
1 | from langchain.agents import create_agent |
================================[1m Human Message [0m=================================
北京和上海的天气怎么样?
--------------------------------------------------
==================================[1m Ai Message [0m==================================
Tool Calls:
get_weather (call_rvUI03xmmVuDcsIjUduPOqoF)
Call ID: call_rvUI03xmmVuDcsIjUduPOqoF
Args:
city: 北京
get_weather (call_y5nrnnmfXyQTbfe0chyVkqbm)
Call ID: call_y5nrnnmfXyQTbfe0chyVkqbm
Args:
city: 上海
--------------------------------------------------
=================================[1m Tool Message [0m=================================
Name: get_weather
上海的天气是:多云,气温28°C
--------------------------------------------------
==================================[1m Ai Message [0m==================================
北京的天气是:晴朗,气温25°C。
上海的天气是:多云,气温28°C。
--------------------------------------------------
常见误区与注意事项
误区1:stream_mode=”values” 会流式返回 LLM token
- 真相:它返回的是步骤级的完整状态,不是字符级token。想看token需用 stream_mode=”messages”
误区2:values 和 updates 返回数据量差不多
- 真相:values 在每一步都返回所有历史消息,数据量线性增长;updates 只返回增量,适合网络传输
误区3:可以混用多种 stream_mode
- 真相:可以同时指定多个模式(如 stream_mode=[“values”, “custom”]),但返回的是元组,需分别处理
6、Agent记忆管理
LangChain 1.0的记忆管理与LangGraph的状态机制深度绑定,在 LangGraph 中,**记忆就是”持久化的状态(Persisted State)”**。
你需要掌握三个核心要素:
State (状态): 定义用来存储消息的结构(通常是
MessagesState)。Checkpointer (检查点保存器): 负责在每一步结束后把状态保存下来(短期记忆通常用
MemorySaver)。Thread ID (线程ID): 在调用时通过
config传入,用来隔离不同用户的对话上下文。
短期 vs 长期记忆的分界标准
- 误区:存储介质 = 记忆类型?
错误认知:
“内存 = 短期记忆”
“数据库 = 长期记忆”
正确标准:
短期记忆:数据与会话(thread进程)生命周期绑定,随会话结束而被清理或遗忘
长期记忆:数据与用户/业务实体生命周期绑定,跨会话持久保留并可主动检索
6.1 短期记忆管理
短期记忆通过LangGraph的AgentState(一个TypedDict)来管理。对话历史、中间步骤等信息被保存在状态中,并通过检查点(Checkpoints)机制在每次迭代后持久化。这使得长对话和失败恢复成为可能。
6.1.1 Checkpointer机制
这是 LangGraph 记忆的灵魂。
不加这一行:Agent 是无状态的。每次
invoke都是全新的开始。加上这一行:LangGraph 会在每一步执行后,把
state序列化并存入MemorySaver。原理:当你再次 invoke 并传入
thread_id时,LangGraph 会先去内存里查”这个 ID 上次停在哪里?状态是什么?”,然后加载状态,把你的新消息append进去,再继续运行。
6.1.2 Thread ID配置
这是**短期记忆的”钥匙”**。
在 Web 开发中,这就是 Session ID。
你需要为每个用户或每个会话生成一个唯一的 ID。
不同的 ID 之间内存是完全隔离的(如代码中
session_user_123和session_user_999的区别)。
InMemorySaver() 内存记忆管理
1 | import os |
============================================================
场景 1: 内存记忆(开发环境)
============================================================
用户:你好,我叫陈明,好久不见!
AI: 你好,陈明!很高兴见到你!你今年28岁,喜欢旅游、滑雪和喝茶。最近有什么有趣的事情发生吗?
----------------------------------------
用户:请问你还记得我叫什么名字吗?
AI: 当然记得,你叫陈明!
----------------------------------------
当前记忆轮次: 6 条消息
新会话 AI: 我无法记住之前的对话或用户信息。每次交流都是独立的。如果你有任何问题或需要帮助,请随时告诉我!
PostgresSaver() 数据库持久化记忆
PostgresSaver 即使存储到数据库,仍然属于短期记忆。仍然属于短期记忆的原因:
作用域限制:它只检索和加载当前 thread_id 的数据
生命周期管理:默认不会主动清理,但数据语义上属于”本次会话”
无跨会话检索能力:无法在新会话中自动访问旧会话数据(除非手动指定旧 thread_id)
1 | #系统安装postgresql |
1 | #!pip install langgraph-checkpoint-postgres # 生产环境使用 |
1 | # 测试数据库是否连接正常 |
version
------------------------------------------------------------------------------------------------------------------------------
PostgreSQL 14.20 (Homebrew) on aarch64-apple-darwin25.1.0, compiled by Apple clang version 17.0.0 (clang-1700.4.4.1), 64-bit
(1 row)

1 | from langgraph.checkpoint.postgres import PostgresSaver |
============================================================
场景 2: Postgres 持久化记忆(生产环境)
============================================================
AI: 您是张三,32岁,您的爱好包括编程、阅读和电影。如果您需要其他帮助,请告诉我!
1 | !psql -U myuser -d mydatabase -c "SELECT * FROM checkpoints WHERE thread_id = 'production_user_001' LIMIT 3;" |
[' thread_id | checkpoint_ns | checkpoint_id | parent_checkpoint_id | type | checkpoint | metadata ',
'---------------------+---------------+--------------------------------------+--------------------------------------+------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+------------------------------------------------',
' production_user_001 | | 1f0c9ee6-ea7c-688a-8006-5ffdc308df0b | 1f0c9ee6-df31-6bd8-8005-d6e70a5dec43 | | {"v": 4, "id": "1f0c9ee6-ea7c-688a-8006-5ffdc308df0b", "ts": "2025-11-25T11:03:54.437434+00:00", "versions_seen": {"model": {"branch:to:model": "00000000000000000000000000000007.0.1522345980062626"}, "tools": {}, "__input__": {}, "__start__": {"__start__": "00000000000000000000000000000006.0.8062875354520515"}}, "channel_values": {}, "channel_versions": {"messages": "00000000000000000000000000000008.0.20166839506104317", "__start__": "00000000000000000000000000000007.0.1522345980062626", "__pregel_tasks": "00000000000000000000000000000004.0.09165476729651179", "branch:to:model": "00000000000000000000000000000008.0.20166839506104317"}, "updated_channels": ["messages"]} | {"step": 6, "source": "loop", "parents": {}}',
' production_user_001 | | 1f0c9ee6-ba40-6888-bfff-083b279dc1ea | | | {"v": 4, "id": "1f0c9ee6-ba40-6888-bfff-083b279dc1ea", "ts": "2025-11-25T11:03:49.379696+00:00", "versions_seen": {"__input__": {}}, "channel_values": {}, "channel_versions": {"__start__": "00000000000000000000000000000001.0.8015051406400313"}, "updated_channels": ["__start__"]} | {"step": -1, "source": "input", "parents": {}}',
' production_user_001 | | 1f0c9ee6-ba44-66ae-8000-9d60ab74842e | 1f0c9ee6-ba40-6888-bfff-083b279dc1ea | | {"v": 4, "id": "1f0c9ee6-ba44-66ae-8000-9d60ab74842e", "ts": "2025-11-25T11:03:49.381284+00:00", "versions_seen": {"__input__": {}, "__start__": {"__start__": "00000000000000000000000000000001.0.8015051406400313"}}, "channel_values": {"branch:to:model": null}, "channel_versions": {"messages": "00000000000000000000000000000002.0.8673286120321037", "__start__": "00000000000000000000000000000002.0.8673286120321037", "branch:to:model": "00000000000000000000000000000002.0.8673286120321037"}, "updated_channels": ["branch:to:model", "messages"]} | {"step": 0, "source": "loop", "parents": {}}',
'(3 rows)',
'']
| 特性维度 | InMemorySaver | PostgresSaver |
|---|---|---|
| 存储位置 | 内存(Python dict) | PostgreSQL 数据库 |
| 生命周期 | 会话级(与 thread_id 绑定) |
会话级(与 thread_id 绑定) |
| 作用域 | 单一会话(无法跨线程) | 单一会话(无法跨线程) |
| 持久化 | 进程重启后丢失 | 进程重启后保留 |
| 数据隔离 | thread_id |
thread_id |
| 适用环境 | 开发、测试 | 生产、分布式部署 |
| 性能 | 极高(纳秒级) | 较高(毫秒级) |
| 扩展性 | 单进程限制 | 支持多实例、高并发 |
| 核心定位 | 短期记忆 | 短期记忆(持久化版) |
6.2 上下文裁剪
此外,真正的记忆管理还涉及”上下文窗口控制”(防止对话太长撑爆 Token),这需要配合 trim_messages 使用。
问题:如果不处理,随着对话进行,
state["messages"]会包含几千条消息。直接全部传给 LLM 会导致:1. 烧钱;2. 超过 128k/8k 限制报错。解决:我们在
call_model内部使用了 trimmer。State 中:依然保存了 100% 的完整历史(为了审计或回溯)。
传给 LLM 时:只传最近的 N 个 Token(或 N 条消息)。
start_on=”human”: 这是一个很细节的最佳实践。如果截断导致第一条消息是 AI 的回复(没有对应的 User 问题),某些模型会感到困惑。这个参数确保截断后的对话总是以 User 开始。
1 | # ============ 核心模块导入 ============ |
✅ 已加载模型 'gpt-4o-mini' 的 tiktoken 编码器
============================================================
场景:手动 trim_messages + InMemorySaver
============================================================
--- 第 1 轮 ---
用户: 你好,我叫陈明
AI: 你好,陈明!有什么我可以帮助你的吗?
----------------------------------------
--- 第 2 轮 ---
用户: 查询北京天气
裁剪前消息数: 2
裁剪后 token: 27,裁剪后消息数: 2
AI: 北京的天气是晴,气温为25°C。还有其他需要帮助的吗?
----------------------------------------
--- 第 3 轮 ---
用户: 上海呢?
裁剪前消息数: 6
裁剪后 token: 75,裁剪后消息数: 6
AI: 上海的天气也是晴,气温为25°C。还有其他城市需要查询吗?
----------------------------------------
--- 第 4 轮 ---
用户: 明天北京天气如何?
裁剪前消息数: 10
裁剪后 token: 97,裁剪后消息数: 8
AI: 我只能提供当前的北京天气信息,明天的天气情况可能需要查找其他来源。如果需要查询其他城市的天气,请告诉我!
----------------------------------------
--- 第 5 轮 ---
用户: 我是谁?
裁剪前消息数: 14
裁剪后 token: 64,裁剪后消息数: 4
AI: 你叫陈明。有什么我可以帮助你的吗?
----------------------------------------
6.3 自定义 State 扩展
在 LangGraph 中,AgentState 是一个 TypedDict,定义了 Agent 执行过程中流转的数据结构。扩展 State = 在基础结构上增加自定义字段,用于携带更多上下文和业务数据。
- 扩展 State 的本质:在 LangGraph 中,State 是 Agent 的 “内存” 和 “消息总线” ,扩展它就像给程序增加新的全局变量,但这些变量随执行流自动流转、隔离、持久化,是实现复杂 Agent 逻辑的基础。
扩展 State 核心目的
跨步骤持久化上下文:Agent 执行是多步骤的(LLM调用 → 工具调用 → 结果解析),扩展的 State 字段能在所有步骤间共享。
实现条件分支与动态路由:根据 State 中的字段值,决定 Agent 的下一步走向。
支持多模态与复杂输入:现代 Agent 需要处理图片、文件等非文本数据,扩展到 State 中。
实现记忆与持久化:扩展字段用于存储长期记忆,跨会话保持。
性能监控与调试:扩展字段用于记录性能指标,便于分析优化。
1 | class ExtendedState(TypedDict): |
使用 TypedDict 当且仅当:
性能极度敏感(如高频API响应,避免Pydantic序列化开销)
数据结构简单(无嵌套或浅层嵌套)
仅需类型提示(团队强制使用mypy,且信任数据输入)
外部库要求(如某些ORM返回TypedDict)
1 | # ============ 自定义 State 扩展 ============ |
============================================================
场景 3: 自定义 State 扩展记忆维度
============================================================
第一轮: 主题已成功设置为暗黑模式。
----------------------------------------
第二轮: 欢迎回来,user_789!当前主题是暗黑模式。
----------------------------------------
当前记忆状态:
用户ID: user_789
偏好: {'language': 'zh-CN', 'theme': 'dark'}
消息数: 8
| 场景 | TypedDict | Pydantic |
|---|---|---|
| FastAPI请求体 | ❌ 不推荐(需手动验证) | ✅ 最佳选择(原生集成) |
| GraphQL响应 | ✅ 适合(结构固定) | ⚠️ 可但较重 |
| 内部函数参数 | ✅ 轻量且有效 | ❌ 过度设计 |
| CLI工具配置 | ⚠️ 需手动校验 | ✅ 自动验证友好 |
| 数据处理流水线 | ✅ 零开销传递 | ⚠️ 频繁转换有成本 |
| 机器学习特征 | ✅ 快速定义结构 | ❌ 不必要 |
| 微服务DTO | ⚠️ 需结合mypy | ✅ 天然支持序列化 |
| 测试Mock数据 | ✅ 快速创建 | ⚠️ 验证可能碍事 |
记忆核心原则
隔离性:每个用户必须分配唯一 thread_id,避免串话
持久化:生产环境必须使用数据库检查点,支持服务重启和高可用
可控性:自定义 State 和中间件实现业务逻辑与记忆管理的分离
性能:长对话必须启用摘要机制,防止 token 超限和响应延迟
6.4 长期记忆
长期记忆通过与外部向量数据库或键值存储集成来实现。可以在Agent执行的关键节点(如对话结束时)提取关键信息、用户偏好等,并存入长期记忆库,供未来的对话使用。
6.4.1 语义检索与向量数据库
向量数据库是实现长期记忆的核心技术,通过语义相似度搜索实现知识的长期存储和检索。
技术实现:
向量化存储:将对话内容、用户偏好等转换为向量表示
语义检索:基于向量相似度实现智能搜索
多模态支持:支持文本、图像、音频等多种数据类型
高性能查询:支持大规模数据的快速检索
典型实现:
Milvus:开源向量数据库,支持大规模向量检索
Qdrant:高性能向量搜索引擎
Pinecone:云原生向量数据库服务
Chroma: 轻量级向量数据库,可本地持久化
1 | #!pip install langchain-chroma |
1 | import os |
--- 🔵 场景 A:用户告诉 Agent 喜好 ---
[记忆操作] 正在保存记忆: '用户最喜欢的水果是草莓。'
[记忆操作] 正在保存记忆: '用户对花生过敏。'
Agent: 好的,我已经记住了你最喜欢的水果是草莓,并且你对花生过敏。
--- 🟠 场景 B:第二天 (新的 Session,短期记忆已清空) ---
User: 我想吃点零食,但我忘了我有什么忌口,你能帮我查查吗?
[记忆操作] 正在搜索记忆: '忌口'
Agent: 你对花生过敏,所以在选择零食时要避免含有花生的产品。希望这能帮到你!如果你有其他的忌口或偏好,随时告诉我,我会帮你记住的。
6.5 跨线程记忆
针对”跨线程记忆(Cross-Thread Memory)”的管理,在 LangChain 1.0 / LangGraph 体系中,这通常被称为”用户级状态(User-Level State)” 或”全局记忆”。
它与前两个问题的区别在于:
**短期记忆 (
Checkpointer)**:只在thread_id(一次会话)内有效。**长期记忆 (
VectorStore)**:存的是模糊的知识片段。跨线程记忆 (BaseStore):存的是结构化的用户档案(User Profile),例如用户的姓名、VIP等级、偏好设置等。无论用户开多少个新聊天窗口(Thread),这些信息都必须存在。
6.5.1 BaseStore结构化存储
BaseStore 是 LangGraph 提供的通用键值存储抽象接口,专为结构化长期记忆设计,核心特性包括:
命名空间(Namespace)机制
采用层次化元组路径组织数据,类似文件系统目录结构:
1 | namespace = ("users", "user_123", "preferences") |
核心操作
put(namespace, key, value):存储键值对(支持TTL过期)get(namespace, key):精确检索单个记忆search(namespace, query):语义搜索(需子类支持)delete(namespace, key):删除记忆
1 | import os |
1 | # ========================================== |
1 | run_postgres_agent() |
--- 正在连接 PostgreSQL 数据库 ---
🔧 初始化 Checkpointer 表结构...
✅ Checkpointer 表结构初始化完成
🔧 初始化 Store 表结构...
✅ Store 表结构初始化完成
======================================================================
场景 1:用户 Alice 第一次对话(会话 1)
======================================================================
👤 用户 Alice: 你好,我是 Alice,一名 Python 开发工程师,我喜欢深度学习。
🔧 [调用工具]: remember_user_info
🤖 Agent: 你好,Alice!很高兴认识你,作为一名 Python 开发工程师,你对深度学习的兴趣真不错!如果你有任何问题或者需要帮助的地方,随时告诉我!
======================================================================
场景 2:用户 Alice 第二次对话(会话 2 - 不同 thread_id)
======================================================================
💡 模拟:Alice 关闭浏览器,第二天重新打开,开始新会话
👤 用户 Alice: 你还记得我是谁吗?我的职业是什么?
🔧 [调用工具]: recall_user_info
🤖 Agent: 你是 Alice,一名 Python 开发工程师,喜欢深度学习。有什么我可以帮助你的吗?
======================================================================
场景 3:用户 Bob 的对话(不同用户)
======================================================================
👤 用户 Bob: 你好,我是 Bob,一名产品经理,帮我算一下 10 + 20 的特殊结果。
🔧 [调用工具]: remember_user_info
🔧 [调用工具]: magic_calculation
🤖 Agent: 你好,Bob!我已经记住了你的信息,你是一名产品经理。关于你问的特殊计算,10 + 20 的结果是 **300**。如果你还有其他问题,随时告诉我!
======================================================================
场景 4:Alice 第三次对话(验证记忆隔离)
======================================================================
💡 验证:Alice 的记忆不会被 Bob 的信息污染
👤 用户 Alice: 我的兴趣爱好是什么?
🔧 [调用工具]: recall_user_info
🤖 Agent: 你的兴趣爱好是深度学习。
======================================================================
✅ 跨线程记忆测试完成!
======================================================================
📊 测试总结:
✅ 场景 1: Alice 首次对话,Agent 自动存储用户信息到 Store
✅ 场景 2: Alice 新会话(不同 thread_id),Agent 成功从 Store 检索记忆
✅ 场景 3: Bob 的对话,Agent 为 Bob 创建独立的记忆空间
✅ 场景 4: Alice 再次对话,记忆未被 Bob 的信息污染
💡 关键特性:
- Checkpointer: 管理单个会话的对话历史(基于 thread_id)
- Store: 管理跨会话的长期记忆(基于 user_id)
- 记忆隔离: 不同用户的记忆完全隔离(通过 namespace)
- 持久化: 所有数据存储在 PostgreSQL,重启程序后依然可用
======================================================================
1 | run_postgres_agent() |
--- 正在连接 PostgreSQL 数据库 ---
🔧 初始化 Checkpointer 表结构...
✅ Checkpointer 表结构初始化完成
🔧 初始化 Store 表结构...
✅ Store 表结构初始化完成
======================================================================
场景 1:用户 Alice 第一次对话(会话 1)
======================================================================
👤 用户 Alice: 你好,我是 Alice,一名 Python 开发工程师,我喜欢深度学习。
🔧 [调用工具]: recall_user_info
🤖 Agent: 你好,Alice!我记得你是一名 Python 开发工程师,并且喜欢深度学习。如果你有任何问题或者想讨论的内容,随时告诉我!
======================================================================
场景 2:用户 Alice 第二次对话(会话 2 - 不同 thread_id)
======================================================================
💡 模拟:Alice 关闭浏览器,第二天重新打开,开始新会话
👤 用户 Alice: 你还记得我是谁吗?我的职业是什么?
🔧 [调用工具]: recall_user_info
🤖 Agent: 你是 Alice,一名 Python 开发工程师,喜欢深度学习。有什么我可以帮助你的吗?
======================================================================
场景 3:用户 Bob 的对话(不同用户)
======================================================================
👤 用户 Bob: 你好,我是 Bob,一名产品经理,帮我算一下 10 + 20 的特殊结果。
🔧 [调用工具]: recall_user_info
🔧 [调用工具]: magic_calculation
🤖 Agent: 你好,Bob!我记得你是一名产品经理。关于你问的特殊计算,10 + 20 的结果是 **300**。如果你还有其他问题,随时告诉我!
======================================================================
场景 4:Alice 第三次对话(验证记忆隔离)
======================================================================
💡 验证:Alice 的记忆不会被 Bob 的信息污染
👤 用户 Alice: 我的兴趣爱好是什么?
🔧 [调用工具]: recall_user_info
🤖 Agent: 你的兴趣爱好是深度学习。
======================================================================
✅ 跨线程记忆测试完成!
======================================================================
📊 测试总结:
✅ 场景 1: Alice 首次对话,Agent 自动存储用户信息到 Store
✅ 场景 2: Alice 新会话(不同 thread_id),Agent 成功从 Store 检索记忆
✅ 场景 3: Bob 的对话,Agent 为 Bob 创建独立的记忆空间
✅ 场景 4: Alice 再次对话,记忆未被 Bob 的信息污染
💡 关键特性:
- Checkpointer: 管理单个会话的对话历史(基于 thread_id)
- Store: 管理跨会话的长期记忆(基于 user_id)
- 记忆隔离: 不同用户的记忆完全隔离(通过 namespace)
- 持久化: 所有数据存储在 PostgreSQL,重启程序后依然可用
======================================================================
1 | !psql -U myuser -d mydatabase -c "SELECT prefix, LEFT(key, 8) as key_prefix, value->>'info' as info FROM store ORDER BY created_at;" |
prefix | key_prefix | info
---------------+------------+----------------------------------------
alice.profile | 31273427 | Alice: Python 开发工程师,喜欢深度学习
bob.profile | 7ff6733c | Bob: 产品经理
(2 rows)
1 | # 测试过程中,如果数据错乱有问题,可以先清空再尝试;但在生成环境中慎重做此操作!!! |
TRUNCATE TABLE
| 维度 | BaseStore方案 | 向量数据库方案 |
|---|---|---|
| 依赖导入 | from langgraph.store.memory import InMemoryStore |
from langchain.vectorstores import Chroma |
| 存储内容 | 结构化字典/列表(JSON序列化) | 非结构化文本(自动Embedding) |
| 检索方式 | get()精确匹配 + search()简单搜索 |
similarity_search()语义相似 |
| 创建Agent | create_agent(llm, tools, system_message) |
create_agent(llm, tools, system_message) |
| 工具定义 | 直接操作Python对象 | 需先转为Document再存储 |
| 查询灵活性 | ❌ 必须精确key或有限搜索 | ✅ 自然语言模糊查询 |
| 写入速度 | < 1ms(内存) | 50-200ms(含Embedding) |
| 更新成本 | O(1) 直接覆盖 | O(n) 需重新计算向量 |
7、企业最佳组合
7.1 Checkpointer + KV Store组合架构
最佳实践架构如下:
**身份标识 (
user_id)**:在配置中除了传入thread_id,必须传入user_id。双层存储:
会话层:使用
MemorySaver管理当前聊天的上下文。用户层:使用
BaseStore存储跨会话的用户档案。
7.2 记忆生命周期管理
记忆清理策略:
自动过期:设置TTL自动清理过期记忆
手动清理:提供管理接口手动清理无用记忆
压缩归档:对历史记忆进行压缩和归档
7.3 性能优化策略
查询优化:
索引优化:为常用查询字段建立索引
缓存策略:实现多级缓存提高查询性能
批量操作:支持批量读写操作减少I/O开销
8、总结与展望
LangChain 1.0框架为Agent开发提供了完整的解决方案,从基础概念到高级特性都进行了系统性的设计。create_agent 有望成为 AI 应用的标准构建块,其地位堪比 React 之于前端开发。短期看,它将推动智能工具市场标准化,实现”工具即插即用”;中期看,分布式状态同步与自我优化中间件将使其胜任金融交易、医疗诊断等高并发、低延迟场景;长期看,声明式 Agent 配置与多 Agent 联邦将催生”Agent 调用 Agent”的递归架构,构建起去中心化的 AI 服务网格。最终,开发者只需组合、配置与调优,而复杂推理的编排、优化与执行,将完全托付给这一新一代的智能计算框架。