LangGraph长短期记忆实现机制及检查点的使用
我们已经探索了使用基础图结构来实现大模型交互,并逐步引入了各种代理架构,以构建能够处理更复杂逻辑的图结构。随着节点和功能的不断增加,构建出来的应用程序也具备了处理更复杂问题的能力。但是,不论是简单还是复杂的图,一个明显的限制是:之前课程中的所有实现都只能执行单一任务。也就是说,一旦图被编译并根据用户的输入运行以后,它虽然可以按照既定的图流程输出结果,但在下一次交互时,这个图将无法记住之前的对话内容。我们可以通过以下代码进行测试,观察这一现象:
下面的代码中实现的是一个最简单、最基础的基于LangGraph构建的图:
1 | import getpass |
我们来对这个图进行多轮的问答交互,测试其上下文记忆能力。首先进行第一轮提问:
1 | async for chunk in simple_graph.astream(input={"messages": ["你好,我叫木羽"]}, stream_mode="values"): |
================================[1m Human Message [0m=================================
你好,我叫木羽
==================================[1m Ai Message [0m==================================
你好,木羽!很高兴见到你。有什么我可以帮助你的吗?
接下来进行第二轮提问:
1 | async for chunk in simple_graph.astream(input={"messages": ["你知道我叫什么吗?"]}, stream_mode="values"): |
================================[1m Human Message [0m=================================
你知道我叫什么吗?
==================================[1m Ai Message [0m==================================
抱歉,我无法知道你的名字。为了保护用户隐私,我没有访问个人信息的权限。如果你愿意,可以告诉我你的名字。
第三轮提问继续测试:
1 | async for chunk in simple_graph.astream(input={"messages": ["请问我刚才都问了你什么问题?"]}, stream_mode="values"): |
================================[1m Human Message [0m=================================
请问我刚才都问了你什么问题?
==================================[1m Ai Message [0m==================================
对不起,我无法查看先前的对话内容。如果你有任何问题,请随时问我!
从上述三轮提问和响应的分析中,我们可以清楚地看到,虽然每轮的问题都是输入到同一个编译后的graph实例,但是每次它表现得都像一个”新图”一样,完全不知道自己之前做了什么。所以很显然,当前的图结构是缺乏上下文记忆能力的。首先要明确的是:大模型本身是不具备记忆能力的。在之前的课程中,我们讨论过为大模型赋予记忆能力的方法,通常是通过维护一个消息列表来保存之前的对话内容,然后在每次新的对话时填充到整体的Prompt中,从而实现上下文的持续性。比如下面的代码:
1 | from openai import OpenAI |
你刚刚介绍自己叫木羽。我有什么可以帮助你的吗?
当我们通过在Prompt中填入之前的问答对话,并将其与新一轮的问题一起发送给大模型时,大模型就能够理解并维持对话的上下文。这种方法是我们在多个应用场景中实现大模型记忆功能的经典做法。这里可以有的小伙伴会比较疑惑,在构建图的时候不是通过State状态模式中的add_messages这个Reducer函数维护了一个消息列表吗,看似已经在处理记忆功能,为何不生效?正如下面这样:
1 | async for chunk in simple_graph.astream(input={"messages": ["你好,我叫木羽"]}, stream_mode="values"): |
{'messages': [HumanMessage(content='你好,我叫木羽', additional_kwargs={}, response_metadata={}, id='4d92e45c-dc58-4179-8f24-30353afecce7')]}
{'messages': [HumanMessage(content='你好,我叫木羽', additional_kwargs={}, response_metadata={}, id='4d92e45c-dc58-4179-8f24-30353afecce7'), AIMessage(content='你好,木羽!很高兴认识你。有什么我可以帮忙的吗?', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 18, 'prompt_tokens': 12, 'total_tokens': 30, 'prompt_tokens_details': {'cached_tokens': 0}, 'completion_tokens_details': {'reasoning_tokens': 0}}, 'model_name': 'gpt-4o-2024-08-06', 'system_fingerprint': 'fp_9e15ccd6a4', 'finish_reason': 'stop', 'logprobs': None}, id='run-abf94c9e-553c-4bb7-8325-7919459b8f26-0', usage_metadata={'input_tokens': 12, 'output_tokens': 18, 'total_tokens': 30, 'input_token_details': {'cache_read': 0}, 'output_token_details': {'reasoning': 0}})]}
如上输出所示,在Start节点到call_model节点之间,在Messages中记录了HumanMessage(content='你好,我叫木羽', ....)的有效信息,而在call_model到END节点之间,在在Messages中记录了HumanMessage(content='你好,我叫木羽', ....),AIMessage(content='你好,木羽!很高兴认识你。有什么我可以帮助你的吗?)....'的有效信息,这看起来是合理的。但是当我们发起一轮新的问答的时候:
1 | async for chunk in simple_graph.astream(input={"messages": ["请问你知道我叫什么吗?"]}, stream_mode="values"): |
{'messages': [HumanMessage(content='请问你知道我叫什么吗?', additional_kwargs={}, response_metadata={}, id='b0d8ba68-7ae1-4d52-a955-31f6b78f319e')]}
{'messages': [HumanMessage(content='请问你知道我叫什么吗?', additional_kwargs={}, response_metadata={}, id='b0d8ba68-7ae1-4d52-a955-31f6b78f319e'), AIMessage(content='对不起,我无法知道你的名字。', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 8, 'prompt_tokens': 15, 'total_tokens': 23, 'prompt_tokens_details': {'cached_tokens': 0}, 'completion_tokens_details': {'reasoning_tokens': 0}}, 'model_name': 'gpt-4o-2024-08-06', 'system_fingerprint': 'fp_45cf54deae', 'finish_reason': 'stop', 'logprobs': None}, id='run-3c682029-f546-4562-9b32-45617b7180a7-0', usage_metadata={'input_tokens': 15, 'output_tokens': 8, 'total_tokens': 23, 'input_token_details': {'cache_read': 0}, 'output_token_details': {'reasoning': 0}})]}
如果按照能让该图具备上下文记忆能力的话,其维护的Messages应该是:
1 | {'messages': [HumanMessage(content='你好,我叫木羽') .....] |
显然在第二轮提问后,State状态中的messages字段并未如预期那样更新,这就导致了即使是同一个图连续接收到用户的问题,每一个问题对于它而言都是完全新的,没有任何上下文关联。所以,在LangGraph框架中,State状态模式的设计本质上是用于在单次运行期间维持和传递整个图节点的消息状态。每次运行完成后,状态会重置到初始状态。以此确保每次运行的独立性,防止了不同运行间的数据干扰。但这也意味着图无法保留跨次运行的上下文信息。这是State状态模式的一个常见误区,大家要特别注意理解。
那如何做到上下文的记忆功能呢?我们就需要深入了解一下LangGraph中的checkpointer模块设计。这个模块用于灵活管理State状态中产生的有效信息,能够保存历史数据,并在需要时将这些数据传递回图中,从而赋予整个图结构上下文记忆的能力,以此来保持状态信息的连续性。
1、AI Agent的记忆认知
记忆是一种允许个体存储、检索并利用信息以理解过去和规划未来的关键认知功能。像人类一样,通过学习、经验获得的知识可以在需要的时候从大脑中检索出来。对于AI Agent来说,随着其承担越来越复杂、涉及大量用户交互的任务,通过State状态的管理,是可以处理从大任务拆分出来的各个子任务间的记录和阶段性成果,这本质上就是一种记忆形式。而如果我们还期望AI Agent能在连续的交互中跨对话理解之前的行为,这同样是一种记忆能力的体现。
总的来说,无论是运行中的状态信息传递还是跨对话间的信息保存,记忆功能都适用于多种场景,并有多种实现方式。不同的结构框架对Memory的实现和定位都会有所不同,但都会将其所实现的记忆功能分为短期记忆和长期记忆两大类,以适应不同的应用需求。我们对短期记忆的普遍理解是指那些存储在缓存、内存或程序运行过程中的状态信息。这类信息通常作为整个大模型或Agent的短期记忆,在构建过程中通过数据接口进行临时存储,并在任务完成后直接被清除,就像LangGraph的State状态机制一样。相对地,长期记忆通常涉及将重要数据通过特定方式持久化保存在某种存储容器中,任何程序都可以在这里提取到内容,且不受时间的影响,一般这种常规的实现方法是数据库的本地存储。
我们正在学习的LangGraph框架,其官方的设计思路就如下图所示:
LangGraph Memory Docs:https://docs.langchain.com/oss/python/langgraph/memory#what-is-memory
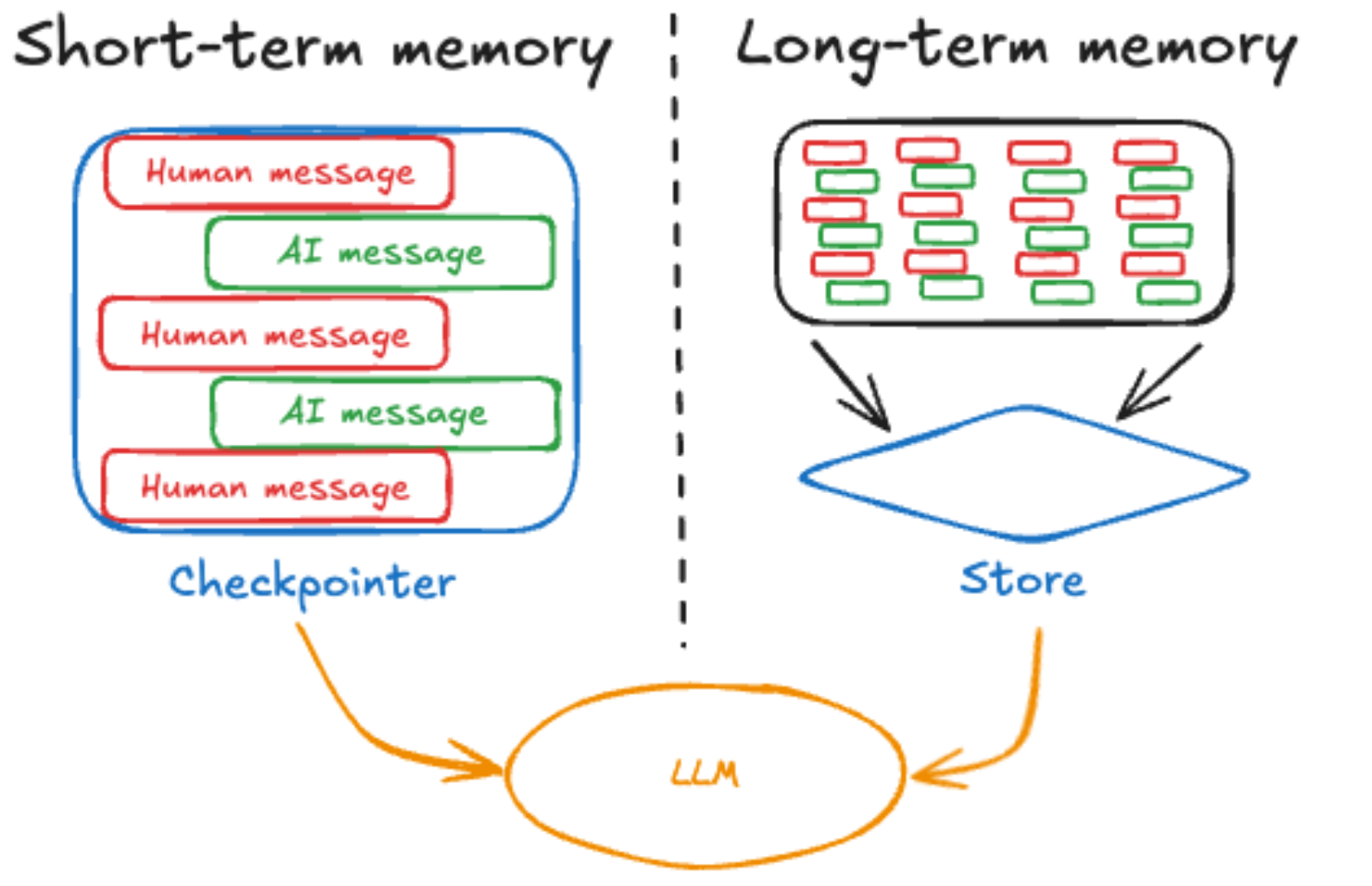
上图来自于LangGraph的官方文档。不同的开发框架会因为其整体架构的设计而对长短期记忆有不同的定位,同时也会根据其底层的开发原理来做不同形式的具体实现。每个AI Agent开发框架都会包含记忆模块,但具体应用的方法一定都是不一样的,也势必会产生特有的专业名词来定义这个过程。正如上图所示,LangGraph 框架通过Checkpointer 和 Store分别作为长短期记忆的管理模块,而其整体对这两类记忆的定位则是:
- 短期记忆:允许代理访问图中较早步骤中获取的信息,并且可以可以随时从与用户的单个对话线程中调用。
- 长期记忆:使代理能够回忆起之前交互中的信息,例如对话中过去的消息,并且可以在对话线程之间共享,在任何时间、任何线程中调用。
因此,无论是想在已有的图中加入短期记忆还是长期记忆,理解它们管理模式的具体实现方法就是我们学习的关键。首先,让我们探讨用于管理短期记忆的Checkpointer。
2、短期记忆及Checkpointer(检查点)
在介绍LangGraph中的Checkpointer功能之前,我们先利用已学的知识分析一下图在运行时处理中间过程信息的方式。这里我们构建一个简单的图,包括两个节点:call_model节点用于加载一个大模型并回答用户输入的问题,而translate_message节点则将call_model生成的回答翻译成英文。以下是完整的代码实现:
1 | import getpass |
首先我们测试图的运行流程,这里使用异步的流式输出形式,并指定它的输出模式为values。代码如下
1 | async for chunk in simple_short_graph.astream(input={"messages": ["你好,我叫木羽"]}, stream_mode="values"): |
================================[1m Human Message [0m=================================
你好,我叫木羽
==================================[1m Ai Message [0m==================================
你好,木羽!很高兴认识你。有什么我可以帮你的吗?
==================================[1m Ai Message [0m==================================
Hello, Muyu! Nice to meet you. Is there anything I can help you with?
1 | async for chunk in simple_short_graph.astream(input={"messages": ["请问,我叫什么?"]}, stream_mode="values"): |
================================[1m Human Message [0m=================================
请问,我叫什么?
==================================[1m Ai Message [0m==================================
对不起,我无法知道你的名字。
==================================[1m Ai Message [0m==================================
Sorry, I cannot know your name.
这里确定当前的graph实例不具备任何的上下文记忆能力。然后我们进入Debug模式去分析其中间过程。代码如下:
1 | async for chunk in simple_short_graph.astream({"messages": ["你好,我叫木羽"]}, stream_mode="debug"): |
Task id : 9c538a1d-ee76-90fb-1939-4c2ace551439
Message id:f4857e63-7e89-4ef1-8823-36d08bbed050, Message content:你好,我叫木羽
------------------------------------------------
------------------------------------------------
Task id : 9c538a1d-ee76-90fb-1939-4c2ace551439
Message id:run-fdf82334-7ed1-4b8d-a2de-b728f6e3be64-0, Message content:你好,木羽!很高兴见到你。你今天怎么样?有没有什么我可以帮忙的?
------------------------------------------------
------------------------------------------------
Task id : 76994be8-b45e-d637-23dd-0d05f337b6ef
Message id:f4857e63-7e89-4ef1-8823-36d08bbed050, Message content:你好,我叫木羽
Message id:run-fdf82334-7ed1-4b8d-a2de-b728f6e3be64-0, Message content:你好,木羽!很高兴见到你。你今天怎么样?有没有什么我可以帮忙的?
------------------------------------------------
------------------------------------------------
Task id : 76994be8-b45e-d637-23dd-0d05f337b6ef
Message id:run-cc5e37de-7c03-441a-9322-2584b7572846-0, Message content:Hello, Muyu! Nice to meet you. How are you today? Is there anything I can help you with?
------------------------------------------------
------------------------------------------------
再进行一轮问答:
1 | async for chunk in simple_short_graph.astream({"messages": ["你知道我叫什么吗?"]}, stream_mode="debug"): |
Task id : fda00323-a68a-af42-9029-0d02308f4b30
Message id:d8275f15-dcf0-4eb2-a70c-12156b5c6939, Message content:你知道我叫什么吗?
------------------------------------------------
------------------------------------------------
Task id : fda00323-a68a-af42-9029-0d02308f4b30
Message id:run-27a65062-2a77-4903-82fa-a36ef97c93d6-0, Message content:对不起,我不知道你的名字。
------------------------------------------------
------------------------------------------------
Task id : 15153b8b-30d5-e6e8-b071-9222d7126584
Message id:d8275f15-dcf0-4eb2-a70c-12156b5c6939, Message content:你知道我叫什么吗?
Message id:run-27a65062-2a77-4903-82fa-a36ef97c93d6-0, Message content:对不起,我不知道你的名字。
------------------------------------------------
------------------------------------------------
Task id : 15153b8b-30d5-e6e8-b071-9222d7126584
Message id:run-5a0bfa72-4919-4ced-ac98-08551fee129b-0, Message content:Sorry, I don't know your name.
------------------------------------------------
------------------------------------------------
观察上面两轮对话中我们打印的关键信息。在State状态管理的事件流中,每个阶段都会生成一个task,并且每个task被分为两个阶段:生成(当前事件)和执行结果(task_result)。这两个阶段都有一个唯一的且共同的task id。此外,每条消息,无论是用户输入的还是大模型生成的回复,都有一个唯一的ID。
那么,既然每个消息都有不同的ID, 如果想让后面的交互过程知道前面都产生了哪些消息,如果有一种机制可以把消息维护起来(比如使用字典来存储会话,其中每个会话ID映射到一个消息列表),当新一轮的输入进来,我们把指定的消息列表作为初始状态追加到State状态中(默认新一轮State状态会重新初始化),借助State状态可以全局共享的机制,是不是就能实现上下文记忆了呢?
1 | sessions = { |
理解到这里,现在我们就可以说:LangGraph框架中的checkpointer做的就是这样的事。具体来说,它就是通过一些数据结构来存储State状态中产生的信息,并且在每个task开始时去读取全局的状态。主要通过以下四种方式来实现:
- MemorySaver:用于实验性质的记忆检查点。
- SqliteSaver / AsyncSqliteSaver:使用
SQLite数据库 实现的记忆检查点,适合实验性质和本地工作流程。 - PostgresSaver / AsyncPostgresSaver:使用
Postgres数据库实现的高级检查点,适合在生产系统中使用。 - 支持自定义检查点。
不同类型的checkpointer以不同的形式去管理State状态中记录的中间状态信息。但这还不够。为了将一系列产生的消息归属到正确的类别中,就像上面的会话1包含一系列的问答,而会话2包含另一批系列的回答,LangGraph框架引入Thread(线程)概念来充当会话的角色。每个线程代表一个独特的交互或对话流。而thread_id是与特定执行线程关联的唯一标识符。各个概念之间的关联如下图所示:

checkpointer是memory的一种特定实现,它在执行期间保存图在各个点的状态,使系统能够在中断时从该点恢复。这与 LangGraph 中状态的一般概念不同,后者表示应用程序在任何给定时刻的当前快照。虽然状态是动态的并且随着图形的执行而变化,但checkpointer提供了一种存储和检索历史状态的方法,从而促进更复杂的工作流程和人机交互。
接下来,我们以 MemorySaver 这个实现checkpointer的方法为例,帮助大家理解这个过程。
2.1 检查点的特定实现类型-MemorySaver
LangGraph 框架有一个内置的持久层,通过checkpointer实现。当使用checkpointer编译图时,检查点会在每个超级步骤中保存图状态的checkpoint。这些checkpoint被保存到一个thread中,可以在图执行后访问。如下图所示:
超级步骤可以被认为是图节点上的单次迭代。并行运行的节点是同一超级步骤的一部分,而顺序运行的节点则属于单独的超级步骤。在图执行开始时,所有节点都开始处于inactive状态。当节点在其任何传入边缘(或“通道”)上接收到新消息(状态)时,该节点将变为active 。然后,活动节点运行其功能并以更新进行响应。在每个超级步骤结束时,没有传入消息的节点通过将自己标记为inactive 。当所有节点inactive并且没有消息在传输时,图执行终止。

MemorySaver是实现上述流程的一种形式,它通过使用 defaultdict 将checkpointer存储在memory中。如下源码所示:
1 | class MemorySaver( |
https://reference.langchain.com/python/langgraph/checkpoints/#langgraph.checkpoint.memory
使用的方法非常简单,就是在创建任何 LangGraph 图时,通过在编译图时添加MemorySaver来将其设置为保留其State状态中的数据,即:
1 | from langgraph.checkpoint.memory import MemorySaver |
我们通过一个图来理解这个中间过程,构建如下图结构。注意:在编译图的时候,添加MemorySaver作为checkpointer提供Memory功能。
1 | # 导入检查点 |
当添加了checkpointer后,在该图执行的每个超级步骤中会自动创建检查点。即每个节点处理其输入并更新状态后,会当前状态将保存为检查点。但如果像普通图一样,仅传入输入的问题是会报错的,如下所示:
1 | async for chunk in graph_with_memory.astream(input={"messages": ["你好,我叫木羽"]}, stream_mode="values"): |
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In[37], line 1
----> 1 async for chunk in graph_with_memory.astream(input={"messages": ["你好,我叫木羽"]}, stream_mode="values"):
2 message = chunk["messages"][-1].pretty_print()
File ~\anaconda3\envs\agent\Lib\site-packages\langgraph\pregel\__init__.py:1421, in Pregel.astream(self, input, config, stream_mode, output_keys, interrupt_before, interrupt_after, debug, subgraphs)
1403 do_stream = next(
1404 (
1405 cast(_StreamingCallbackHandler, h)
(...)
1409 None,
1410 )
1411 try:
1412 # assign defaults
1413 (
1414 debug,
1415 stream_modes,
1416 output_keys,
1417 interrupt_before_,
1418 interrupt_after_,
1419 checkpointer,
1420 store,
-> 1421 ) = self._defaults(
1422 config,
1423 stream_mode=stream_mode,
1424 output_keys=output_keys,
1425 interrupt_before=interrupt_before,
1426 interrupt_after=interrupt_after,
1427 debug=debug,
1428 )
1429 # set up messages stream mode
1430 if "messages" in stream_modes:
File ~\anaconda3\envs\agent\Lib\site-packages\langgraph\pregel\__init__.py:1073, in Pregel._defaults(self, config, stream_mode, output_keys, interrupt_before, interrupt_after, debug)
1071 checkpointer = self.checkpointer
1072 if checkpointer and not config.get(CONF):
-> 1073 raise ValueError(
1074 f"Checkpointer requires one or more of the following 'configurable' keys: {[s.id for s in checkpointer.config_specs]}"
1075 )
1076 if CONFIG_KEY_STORE in config.get(CONF, {}):
1077 store: Optional[BaseStore] = config[CONF][CONFIG_KEY_STORE]
ValueError: Checkpointer requires one or more of the following 'configurable' keys: ['thread_id', 'checkpoint_ns', 'checkpoint_id']
这是因为当增加了checkpointer后,需要Thread来作为checkpointer保存图中每个检查点的唯一标识,而Thread(线程)又是通过thread_id来标识某个特定执行线程,所以在使用checkpointer调用图时,必须指定thread_id,指定的方式是作为配置configurable的一部分进行声明。 正确调用的代码就如下所示:
1 | # 这个 thread_id 可以取任意数值 |
================================[1m Human Message [0m=================================
你好,我叫木羽
==================================[1m Ai Message [0m==================================
你好,木羽!很高兴见到你。有什么我可以帮助你的吗?
==================================[1m Ai Message [0m==================================
Hello, Muyu! Nice to meet you. Is there anything I can help you with?
================================[1m Human Message [0m=================================
请问我叫什么?
==================================[1m Ai Message [0m==================================
你叫木羽。有什么我可以帮助你的吗?
==================================[1m Ai Message [0m==================================
Your name is Muyu. Is there anything I can help you with?
1 | for chunk in graph_with_memory.stream({"messages": ["我刚才都问了你什么问题?"]}, config, stream_mode="values"): |
================================[1m Human Message [0m=================================
我刚才都问了你什么问题?
==================================[1m Ai Message [0m==================================
你刚才问了两个问题:第一个是介绍自己说“你好,我叫木羽”,第二个是问“请问我叫什么?”。有什么其他需要帮助的吗?
==================================[1m Ai Message [0m==================================
You just asked two questions: the first one was to introduce yourself by saying "Hello, my name is Muyu," and the second one was to ask "What is my name?" Is there anything else you need help with?
现在可以发现与Agent的交互中每次它都能记住之前的消息。然后我们再深入细节了解一下,当添加了检查点后,其中间状态的信息会有什么变化。如下代码所示:
1 | config = {"configurable": {"thread_id": "2"}} |
Thread id:2
CheckPoint id :1ef982c0-5a61-69d6-bfff-683d115afee5
------------------------------------------------
------------------------------------------------
Thread id:2
CheckPoint id :1ef982c0-5a68-6ef9-8000-40c891926099
Message id:4657ff79-ac10-4296-84ed-9ec5b37e679e,Message content:你好,我叫木羽
------------------------------------------------
------------------------------------------------
------------------------------------------------
------------------------------------------------
------------------------------------------------
------------------------------------------------
Thread id:2
CheckPoint id :1ef982c0-67d6-6a81-8001-7b845e279833
Message id:4657ff79-ac10-4296-84ed-9ec5b37e679e,Message content:你好,我叫木羽
Message id:run-5c44eecb-cc93-427b-866d-f6061f2a6811-0,Message content:你好,木羽!很高兴认识你。有什么我可以帮助你的吗?
------------------------------------------------
------------------------------------------------
------------------------------------------------
------------------------------------------------
------------------------------------------------
------------------------------------------------
Thread id:2
CheckPoint id :1ef982c0-7240-64ab-8002-662f66892a40
Message id:4657ff79-ac10-4296-84ed-9ec5b37e679e,Message content:你好,我叫木羽
Message id:run-5c44eecb-cc93-427b-866d-f6061f2a6811-0,Message content:你好,木羽!很高兴认识你。有什么我可以帮助你的吗?
Message id:run-aa43d40e-1a6b-4de7-b049-59f5476f80ea-0,Message content:Hello, Muyu! Nice to meet you. Is there anything I can help you with?
------------------------------------------------
------------------------------------------------
每个super-step后,都会生成一个checkpointer存储中间信息,而一次交互中,只会存在一个thread_id,也就是我们在config = {"configurable": {"thread_id": "2"}}中自定义的线程ID,当我们再次使用相同的thread_id进行问答时,图在执行前后自动加载该thread_id之前存储的所有的信息,添加到新一轮问答的初始状态中,比如下面的代码,我们仍然使用{"thread_id": "2"}再次进行交互;
1 | config = {"configurable": {"thread_id": "2"}} |
Thread id:2
CheckPoint id :1ef982c2-255e-6735-8003-8962b5e3979b
Message id:4657ff79-ac10-4296-84ed-9ec5b37e679e,Message content:你好,我叫木羽
Message id:run-5c44eecb-cc93-427b-866d-f6061f2a6811-0,Message content:你好,木羽!很高兴认识你。有什么我可以帮助你的吗?
Message id:run-aa43d40e-1a6b-4de7-b049-59f5476f80ea-0,Message content:Hello, Muyu! Nice to meet you. Is there anything I can help you with?
------------------------------------------------
------------------------------------------------
Thread id:2
CheckPoint id :1ef982c2-2563-655a-8004-3ea6983465b4
Message id:4657ff79-ac10-4296-84ed-9ec5b37e679e,Message content:你好,我叫木羽
Message id:run-5c44eecb-cc93-427b-866d-f6061f2a6811-0,Message content:你好,木羽!很高兴认识你。有什么我可以帮助你的吗?
Message id:run-aa43d40e-1a6b-4de7-b049-59f5476f80ea-0,Message content:Hello, Muyu! Nice to meet you. Is there anything I can help you with?
Message id:010cfa9f-a020-4fed-b243-20092e11c09c,Message content:请问我刚才都问了你什么问题?
------------------------------------------------
------------------------------------------------
------------------------------------------------
------------------------------------------------
------------------------------------------------
------------------------------------------------
Thread id:2
CheckPoint id :1ef982c2-3987-6f8d-8005-36a04d5751bc
Message id:4657ff79-ac10-4296-84ed-9ec5b37e679e,Message content:你好,我叫木羽
Message id:run-5c44eecb-cc93-427b-866d-f6061f2a6811-0,Message content:你好,木羽!很高兴认识你。有什么我可以帮助你的吗?
Message id:run-aa43d40e-1a6b-4de7-b049-59f5476f80ea-0,Message content:Hello, Muyu! Nice to meet you. Is there anything I can help you with?
Message id:010cfa9f-a020-4fed-b243-20092e11c09c,Message content:请问我刚才都问了你什么问题?
Message id:run-b031a9cf-2d8a-4938-a81d-f51e6263df69-0,Message content:你刚才告诉我你的名字是木羽,并没有问我其他问题。如果你有任何问题或者需要帮助,欢迎随时告诉我!
------------------------------------------------
------------------------------------------------
------------------------------------------------
------------------------------------------------
------------------------------------------------
------------------------------------------------
Thread id:2
CheckPoint id :1ef982c2-42f2-6be2-8006-0679fcd2375a
Message id:4657ff79-ac10-4296-84ed-9ec5b37e679e,Message content:你好,我叫木羽
Message id:run-5c44eecb-cc93-427b-866d-f6061f2a6811-0,Message content:你好,木羽!很高兴认识你。有什么我可以帮助你的吗?
Message id:run-aa43d40e-1a6b-4de7-b049-59f5476f80ea-0,Message content:Hello, Muyu! Nice to meet you. Is there anything I can help you with?
Message id:010cfa9f-a020-4fed-b243-20092e11c09c,Message content:请问我刚才都问了你什么问题?
Message id:run-b031a9cf-2d8a-4938-a81d-f51e6263df69-0,Message content:你刚才告诉我你的名字是木羽,并没有问我其他问题。如果你有任何问题或者需要帮助,欢迎随时告诉我!
Message id:run-c3157fce-889a-468e-b3ca-6c24ccdb666f-0,Message content:You just told me your name is Muyu and didn't ask me any other questions. If you have any questions or need help, feel free to let me know anytime!
------------------------------------------------
------------------------------------------------
由此可以印证检查点的机制是:当调用图或完成一个步骤时,其记忆会更新,而如果线程相同,则会在每个步骤开始时读取全部的状态。如果我们把thread_id换成其他的,则会开启全新的一个线程进行对话,比如:
1 | config = {"configurable": {"thread_id": "3"}} |
Thread id:3
CheckPoint id :1ef982c2-d1af-670d-bfff-56caa2825fe8
Thread id:3
CheckPoint id :1ef982c2-d1b6-6c3e-8000-cb7687d156ac
Message id:6414785f-a897-428d-9e04-ad3777f4456d,Message content:请问我叫什么?
Thread id:3
CheckPoint id :1ef982c2-ded8-64c2-8001-6f096375e6a7
Message id:6414785f-a897-428d-9e04-ad3777f4456d,Message content:请问我叫什么?
Message id:run-f6d2ded2-1f37-46c7-9c47-3afb46a536ce-0,Message content:抱歉,我无法知道你的名字。
Thread id:3
CheckPoint id :1ef982c2-e4ee-6a1b-8002-dd444abd282e
Message id:6414785f-a897-428d-9e04-ad3777f4456d,Message content:请问我叫什么?
Message id:run-f6d2ded2-1f37-46c7-9c47-3afb46a536ce-0,Message content:抱歉,我无法知道你的名字。
Message id:run-0d8b015e-b3b6-4f16-b2f7-d75cffd44107-0,Message content:Sorry, I am unable to know your name.
因为thread_id变成了3,所以它是完全不具备thread_id == 2这个线程中的任何信息的,但我们可以恢复以前的线程并继续进行对话,即:
1 | config = {"configurable": {"thread_id": "2"}} |
================================[1m Human Message [0m=================================
你还知道我叫什么吗?
==================================[1m Ai Message [0m==================================
是的,你告诉我你的名字是木羽。如果有其他需要帮助的地方,请随时告诉我!
==================================[1m Ai Message [0m==================================
Yes, you told me your name is Muyu. If there's anything else you need help with, please feel free to let me know!
短期记忆可让应用程序记住单个线程或对话中先前的交互,并且可以随时找到某个对话线程中继续之前的问答。这种情况其实就是我们在使用Web端应用程序的时候,可以切回到历史的聊天框继续问答的场景。LangGraph 将短期记忆作为代理状态的一部分进行管理,并通过线程范围的检查点进行持久化。此状态通常可以包括对话历史记录以及其他状态数据,例如上传的文件、检索的文档或生成的工件。通过将这些存储在图的状态中,程序可以访问给定对话的完整上下文,同时保持不同线程之间的分离。这就是其现实应用价值的体现。
那么接下来要考虑的是: 既然所实际进行存储的是 Checkpointer, 那么Checkpointer如何去做持久化的存储呢?正如我们上面使用的 MemorySaver, 虽然在当前的代码运行环境下可以去指定线程ID,获取到具体的历史信息,但是,一旦我们重启代码环境,则所有的数据都将被抹除。那么一种持久化的方法就是把每个checkpointer存储到本地的数据库中。
2.2 检查点的特定实现类型-SqliteSaver
SqliteSaver是checkponiter的第二种实现形式,不同于MemorySaver仅通过字典的形式将状态信息存储在当前的运行环境下,SqliteSaver做的是持久化存储,这个方法会把checkponiter实际的存储在本地的SQLite 数据库中,同时提供了异步环境下的实现AsyncSqliteSaver,适用于轻量级的应用落地场景。
SqliteSaver源码定义如下:
1 | class SqliteSaver(BaseCheckpointSaver[str]): |
SqliteSaver有两种存储形式,一种是类似于MemorySaver将checkpointer存储在内存中,另外一种是存储在sqlite数据库中。首先来看第一种:
内存存储(in-Memory Storage)是指存储在计算机主存储器 (RAM) 中的数据,这种类型的存储允许非常快速地访问和检索数据,因为它不涉及磁盘 I/O 操作。这个过程是将checkpointer最初保存到内存中,在需要时从内存中进行检索。内部完整的实现思路如下:
- Step 1. 安装依赖库
需要单独安装langgraph-checkpoint-sqlite库。
1 | # pip install langgraph-checkpoint-sqlite |
- Step 2. 定义内存的存储形式
通过:memory:方法指定在内存中存储checkpointer。代码如下:
1 | from langgraph.checkpoint.sqlite import SqliteSaver |
- Step 3. 构建checkpointer
这里为了演示SqliteSaver的执行原理,我们手动构建一个测试的checkpointer,其默认实现的是从State中进行提取。
1 | checkpoint_data = { |
- Step 3. 存储checkpointer
在源码中,from_conn_string方法使用了Python的contextmanager装饰器,所以它是一个生成器函数。这个方法创建的实例必须在with语句中使用。即我们需要修改其构建的方式,并通过put方法进行checkpointer配置的写入,代码如下:
1 | with SqliteSaver.from_conn_string(":memory:") as memory: |
1 | print(saved_config) |
{'configurable': {'thread_id': 'muyu123', 'checkpoint_ns': '', 'checkpoint_id': '1ef968fe-1eb4-6049-bfff'}}
除此之外,还可以通过list方法查看到thread_id下所有的检查点信息,代码如下:
1 | with SqliteSaver.from_conn_string(":memory:") as memory: |
CheckpointTuple(config={'configurable': {'thread_id': 'muyu123', 'checkpoint_ns': '', 'checkpoint_id': '1ef968fe-1eb4-6049-bfff'}}, checkpoint={'id': '1ef968fe-1eb4-6049-bfff'}, metadata={'timestamp': '2024-10-30T07:23:38.656547+00:00'}, parent_config=None, pending_writes=[])
内部原理如下图所示:

除此之外,SQLiteSaver还支持持久化存储。这种方式是指存储在非易失性介质上的数据,例如硬盘驱动器、SSD 或云存储,即使应用程序停止或系统断电,这种类型的存储也会保留数据。使用的方式也非常简单,只需要把from_conn_string中的:memory:更换为指向为本地的sqlite.db的文件即可,这允许数据持久保存,便于长期存取。代码如下:
1 | import sqlite3 |
CheckpointTuple(config={'configurable': {'thread_id': 'muyu123', 'checkpoint_ns': '', 'checkpoint_id': '1ef968fe-1eb4-6049-bfff'}}, checkpoint={'id': '1ef968fe-1eb4-6049-bfff'}, metadata={'timestamp': '2024-10-30T07:23:38.656547+00:00'}, parent_config=None, pending_writes=[])
可以使用标准的 SQL 语法直接与数据库进行交互。
1 | # 建立数据库连接 |
1 | # 打印所有表名 |
('checkpoints',)
('writes',)
1 | # 从检查点表中检索所有数据 |
Data in the 'checkpoints' table:
('muyu123', '', '1ef968fe-1eb4-6049-bfff', None, 'msgpack', b'\x81\xa2id\xb71ef968fe-1eb4-6049-bfff', b'{"timestamp": "2024-10-30T07:23:38.656547+00:00"}')
2.3 通过检查点给图增加持久性记忆
到目前为止,我们已经探索了memory、checkpointer、state和thead的概念,以及如何在内存中存储类似状态的对象。现在我们来看一下如何将不同形式的memory集成到ReAct代理流程中。
我们上节课介绍的LangGraph预构建组件ReAct,通过create_react_agent是内部已经实现了图的编译过程,如果想加入memory,则只需要在执行create_react_agent方法时,新增一个checkpointer参数来接收,如下代码所示:
1 | from langchain_core.tools import tool |
1 | tools = [get_weather] |
1 | if not os.environ.get("OPENAI_API_KEY"): |
创建ReAct代理的时候添加memory,代码如下:
1 | from langgraph.checkpoint.sqlite import SqliteSaver |
================================[1m Human Message [0m=================================
你好,我叫木羽
==================================[1m Ai Message [0m==================================
你好,木羽!有什么我可以帮助你的吗?
================================[1m Human Message [0m=================================
请问我叫什么?
==================================[1m Ai Message [0m==================================
你自我介绍时说你的名字是木羽。
但这种定义方法是不能跨单元传播的,比如我们在一个新的cell中再次对上面创建的图进行问答:
1 | for chunk in graph.stream({"messages": ["请问我叫什么?"]}, config, stream_mode="values"): |
---------------------------------------------------------------------------
ProgrammingError Traceback (most recent call last)
Cell In[118], line 1
----> 1 for chunk in graph.stream({"messages": ["请问我叫什么?"]}, config, stream_mode="values"):
2 chunk["messages"][-1].pretty_print()
File ~\anaconda3\envs\agent\Lib\site-packages\langgraph\pregel\__init__.py:1223, in Pregel.stream(self, input, config, stream_mode, output_keys, interrupt_before, interrupt_after, debug, subgraphs)
1219 if "custom" in stream_modes:
1220 config[CONF][CONFIG_KEY_STREAM_WRITER] = lambda c: stream.put(
1221 ((), "custom", c)
1222 )
-> 1223 with SyncPregelLoop(
1224 input,
1225 stream=StreamProtocol(stream.put, stream_modes),
1226 config=config,
1227 store=store,
1228 checkpointer=checkpointer,
1229 nodes=self.nodes,
1230 specs=self.channels,
1231 output_keys=output_keys,
1232 stream_keys=self.stream_channels_asis,
1233 debug=debug,
1234 ) as loop:
1235 # create runner
1236 runner = PregelRunner(
1237 submit=loop.submit,
1238 put_writes=loop.put_writes,
1239 )
1240 # enable subgraph streaming
File ~\anaconda3\envs\agent\Lib\site-packages\langgraph\pregel\loop.py:727, in SyncPregelLoop.__enter__(self)
725 raise CheckpointNotLatest
726 elif self.checkpointer:
--> 727 saved = self.checkpointer.get_tuple(self.checkpoint_config)
728 else:
729 saved = None
File ~\anaconda3\envs\agent\Lib\site-packages\langgraph\checkpoint\sqlite\__init__.py:213, in SqliteSaver.get_tuple(self, config)
178 """Get a checkpoint tuple from the database.
179
180 This method retrieves a checkpoint tuple from the SQLite database based on the
(...)
210 CheckpointTuple(...)
211 """ # noqa
212 checkpoint_ns = config["configurable"].get("checkpoint_ns", "")
--> 213 with self.cursor(transaction=False) as cur:
214 # find the latest checkpoint for the thread_id
215 if checkpoint_id := get_checkpoint_id(config):
216 cur.execute(
217 "SELECT thread_id, checkpoint_id, parent_checkpoint_id, type, checkpoint, metadata FROM checkpoints WHERE thread_id = ? AND checkpoint_ns = ? AND checkpoint_id = ?",
218 (
(...)
222 ),
223 )
File ~\anaconda3\envs\agent\Lib\contextlib.py:137, in _GeneratorContextManager.__enter__(self)
135 del self.args, self.kwds, self.func
136 try:
--> 137 return next(self.gen)
138 except StopIteration:
139 raise RuntimeError("generator didn't yield") from None
File ~\anaconda3\envs\agent\Lib\site-packages\langgraph\checkpoint\sqlite\__init__.py:169, in SqliteSaver.cursor(self, transaction)
167 with self.lock:
168 self.setup()
--> 169 cur = self.conn.cursor()
170 try:
171 yield cur
ProgrammingError: Cannot operate on a closed database.
出现报错的原因是因为脱离了上下文的环境。每次使用 SqliteSaver.from_conn_string(":memory:") 时,都会创建一个新的内存数据库实例,因此无法保持之前会话的状态。内存数据库(:memory:)是临时的,只存在于该数据库连接的生命周期内,一旦连接关闭,数据库就会消失。所以一种比较合适的写法是使用 contextlib.ExitStack 来作为管理和组织多个上下文管理器,这个方法可以让我们在一个统一的上下文管理堆栈中注册多个上下文管理器,并确保它们按正确的顺序(即最后进入的首先退出)被关闭。所以代码如下:
1 | from contextlib import ExitStack |
上述代码实现的机制是:
- 创建
ExitStack实例:stack = ExitStack()创建了一个可以管理多个上下文管理器的堆栈。 - 注册上下文管理器:
checkpointer = stack.enter_context(SqliteSaver.from_conn_string(":memory:"))这一行将SqliteSaver.from_conn_string(":memory:")注册到了stack中。SqliteSaver.from_conn_string返回的上下文管理器对象会被ExitStack管理,这意味着只有退出stack的上下文(即调用stack.close()),与之相关的SqliteSaver才会自动关闭。
1 | graph = create_react_agent(llm, tools=tools, checkpointer=checkpointer) |
1 | config = {"configurable": {"thread_id": "1"}} |
================================[1m Human Message [0m=================================
你好,我叫木羽
==================================[1m Ai Message [0m==================================
你好,木羽!有什么我可以帮助你的吗?
================================[1m Human Message [0m=================================
请问我叫什么?
==================================[1m Ai Message [0m==================================
你说你叫木羽。有什么我可以帮你的吗?
1 | config = {"configurable": {"thread_id": "1"}} |
================================[1m Human Message [0m=================================
帮我查一下北京的天气
==================================[1m Ai Message [0m==================================
Tool Calls:
get_weather (call_sXmT2s7DY5ITk66G2ixkly4C)
Call ID: call_sXmT2s7DY5ITk66G2ixkly4C
Args:
location: Beijing
=================================[1m Tool Message [0m=================================
Name: get_weather
{"coord": {"lon": 116.3972, "lat": 39.9075}, "weather": [{"id": 803, "main": "Clouds", "description": "\u591a\u4e91", "icon": "04d"}], "base": "stations", "main": {"temp": 20.94, "feels_like": 20.24, "temp_min": 20.94, "temp_max": 20.94, "pressure": 1022, "humidity": 44, "sea_level": 1022, "grnd_level": 1016}, "visibility": 10000, "wind": {"speed": 1.97, "deg": 185, "gust": 3.41}, "clouds": {"all": 84}, "dt": 1730450256, "sys": {"type": 1, "id": 9609, "country": "CN", "sunrise": 1730414591, "sunset": 1730452360}, "timezone": 28800, "id": 1816670, "name": "Beijing", "cod": 200}
==================================[1m Ai Message [0m==================================
北京当前的天气情况如下:
- **天气情况**: 多云
- **气温**: 20.94°C
- **体感温度**: 20.24°C
- **气压**: 1022 hPa
- **湿度**: 44%
- **风速**: 1.97 m/s,风向 185°
- **云量**: 84%
如果你需要更多信息,请告诉我!
1 | config = {"configurable": {"thread_id": "1"}} |
================================[1m Human Message [0m=================================
请问我刚才问了什么问题?
==================================[1m Ai Message [0m==================================
你刚才问了关于北京的天气情况。有什么其他需要帮助的吗?
1 | stack.close() |
这是一个更灵活的方法,适用于同步的环境,其中代码可以跨单元传播,并且仍然可以使用上下文信息。异步版本也是类似的实现思路:
1 | import asyncio |
================================[1m Human Message [0m=================================
帮我查一下北京的天气
==================================[1m Ai Message [0m==================================
Tool Calls:
get_weather (call_NhT6uWHomFuKlELcp6lNDG6W)
Call ID: call_NhT6uWHomFuKlELcp6lNDG6W
Args:
location: Beijing
=================================[1m Tool Message [0m=================================
Name: get_weather
{"coord": {"lon": 116.3972, "lat": 39.9075}, "weather": [{"id": 803, "main": "Clouds", "description": "\u591a\u4e91", "icon": "04d"}], "base": "stations", "main": {"temp": 20.94, "feels_like": 20.24, "temp_min": 20.94, "temp_max": 20.94, "pressure": 1022, "humidity": 44, "sea_level": 1022, "grnd_level": 1016}, "visibility": 10000, "wind": {"speed": 1.97, "deg": 185, "gust": 3.41}, "clouds": {"all": 84}, "dt": 1730450256, "sys": {"type": 1, "id": 9609, "country": "CN", "sunrise": 1730414591, "sunset": 1730452360}, "timezone": 28800, "id": 1816670, "name": "Beijing", "cod": 200}
==================================[1m Ai Message [0m==================================
北京当前的天气状况如下:
- 天气:多云
- 温度:20.94°C
- 体感温度:20.24°C
- 最低温度:20.94°C
- 最高温度:20.94°C
- 气压:1022 hPa
- 湿度:44%
- 能见度:10,000 米
- 风速:1.97 米/秒,风向:185°
- 云量:84%
希望这些信息对你有帮助!
1 | async for chunk in graph.astream({"messages": ["我刚才问了你什么问题"]}, config, stream_mode="values"): |
================================[1m Human Message [0m=================================
我刚才问了你什么问题
==================================[1m Ai Message [0m==================================
你刚才问我关于北京的天气情况。
自然,也可以去处理图的事件流,比如:
1 | async for event in graph.astream_events({"messages": ["请你非常详细的介绍一下你自己"]}, config, version="v2"): |
我是|一个|人工|智能|助手|,|基|于|自然|语言|处理|和|机器|学习|技术|构|建|,|旨|在|为|用户|提供|信息|查询|、|问题|解|答|和|任务|执行|等|多|种|服务|。|以下|是|我|更|详细|的|介绍|:
|###| 技|术|架|构|
|1|.| **|自然|语言|处理| (|N|LP|)**|:
| | -| **|文本|理解|**|:| 我|能够|解析|和|理解|用户|的|输入|,|识|别|意|图|和|提|取|关|键信|息|。
| | -| **|语|义|分析|**|:| 使用|语|义|分析|技术|来|理解|上下|文|,|确保|提供|相关|和|准确|的|回答|。
|2|.| **|机器|学习| (|ML|)**|:
| | -| **|模型|训练|**|:| 借|助|大型|数据|集|和|深|度|学习|算法|进行|训练|,以|提高|识|别|和|生成|能力|。
| | -| **|持续|学习|**|:| |通过|用户|交|互|和|反馈|,不|断|更新|和|提升|我的|模型|能力|。
|3|.| **|数据|来源|**|:
| | -| **|多|样|化|数据|**|:| 我|拥有|广|泛|的数据|来源|,|涵|盖|科学|、|技术|、|文化|、|历史|等|多个|领域|。
| | -| **|最新|更新|**|:| 我的|知识|库|定|期|更新|,以|确保|提供|最新|的信息|和|趋势|。
|###| 功|能|和|服务|
|1|.| **|信息|查询|**|:
| | -| **|天气|预|报|**|:| 提|供|全球|各|地|的|实时|天气|信息|。
| | -| **|新闻|摘要|**|:| 汇|总|和|提供|最新|的|全球|新闻|头|条|。
| | -| **|百科|知识|**|:| 回|答|有关|科学|、|历史|、|文化|等|领域|的|常|见|问题|。
|2|.| **|任务|执行|**|:
| | -| **|日|历|管理|**|:| 设置|提醒|和|安排|日|程|。
| | -| **|翻|译|服务|**|:| 支|持|多|语言|文本|的|翻|译|。
| | -| **|计算|服务|**|:| |进行|数学|计算|和|单位|换|算|。
|3|.| **|用户|交|互|**|:
| | -| **|多|语言|支持|**|:| 能|够|用|多|种|语言|与|用户|交流|。
| | -| **|上下|文|保持|**|:| 在|对|话|中|保持|上下|文|,|提供|连续|对|话|体验|。
|###| |设计|原则|
|1|.| **|用户|隐|私|**|:
| | -| **|数据|保护|**|:| 不|存|储|用户|的|个人|数据|,|确保|隐|私|安全|。
| | -| **|透明|性|**|:| 提|供|明确|的信息|来源|和|算法|透明|性|。
|2|.| **|准确|性|和|可靠|性|**|:
| | -| **|验证|信息|**|:| 努|力|提供|经过|验证|的|准确|信息|。
| | -| **|用户|反馈|**|:| 借|助|用户|反馈|来|纠|正|错误|和|提升|服务|质量|。
|3|.| **|易|用|性|**|:
| | -| **|直|观|设计|**|:| 简|化|用户|界|面|,|提供|直|观|的|用户|体验|。
| | -| **|响应|迅|速|**|:| 确|保|快速|响应|用户|请求|,|提升|交|互|效率|。
|###| |未来|展|望|
|1|.| **|功能|扩|展|**|:
| | -| 不|断|增加|新的|功能|和|服务|,以|满足|用户|不断|变化|的|需求|。
|
|2|.| **|技术|创新|**|:
| | -| 引|入|更多|前|沿|技术|,如|情|感|识|别|、|个|性|化|推荐|等|,|提升|互动|体验|。
|如果|你|有|任何|问题|或|需要|进一步|的|帮助|,请|随|时|让我|知道|!|
1 | await stack.aclose() |
对于SqliteSaver的使用也完全是一样的,大家可以自行进行尝试。
总的来说,LangGraph 框架中的Memory通过状态管理与检查点与 thread_id 进行绑定,从而隔离不同线程的记忆和状态,防止并发交互之间的干扰,保证每个线程独立运行。总体而言,thread_id 是 LangGraph 中组织和管理记忆的关键机制,可实现有效的状态跟踪和交互连续性。但是,通过thread_id不能实现的是:跨线程的交互。我们虽然可以通过thread_id去中断或者恢复某个对话,但是让不同线程间共享各自的消息,在checkpointer的实现机制下并不能做到,所以有了LangGraph的长期记忆的实现模块。
3、长期记忆和Store(仓库)
仅使用checkpointer,我们无法做到跨线程共享信息。这激发了对Store的需求。LangGraph通过BaseStore接口提供内置文档存储。与通过线程 ID 保存状态的checkpointer不同,存储使用自定义命名空间来组织数据。常见用例包括存储用户配置文件、构建知识库以及管理所有线程的全局首选项。具体的实现形式是:LangGraph 将长期记忆作为 JSON 文档存储在Store中,每个memory都组织在自定义namespace(类似于文件夹)和不同的key (例如文件名)下。命名空间通常包含用户或组织 ID 或其他标签,以便更轻松地组织信息。这种结构可以实现存储器的分层组织。然后通过内容过滤器支持跨命名空间搜索。
整体而言,LangGraph 中的长期记忆允许系统保留不同对话或会话中的信息。与线程范围的短期内存不同,长期内存保存在自定义“命名空间”中。

Store的实现源码:https://reference.langchain.com/python/langgraph/store/
具体的实现方法,是我们可以定义一个InMemoryStore来跨线程存储有关用户的信息。InMemoryStore会与checkpointer协同工作:由checkpointer将状态保存到线程,而InMemoryStore允许我们存储任意信息以供跨线程访问。我们看一下其实现细节:
1 | from langgraph.store.memory import InMemoryStore |
namespase的类型是tuple,需要一个键值对。可以理解为:我们以 user_id=1这个人的电脑创建了一个memories文件夹,所有这个人的数据,都存存放在这个文件夹中。
1 | user_id = "1" |
接下来使用.put方法将memory保存到存储中的命名空间中。每个memory都有唯一的一个对应的id.
1 | import uuid |
当创建完成后,可以使用store.search读取命名空间中的记忆,这将以列表的形式返回给定用户的所有记忆。最近的记忆是列表中的最后一个。
1 | memories = in_memory_store.search(namespace_for_memory) |
{'value': {'user': '你好,我叫木羽'},
'key': '6db0b2e0-8e51-4fbd-b3e1-761edf221ea0',
'namespace': ['1', 'memories'],
'created_at': '2024-11-01T08:45:59.453639+00:00',
'updated_at': '2024-11-01T08:45:59.453639+00:00'}
理解了上述过程后,就可以使用 LangGraph 中的in_memory_store方法了,当我们在编译图表时传递 store 对象,就会允许图中的每个节点访问 store,定义节点函数时的时候,就可以定义store关键字参数,LangGraph 会自动传递编译图时使用的 store 对象,代码如下所示:
1 | import getpass |
接下来我们进行测试:
1 | config = {"configurable": {"thread_id": "10"}, "user_id": "6"} |
================================[1m Human Message [0m=================================
你好,我是木羽
==================================[1m Ai Message [0m==================================
你好,木羽!很高兴见到你。有什么我可以帮助你的吗?
1 | config = {"configurable": {"thread_id": "10"}, "user_id": "6"} |
================================[1m Human Message [0m=================================
你知道我叫什么吗?
==================================[1m Ai Message [0m==================================
你刚才告诉我你叫木羽。有什么我可以帮助你的吗?
这一次我们传入相同的user_id,但开启一个新的线程:
1 | config = {"configurable": {"thread_id": "11"}, "user_id": "6"} |
================================[1m Human Message [0m=================================
你知道我叫什么吗?
==================================[1m Ai Message [0m==================================
你刚才告诉我你叫木羽。有什么我可以帮助你的吗?
能够发现,我们已经正确的实现了跨线程的记忆能力。而如果使用新的user_id,将会开启全新的交互。
1 | config = {"configurable": {"thread_id": "18"}, "user_id": "8"} |
================================[1m Human Message [0m=================================
你知道我叫什么吗?
==================================[1m Ai Message [0m==================================
抱歉,我无法知道你的名字。你可以告诉我你的名字,或者有其他问题我可以帮助你解决吗?
我们可以直接去访问store查看存储的memory信息。
1 | for memory in in_memory_store.search(("memories", "6")): |
{'data': '你好,我是木羽'}
{'data': '你好,木羽!很高兴见到你。有什么我可以帮助你的吗?'}
{'data': '你知道我叫什么吗?'}
{'data': '你刚才告诉我你叫木羽。有什么我可以帮助你的吗?'}
{'data': '你知道我叫什么吗?'}
{'data': '你刚才告诉我你叫木羽。有什么我可以帮助你的吗?'}
1 | for memory in in_memory_store.search(("memories", "8")): |
{'data': '你知道我叫什么吗?'}
{'data': '抱歉,我无法知道你的名字。你可以告诉我你的名字,或者有其他问题我可以帮助你解决吗?'}
有效的记忆管理可以增强代理维护上下文、从过去的经验中学习以及随着时间的推移做出更明智决策的能力。大多数AI Agent构建的应用程序都需要记忆来在多个交互中共享上下文。在 LangGraph 中,这种记忆就是通过checkpointer 和 store 来做持久性,从而添加到任何StateGraph中。最常见的用例之一是用它来跟踪对话历史记录,但是也有很大的优化空间,因为随着对话变得越来越长,历史记录会累积并占用越来越多的上下文窗口,导致对大模型的调用更加昂贵和耗时,并且可能会出错。为了防止这种情况发生,我们一般是需要借助一些优化手段去管理对话历史记录,同时更加适配生产环境的 PostgresSaver / AsyncPostgresSaver )高级检查点,我们也将随着知识点的进一步补充后,再结合实际的案例进行详细的讲解。