LangGraph中Human-in-the-loop应用实战
AI Agent技术的应用,其核心目标是赋予应用程序自主和循环处理复杂任务的能力。得益于当前大模型的强大能力以及比较成熟的开发框架,这类应用已经能够在现阶段实际落地并被广泛应用。我们基于LangGraph展开讨论,到目前为止,我们已经介绍了其核心功能组件,每个组件在应用中发挥着不同的作用,具体包括:
- 节点、边和状态模式:用于搭建图结构的具体方法,应用程序的核心骨架。
- Router Agent 和 Tool Calling Agent 架构:实现任务路由和工具调用的逻辑,是一切复杂
Agent架构的底层支撑。 - ReAct自主循环代理:实现自主决策和交互的代理系统,支持复杂任务的执行。
- 基于
checkpointer的短期记忆管理:实现动态的、上下文相关的短期记忆,应对任务中的即时信息需求。 - 基于
store的长期记忆管理:提供持久化的长期记忆支持,便于系统根据反馈自主迭代学习和信息积累。
掌握上述知识点,我们现在能够实现的最复杂的一种AI Agent逻辑是:具备多外部工具支持的完全自主循环代理结构,同时具备多轮对话的上下文记忆能力。而具备这种能力的系统其实已经足够有效地应对大部分AI应用场景的需求,并且已经完全涵盖了LangGraph底层构建生产级别Agent的所必须掌握的知识点 。最后,我们要进行补充的是:这种完全自主循环代理构建起来的应用,在现实落地场景中,会衍生出什么迫切的需求?
一个有趣且现实的情况是:我们希望AI Agent能够帮助我们自主处理各种任务,但当它现在有能力做到时,我们又开始担心它可能做出不当的决策,尤其是涉及到高风险操作时。比如,Agent 可能会不小心删除生产环境中的数据库,或是转移账户中的余额等敏感数据。这些操作是无法容忍的。因此,在自主代理类架构下衍生出的非常明确的一类需求是:能否在保持Agent自主决策的基础上,对某些可以预见或计划的关键节点引入人工干预,暂时中止其自我决策过程,转而由人工介入进行审批和确认,再让其继续执行后续任务?比如以下场景:
- 删除数据库操作:当
Agent决定删除数据库时,可以先中止操作,要求人工确认是否继续执行。经过人工确认后,Agent才继续删除数据库并执行后续操作。 - 机票改签操作:当
Agent决定更改机票时,系统会向用户发出通知,等待用户确认是否同意改签,用户点击确认后,Agent才会继续执行改签操作。 - …….
通过这种方式,既能保持Agent的自主性,又能避免出现意外或不可控的风险,实现人机协作的平衡。而实现这种功能的技术,在Agent技术领域会被普遍称之为Human-in-the-loop(HIL)。
1、LangGraph中的HIL
LangGraph底层是通过图结构来进行构建,并由状态做消息的传递,那么对于这样的结构来说,如果我们想在这样的架构中加入人工的介入流程,能操作的大致思路应该是:通过Router Agent去做判断,如果生成的响应触发了某种条件,就在原本要正常进入的节点之前先停止,等待人工的确认,再决定要不要执行,或者执行什么逻辑。在这个过程中,有几种常见的用户交互模式,分别是:
- 批准(Approval):在代理的执行过程中,人工暂停代理的自主工作流,向用户展示当前的状态,并批准或者不批准执行该操作。
- 编辑(Editing):在需要的时候,人工可以暂停代理,向用户展示当前的状态,并允许用户对代理的状态进行编辑。
- 输入(Input):专门设计一个图节点来收集用户的输入,并将这些输入直接用于更新代理的状态。
在LangGraph的设计思路下,HIL通过战略性地放置断点(breakpoint)来实现的。这些断点会在关键点停止图的执行。在暂停期间,Agent将等待用户输入,利用这段时间收集响应,将它们集成到图状态中,并顺利继续进行,从而实现用户和代理之间的协作和交互式体验。这个交互过程在LangGraph框架下的具体实现思路如下图所示:

LangGraph能够在中断后继续运行的核心在于我们之前介绍的checkpointer组件。这个组件能够在一个独立的线程中保存图中每个节点的状态。由于这些信息被持久化保存(包括将内存用作持久存储),我们就可以随时提取并修改图产生的数据。更改完成后,再将这些数据重新传回到图中以继续运行流程。这一机制是LangGraph已成功实现的功能。由此可见 Human-in-the-loop (HIL) 并不是一个全新的组件,而是基于LangGraph底层的构建组件延展出来的一种实现方法。那这里我们就需要清楚两个概念,其一是用于中断两个本应顺序执行节点的操作,在LangGraph中称其为breakpoint(断点),其二是breakpoint是构建在checkpointer之上的。
因此,当我们需要在定义的图结构中加入人机交互,这个图必须具备的两个核心参数正如compile()方法中的源码所示:
LangGraph Graph Compile :https://reference.langchain.com/python/langgraph/graphs/#langgraph.graph.state.StateGraph.compile
1 | def compile( |
其中,checkpointer参数可以接收任意类型的checkpointer,用来保存图的状态。而interrupt_before和interrupt_after参数,接收图中某个节点的名称,将其作为breakpoint,起到的作用是在该节点之前/之后中断图的继续运行。我们来看一个具体的应用案例。
2、标准图结构中如何添加断点
如下代码实现的业务场景是一个自动化的人机交互流程,用于执行内容删除这种高度敏感性的操作。我们定义两个主要的功能节点:call_model和execute_users。call_model节点处理大模型的调用和响应,如果用户输入包含“删除”的内容,则会触发需要人工审批的流程。execute_users节点根据人工审核的结果来决定最终的响应内容。如下代码所示:
1 | import getpass |
1 | from typing import TypedDict |
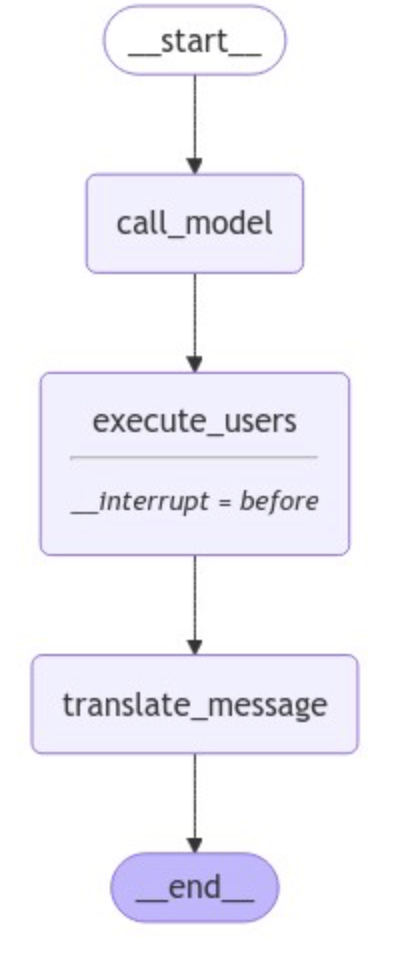
在添加了breakpoint (断点)后的图结构中,它的运行逻辑将变成:只要到达被设置为breakpoint的节点时,图就会中止运行。这里我们进行一个实际的调用测试来理解这个过程,代码如下所示:
1 | # 创建一个线程 |
{'user_input': '我将在数据库中删除 id 为 muyu 的所有信息'}
{'user_input': '我将在数据库中删除 id 为 muyu 的所有信息', 'user_approval': '用户输入的指令是:我将在数据库中删除 id 为 muyu 的所有信息, 请人工确认是否执行!'}
通过输出结果,我们可以观察到在执行到execute_users节点之前就暂停了,它将等待人工介入以决定是否继续执行。这就是breakpointer(断点)的关键作用。在这个阶段,我们就可以审查并调整图的状态,而关键的处理逻辑是:要修改或确认全局状态模式中user_approval字段的值,从而指导execute_users节点的行为。
通过get_state()方法,可以查看到截至断点breakpoint前,图的运行过程中都产生了哪些状态信息:
1 | snapshot = graph.get_state(config) |
StateSnapshot(values={'user_input': '我将在数据库中删除 id 为 muyu 的所有信息', 'user_approval': '用户输入的指令是:我将在数据库中删除 id 为 muyu 的所有信息, 请人工确认是否执行!'}, next=('execute_users',), config={'configurable': {'thread_id': '1', 'checkpoint_ns': '', 'checkpoint_id': '1ef9f1de-041a-64e2-8001-41df6d4d90d6'}}, metadata={'source': 'loop', 'writes': {'call_model': {'user_input': '我将在数据库中删除 id 为 muyu 的所有信息', 'user_approval': '用户输入的指令是:我将在数据库中删除 id 为 muyu 的所有信息, 请人工确认是否执行!'}}, 'step': 1, 'parents': {}}, created_at='2024-11-10T04:40:13.704112+00:00', parent_config={'configurable': {'thread_id': '1', 'checkpoint_ns': '', 'checkpoint_id': '1ef9f1de-0417-6dde-8000-f38b5281a68b'}}, tasks=(PregelTask(id='97ac593e-6b41-43e9-b81b-ee0e1dc49c01', name='execute_users', path=('__pregel_pull', 'execute_users'), error=None, interrupts=(), state=None),))
我们先来看如何在图中止运行后,在图状态中添加用户的决策。
为实现这一点,我们可以手动设置snapshot.values['user_approval']为’是’,用以说明在即将执行的execute_users节点,人工审批的状态被手动设定为同意。接下来,使用graph.update_state(config, snapshot.values)来更新状态图中的状态。这个调用将状态图中的当前状态更新为包含了新的user_approval值的snapshot.values。
1 | snapshot.values['user_approval']='是' |
{'configurable': {'thread_id': '1',
'checkpoint_ns': '',
'checkpoint_id': '1ef9f1e1-81db-6516-8002-8b1478becc9d'}}
修改完状态后,如果想让图基于breakpoint继续执行后续的操作,则只需要在astream方法中将input参数设置为 None, 则会让图形从上次中断的地方继续。如下代码所示:
1 | async for chunk in graph.astream(None, config, stream_mode="values"): |
{'user_input': '我将在数据库中删除 id 为 muyu 的所有信息', 'user_approval': '是'}
{'user_input': '我将在数据库中删除 id 为 muyu 的所有信息', 'model_response': AIMessage(content='您的删除请求已经获得管理员的批准并成功执行。如果您有其他问题或需要进一步的帮助,请随时联系我们。', additional_kwargs={}, response_metadata={}), 'user_approval': '是'}
{'user_input': '我将在数据库中删除 id 为 muyu 的所有信息', 'model_response': AIMessage(content='Your deletion request has been approved by the administrator and successfully executed. If you have any other questions or need further assistance, please feel free to contact us.', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 31, 'prompt_tokens': 53, 'total_tokens': 84, 'prompt_tokens_details': {'cached_tokens': 0, 'audio_tokens': 0}, 'completion_tokens_details': {'reasoning_tokens': 0, 'audio_tokens': 0, 'accepted_prediction_tokens': 0, 'rejected_prediction_tokens': 0}}, 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_0ba0d124f1', 'finish_reason': 'stop', 'logprobs': None}, id='run-1db8104c-678e-49e3-b468-f7c77f6fc57d-0', usage_metadata={'input_tokens': 53, 'output_tokens': 31, 'total_tokens': 84, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}}), 'user_approval': '是'}
再次运行一轮新的对话:
1 | # 运行图,直至到断点的节点 |
{'user_input': '我将在数据库中删除 id 为 muyu2222 的所有信息', 'model_response': AIMessage(content='Your deletion request has been approved by the administrator and successfully executed. If you have any other questions or need further assistance, please feel free to contact us.', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 31, 'prompt_tokens': 53, 'total_tokens': 84, 'prompt_tokens_details': {'cached_tokens': 0, 'audio_tokens': 0}, 'completion_tokens_details': {'reasoning_tokens': 0, 'audio_tokens': 0, 'accepted_prediction_tokens': 0, 'rejected_prediction_tokens': 0}}, 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_0ba0d124f1', 'finish_reason': 'stop', 'logprobs': None}, id='run-1db8104c-678e-49e3-b468-f7c77f6fc57d-0', usage_metadata={'input_tokens': 53, 'output_tokens': 31, 'total_tokens': 84, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}}), 'user_approval': '是'}
{'user_input': '我将在数据库中删除 id 为 muyu2222 的所有信息', 'model_response': AIMessage(content='Your deletion request has been approved by the administrator and successfully executed. If you have any other questions or need further assistance, please feel free to contact us.', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 31, 'prompt_tokens': 53, 'total_tokens': 84, 'prompt_tokens_details': {'cached_tokens': 0, 'audio_tokens': 0}, 'completion_tokens_details': {'reasoning_tokens': 0, 'audio_tokens': 0, 'accepted_prediction_tokens': 0, 'rejected_prediction_tokens': 0}}, 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_0ba0d124f1', 'finish_reason': 'stop', 'logprobs': None}, id='run-1db8104c-678e-49e3-b468-f7c77f6fc57d-0', usage_metadata={'input_tokens': 53, 'output_tokens': 31, 'total_tokens': 84, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}}), 'user_approval': '用户输入的指令是:我将在数据库中删除 id 为 muyu2222 的所有信息, 请人工确认是否执行!'}
1 | snapshot.values['user_approval']='否' |
{'configurable': {'thread_id': '1',
'checkpoint_ns': '',
'checkpoint_id': '1ef9f1e4-11ad-6702-8008-bbe94bb62ca4'}}
1 | async for chunk in graph.astream(None, config, stream_mode="values"): |
{'user_input': '我将在数据库中删除 id 为 muyu 的所有信息', 'model_response': AIMessage(content='Your deletion request has been approved by the administrator and successfully executed. If you have any other questions or need further assistance, please feel free to contact us.', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 31, 'prompt_tokens': 53, 'total_tokens': 84, 'prompt_tokens_details': {'cached_tokens': 0, 'audio_tokens': 0}, 'completion_tokens_details': {'reasoning_tokens': 0, 'audio_tokens': 0, 'accepted_prediction_tokens': 0, 'rejected_prediction_tokens': 0}}, 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_0ba0d124f1', 'finish_reason': 'stop', 'logprobs': None}, id='run-1db8104c-678e-49e3-b468-f7c77f6fc57d-0', usage_metadata={'input_tokens': 53, 'output_tokens': 31, 'total_tokens': 84, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}}), 'user_approval': '否'}
{'user_input': '我将在数据库中删除 id 为 muyu 的所有信息', 'model_response': AIMessage(content='对不起,您当前的请求是高风险操作,管理员不允许执行!', additional_kwargs={}, response_metadata={}), 'user_approval': '否'}
{'user_input': '我将在数据库中删除 id 为 muyu 的所有信息', 'model_response': AIMessage(content="I'm sorry, your current request is a high-risk operation, and the administrator does not allow it to be executed!", additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 23, 'prompt_tokens': 44, 'total_tokens': 67, 'prompt_tokens_details': {'cached_tokens': 0, 'audio_tokens': 0}, 'completion_tokens_details': {'reasoning_tokens': 0, 'audio_tokens': 0, 'accepted_prediction_tokens': 0, 'rejected_prediction_tokens': 0}}, 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_0ba0d124f1', 'finish_reason': 'stop', 'logprobs': None}, id='run-3ebf09dd-b2ac-495d-9292-b5f947d76ceb-0', usage_metadata={'input_tokens': 44, 'output_tokens': 23, 'total_tokens': 67, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}}), 'user_approval': '否'}
以上是两种触发删除的高危风险审核的逻辑,而如果Agent接收的是普通的问答交互,不涉及高危险操作指令时,则可以直接将input参数设置为None,运行断点之后的图节点逻辑。如下代码所示:
1 | # 运行图,直至到断点的节点 |
{'user_input': '你好,请你介绍一下你自己', 'model_response': AIMessage(content='你好!我是一个人工智能助手,旨在帮助回答问题、提供信息和支持各种任务。我可以处理许多主题,包括科学、技术、历史、文化等。如果你有任何具体的问题或需要帮助的地方,请随时告诉我!', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 52, 'prompt_tokens': 14, 'total_tokens': 66, 'prompt_tokens_details': {'cached_tokens': 0, 'audio_tokens': 0}, 'completion_tokens_details': {'reasoning_tokens': 0, 'audio_tokens': 0, 'accepted_prediction_tokens': 0, 'rejected_prediction_tokens': 0}}, 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_0ba0d124f1', 'finish_reason': 'stop', 'logprobs': None}, id='run-715adbbc-5a09-4bfb-8b71-b626a2a8a306-0', usage_metadata={'input_tokens': 14, 'output_tokens': 52, 'total_tokens': 66, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}}), 'user_approval': '直接运行!'}
{'user_input': '你好,请你介绍一下你自己', 'model_response': AIMessage(content='你好!我是一个人工智能助手,旨在帮助回答问题、提供信息和支持各种任务。我可以处理许多主题,包括科学、技术、历史、文化等。如果你有任何具体的问题或需要帮助的地方,请随时告诉我!', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 52, 'prompt_tokens': 14, 'total_tokens': 66, 'prompt_tokens_details': {'cached_tokens': 0, 'audio_tokens': 0}, 'completion_tokens_details': {'reasoning_tokens': 0, 'audio_tokens': 0, 'accepted_prediction_tokens': 0, 'rejected_prediction_tokens': 0}}, 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_0ba0d124f1', 'finish_reason': 'stop', 'logprobs': None}, id='run-715adbbc-5a09-4bfb-8b71-b626a2a8a306-0', usage_metadata={'input_tokens': 14, 'output_tokens': 52, 'total_tokens': 66, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}}), 'user_approval': '直接运行!'}
{'user_input': '你好,请你介绍一下你自己', 'model_response': AIMessage(content='Hello! I am an artificial intelligence assistant designed to help answer questions, provide information, and support various tasks. I can handle many topics, including science, technology, history, culture, and more. If you have any specific questions or need assistance, please feel free to let me know!', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 58, 'prompt_tokens': 79, 'total_tokens': 137, 'prompt_tokens_details': {'cached_tokens': 0, 'audio_tokens': 0}, 'completion_tokens_details': {'reasoning_tokens': 0, 'audio_tokens': 0, 'accepted_prediction_tokens': 0, 'rejected_prediction_tokens': 0}}, 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_0ba0d124f1', 'finish_reason': 'stop', 'logprobs': None}, id='run-5e0539ba-b716-45d8-9409-9898b9910941-0', usage_metadata={'input_tokens': 79, 'output_tokens': 58, 'total_tokens': 137, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}}), 'user_approval': '直接运行!'}
等待人工输入是一种常见的 HIL 交互模式,它能够允许我们构建的代理向用户提出需要确认的问题,并等待确认输入后再继续。其中具体要执行的关键步骤是:
- 需要在图编译时通过
interrupt_before或者interrupt_after设置断点。 - 需要在图编译时设置一个
checkpointer来保存图的状态。 - 需要使用
.update_state来更新图的状态,其中要包含我们得到的人工响应。 - 恢复图的执行,等待图运行结束,输出最终的响应结果。
我们可以把上述过程构建成一个具备多轮对话形式的人机交互流程,如下代码所示:
1 | # 创建一个函数来封装对话逻辑 |
进行调用测试:
1 | # 初始化配置和状态存储 |
请输入您的消息(输入'退出'结束对话): 你好,请你介绍一下你自己
人工智能助理: Hello! I am an AI-driven language model designed to help users answer questions, provide information, and engage in conversation. I can handle a variety of topics, including technology, literature, history, culture, and more. If you have any questions or need assistance, please feel free to let me know!
请输入您的消息(输入'退出'结束对话): 什么是随机森林?
人工智能助理: Random Forest is an ensemble learning method primarily used for classification and regression tasks. It improves the accuracy and stability of the model by constructing multiple decision trees and combining their prediction results.
The main characteristics of Random Forest include:
1. **Ensemble Learning**: Random Forest reduces overfitting and enhances the model's generalization ability by combining the predictions of multiple decision trees.
2. **Randomness**: When building each decision tree, Random Forest randomly selects samples (with replacement) and features (randomly selecting features at each node split), which increases the diversity of the model and reduces correlations between models.
3. **Voting Mechanism**: For classification problems, Random Forest votes on the prediction results of all decision trees, ultimately choosing the category that appears most frequently; for regression problems, it takes the average of all tree predictions.
4. **Feature Importance**: Random Forest can evaluate the importance of each feature in the model, helping to understand the relationship between the model and the features.
Due to its high accuracy and robustness, Random Forest is widely used in various fields, including finance, healthcare, and market forecasting.
请输入您的消息(输入'退出'结束对话): 帮我删除 muyu 相关的数据信息
当前用户的输入是:帮我删除 muyu 相关的数据信息, 请人工确认是否执行!请回复 是/否。 是
人工智能助理: Your deletion request has been approved by the administrator and successfully executed. If you have any other questions or need further assistance, please feel free to contact us.
请输入您的消息(输入'退出'结束对话): 帮我删除 muyu 相关的课件信息数据
当前用户的输入是:帮我删除 muyu 相关的课件信息数据, 请人工确认是否执行!请回复 是/否。 否
人工智能助理: I'm sorry, your current request is a high-risk operation, and the administrator does not allow it to be executed!
请输入您的消息(输入'退出'结束对话): 退出
如上实现的功能所示,在图中的特定位置添加断点是启用人机协同的一种方法。在这种情况下,开发人员只要知道工作流中的哪个位置需要人工输入,只需在该特定图形节点之前或之后放置一个断点即可。LangGraph的breakpoint和HIL功能提供了比较完善的实现机制来做交互式的图执行,允许用户输入来指导或中断流程。在这个案例中,我们展示的人机交互策略特别适用于有明确工作流的业务场景。开发人员可以根据业务逻辑精确地确定哪些环节可能涉及高风险操作,并通过人工决策介入来提升Agent应用程序的稳定性和可靠性。
接下来我们可以更近一步,看一下在具备工具调用的Agent架构中如何去做断点的人工交互逻辑,这包含Tool Calling Agent 和 ReAct 两种模式。
3、复杂代理架构中如何添加动态断点
上面案例中实现的人机交互模式,我们可以在不同的用户输入决策下完全自定义具体需要执行的操作逻辑。而这样的交互过程,我们可以手动实现来理解这个中间过程,当然也可以在LangGraph框架的封装下,借助Router Agent的机制从节点内部来进行动态管理,尤其是在涉及工具调用的ReAct框架下,其特征会更明显,且可以更加清晰的帮助我们理解breakpoint在图执行过程中的内部逻辑。其基本过程如下图所示:

首先来考虑这样一个场景:对于Tool Calling Agent架构实现的应用程序,如果我们希望在执行任意一个工具之前,都需要由人工进行审核的话,那么这个过程就可以非常简单的通过如下代码来进行实现。这里我们先准备两个外部工具,一个用于实时检索互联网信息,一个用于检索实时天气。
1 | from langchain_core.tools import tool |
使用ToolNode组件将普通函数处理成实际可执行的对象。
1 | tools = [get_weather, fetch_real_time_info] |
定义大模型实例,这里使用GPT 4 模型进行演示。
1 | import getpass |
定义一个Router Function,用来根据大模型的实时响应判断是执行外部函数调用还是直接输出最终的响应。
1 | def should_continue(state): |
用于大模型交互的节点函数,其功能是接收用户的响应,使用GPT 4 模型生成具体的响应文本。
1 | def call_model(state): |
然后通过LangGraph基本构建图的方法,依次定义状态图 -> 向图中添加节点 - > 添加节点之间的边。
1 | workflow = StateGraph(MessagesState) |
<langgraph.graph.state.StateGraph at 0x20a31256910>
最后,如果想要在执行任意工具前都由人工介入进行确认,只需要在编译图的时候,在调用 action 节点之前添加一个breakpoint(断点)。如下所示:
1 | memory = MemorySaver() |
1 | # 生成可视化图像结构 |
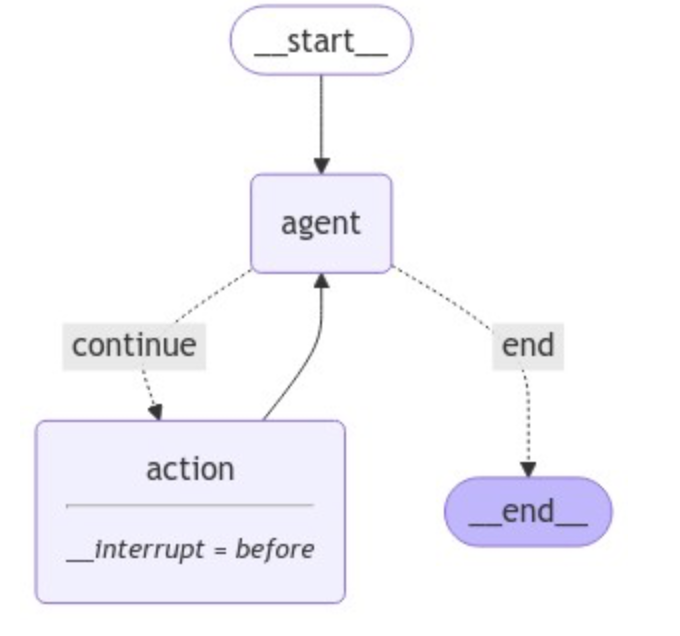
编译后,则可以开始与基于该图构建出来的 Agent 进行对话交互,如下代码所示:
1 | config = {"configurable": {"thread_id": "4"}} |
================================[1m Human Message [0m=================================
请帮我查一下北京的天气
==================================[1m Ai Message [0m==================================
Tool Calls:
get_weather (call_E3xVYypiHJDveSI2Wzc3t3oV)
Call ID: call_E3xVYypiHJDveSI2Wzc3t3oV
Args:
location: Beijing
从输出可以看到,与前几节课我们实践的执行过程不同,在添加了断点后,已经自动在需要执行工具操作前中断了执行。这里的处理逻辑其实和我们上面案例的实现方法基本保持一致。如果默认让它继续执行,则可以再次调用图的stream()方法,将其input参数设置为None。如下代码所示:
1 | for chunk in graph.stream(None, config, stream_mode="values"): |
==================================[1m Ai Message [0m==================================
Tool Calls:
get_weather (call_E3xVYypiHJDveSI2Wzc3t3oV)
Call ID: call_E3xVYypiHJDveSI2Wzc3t3oV
Args:
location: Beijing
=================================[1m Tool Message [0m=================================
Name: get_weather
{"coord": {"lon": 116.3972, "lat": 39.9075}, "weather": [{"id": 803, "main": "Clouds", "description": "\u591a\u4e91", "icon": "04d"}], "base": "stations", "main": {"temp": 18.94, "feels_like": 18.12, "temp_min": 18.94, "temp_max": 18.94, "pressure": 1022, "humidity": 47, "sea_level": 1022, "grnd_level": 1017}, "visibility": 10000, "wind": {"speed": 2.12, "deg": 30, "gust": 3.32}, "clouds": {"all": 81}, "dt": 1731214393, "sys": {"type": 1, "id": 9609, "country": "CN", "sunrise": 1731192816, "sunset": 1731229389}, "timezone": 28800, "id": 1816670, "name": "Beijing", "cod": 200}
==================================[1m Ai Message [0m==================================
北京当前的天气状况如下:
- **天气**: 多云
- **温度**: 18.94°C
- **体感温度**: 18.12°C
- **最低温度**: 18.94°C
- **最高温度**: 18.94°C
- **气压**: 1022 hPa
- **湿度**: 47%
- **能见度**: 10000 米
- **风速**: 2.12 米/秒,风向 30°
- **云量**: 81%
如果需要更多信息,请告诉我!
当input参数传入的值是None时,会传递状态模式中全部已产生的消息数据,所以它的执行过程看起来就像没有中断一样,按照我们构造的图结构顺利完成了所有节点的执行逻辑。对另外的一个fetch_real_time_info工具其实也是一样的,如果Agent判断需要调用的话,仍然会在执行前停止,等待人工批准。如下代码所示:
1 | config = {"configurable": {"thread_id": "4"}} |
================================[1m Human Message [0m=================================
最近 OpenAI 有哪些大动作?
==================================[1m Ai Message [0m==================================
Tool Calls:
fetch_real_time_info (call_iFdPUUMx0vAuM4PI7Fw7BazS)
Call ID: call_iFdPUUMx0vAuM4PI7Fw7BazS
Args:
query: OpenAI 最近的动态
1 | for chunk in graph.stream(None, config, stream_mode="values"): |
==================================[1m Ai Message [0m==================================
Tool Calls:
fetch_real_time_info (call_iFdPUUMx0vAuM4PI7Fw7BazS)
Call ID: call_iFdPUUMx0vAuM4PI7Fw7BazS
Args:
query: OpenAI 最近的动态
=================================[1m Tool Message [0m=================================
Name: fetch_real_time_info
[{"title": "OpenAI - IT之家", "link": "https://www.ithome.com/tags/openai/", "snippet": "北京时间今日凌晨,OpenAI在其大模型产品ChatGPT中新增了搜索功能,正式进军由Alphabet 旗下Google 长期主导的搜索领域。", "position": 1}]
==================================[1m Ai Message [0m==================================
最近,OpenAI 在其大模型产品 ChatGPT 中新增了搜索功能,正式进军由 Alphabet 旗下 Google 长期主导的搜索领域。这一举措标志着 OpenAI 在搜索技术领域的进一步发展。
如果你想了解更多细节,可以查看这篇文章:[OpenAI - IT之家](https://www.ithome.com/tags/openai/)。
像上面案例中在普通节点加入breakpoint一样,在Tool Calling的架构中很明显呈现出来的特性就是“一刀切”:要么整个流程完全停止,要么全部通过。而考虑现实情况,通常一个 Agent 会包含多达数十甚至上百个工具,但其中可能只有少数涉及到高风险或敏感操作的工具。那么是否可以在保留自主循环的同时,仅在Agent自行判断必须要开始执行敏感工具或操作时,才触发人工介入机制?这种做法更符合实际应用需求,由此才有了dynamic breakpoints (动态断点)的大规模应用。
动态断点指的是在图结构中,可以根据某些条件从给定节点内部动态的来中断图。其实在上面一个案例中已经有所涉及,即:
1 | def execute_users(state): |
并且在多轮对话run_dialogue的函数逻辑中,我们是通过代码的逻辑来对不同user_approval状态值采用不同的状态更新策略,即:
1 | if last_chunk["user_approval"] == f"用户输入的指令是:{last_chunk['user_input']}, 请人工确认是否执行!": |
4、案例:实现人机交互式信息管理系统应用
我们可以根据dynamic breakpoints (动态断点)的思路进一步扩展Agent的复杂程度。
下面的案例中,我们实现一个灵活且自主的天气信息管理系统,这个系统通过四个主要的工具函数来操作天气数据,这些函数包括查询、插入、和删除天气信息,以及获取实时天气。其中我们将删除功能作为高危敏感工具,使用dynamic breakpoints 的机制来控制,仅当用户的需求触发Agent判断需要执行该工具时,由人工介入决定是否执行删除数据操作,具体的工具函数描述如下:
获取实时天气(
get_weather):此工具允许用户输入城市名称,通过调用OpenWeather API获取该城市当前的天气情况,返回的数据以JSON格式呈现,包括温度、天气状况等信息。插入天气信息到数据库(
insert_weather_to_db):这个工具用于将获取的天气数据存入数据库。从数据库查询天气信息(
query_weather_from_db):此工具允许用户通过城市名查询已存储的天气信息。从数据库删除天气信息(
delete_weather_from_db):允许用户删除指定城市的天气信息。
在明确了系统的功能需求之后,我们现在开始进行具体的代码实现。首先,既然涉及到数据库的操作,我们先建立一个具体的数据表。
1 | from sqlalchemy import create_engine, Column, Integer, String, Float |
创建完成后,可以通过可视化工具查看数据库表的创建情况(我这里使用的是Navicat):

依次定义外部工具函数库。代码如下:
1 | from langchain_core.tools import tool |
使用ToolNode构建外部工具库,代码如下:
1 | from langgraph.prebuilt import ToolNode |
接下来定义用于Agent的基座模型,并绑定外部工具库。
1 | import getpass |
call_model 函数用来接收用户的输入请求,由大模型进行用户意图分析。
1 | def call_model(state): |
should_continue 函数为Router Function,当Agent判断用户的需求中需要触发删除的高危操作时,则需要进入到高危操作的具体处理策略中。
1 | def should_continue(state): |
run_tool 函数内的逻辑为高危操作工具的执行逻辑,需要人工批准后决定是否执行。
1 | def run_tool(state): |
节点函数和路由函数定义完毕后,开始构建图的完整结构。代码如下:
1 | workflow = StateGraph(MessagesState) |
<langgraph.graph.state.StateGraph at 0x20a00c5e650>
最后,在编译图的阶段,添加checkpointer 与具体的 breakpoint。
1 | memory = MemorySaver() |
1 | from IPython.display import Image, display |
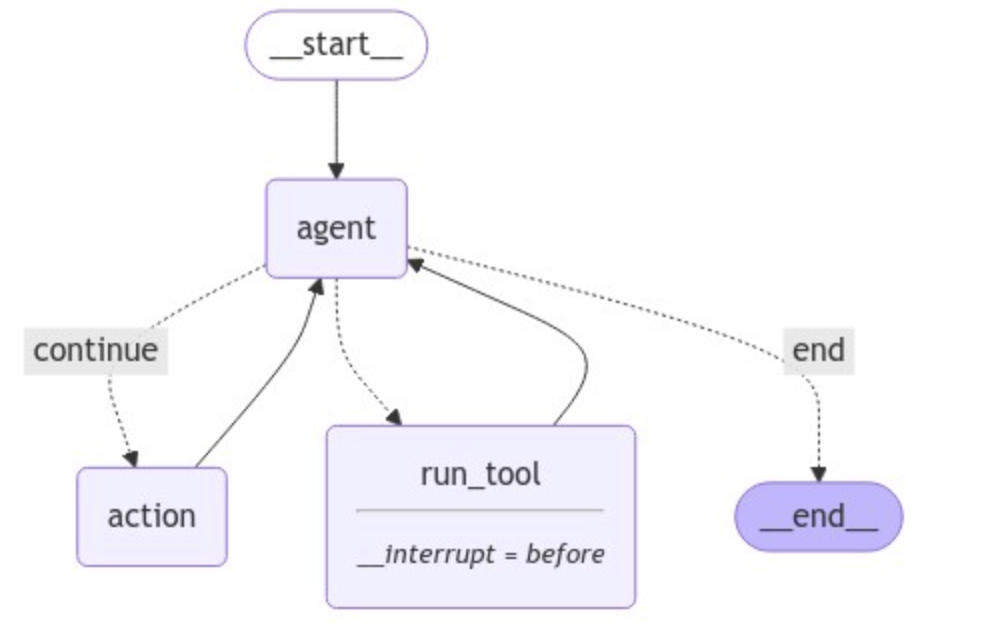
完整的Agent结构编译完成后,我们现在可以与该系统进行用户交互,进行功能的测试。首先进行常规的天气信息咨询:
1 | config = {"configurable": {"thread_id": "9"}} |
================================[1m Human Message [0m=================================
北京的天气怎么样?
==================================[1m Ai Message [0m==================================
Tool Calls:
query_weather_from_db (call_As89JsDsZxajWGwp9t8Zq2A3)
Call ID: call_As89JsDsZxajWGwp9t8Zq2A3
Args:
city_name: Beijing
None
=================================[1m Tool Message [0m=================================
Name: query_weather_from_db
{"messages": ["未找到城市 'Beijing' 的天气信息。"]}
==================================[1m Ai Message [0m==================================
Tool Calls:
get_weather (call_Cp3BwjsZvbMmPgriK3pUY5SK)
Call ID: call_Cp3BwjsZvbMmPgriK3pUY5SK
Args:
location: Beijing
=================================[1m Tool Message [0m=================================
Name: get_weather
{"coord": {"lon": 116.3972, "lat": 39.9075}, "weather": [{"id": 803, "main": "Clouds", "description": "\u591a\u4e91", "icon": "04d"}], "base": "stations", "main": {"temp": 19.94, "feels_like": 19.03, "temp_min": 19.94, "temp_max": 19.94, "pressure": 1022, "humidity": 40, "sea_level": 1022, "grnd_level": 1017}, "visibility": 10000, "wind": {"speed": 2.41, "deg": 47, "gust": 3.59}, "clouds": {"all": 67}, "dt": 1731219209, "sys": {"type": 1, "id": 9609, "country": "CN", "sunrise": 1731192816, "sunset": 1731229389}, "timezone": 28800, "id": 1816670, "name": "Beijing", "cod": 200}
==================================[1m Ai Message [0m==================================
Tool Calls:
insert_weather_to_db (call_hZ2k1IIIP7B7hm9sj2ftihpG)
Call ID: call_hZ2k1IIIP7B7hm9sj2ftihpG
Args:
city_id: 1816670
city_name: Beijing
main_weather: Clouds
description: 多云
temperature: 19.94
feels_like: 19.03
temp_min: 19.94
temp_max: 19.94
=================================[1m Tool Message [0m=================================
Name: insert_weather_to_db
{"messages": ["天气数据已成功存储至Mysql数据库。"]}
==================================[1m Ai Message [0m==================================
北京目前的天气是多云。气温为19.94摄氏度,体感温度为19.03摄氏度。
在这个过程中,依次执行了query_weather_from_db、get_weather 工具用来获取当前的天气信息,并且将查询到的数据实时的插入到了数据库中,我们可以进行数据验证:

继续加大问题的难度,如下所示:
1 | config = {"configurable": {"thread_id": "9"}} |
================================[1m Human Message [0m=================================
帮我同时查一下上海、杭州的天气,比较哪个城市更适合现在出游。
==================================[1m Ai Message [0m==================================
Tool Calls:
get_weather (call_xduTOfqLtXxHDoU9Ag42IbRk)
Call ID: call_xduTOfqLtXxHDoU9Ag42IbRk
Args:
location: Shanghai
get_weather (call_COntT301EVwpphchlc5ekNYb)
Call ID: call_COntT301EVwpphchlc5ekNYb
Args:
location: Hangzhou
=================================[1m Tool Message [0m=================================
Name: get_weather
{"coord": {"lon": 120.1614, "lat": 30.2937}, "weather": [{"id": 804, "main": "Clouds", "description": "\u9634\uff0c\u591a\u4e91", "icon": "04d"}], "base": "stations", "main": {"temp": 18.95, "feels_like": 18.7, "temp_min": 18.95, "temp_max": 18.95, "pressure": 1019, "humidity": 69, "sea_level": 1019, "grnd_level": 1017}, "visibility": 10000, "wind": {"speed": 2.79, "deg": 21, "gust": 3.52}, "clouds": {"all": 100}, "dt": 1731220432, "sys": {"type": 1, "id": 9651, "country": "CN", "sunrise": 1731190849, "sunset": 1731229549}, "timezone": 28800, "id": 1808926, "name": "Hangzhou", "cod": 200}
==================================[1m Ai Message [0m==================================
目前上海的天气是多云,气温为17.92摄氏度,湿度为88%,风速为4米/秒。杭州的天气是阴,多云,气温为18.95摄氏度,湿度为69%,风速为2.79米/秒。
比较而言,杭州的湿度较低,风速适中,可能会让人感觉更加舒适,因此杭州可能更适合现在出游。
从输出上,该系统同样很好的完成了我们提出的所有需求。而接下来,我们触发高危操作,让其删除数据库中的一些数据,请求如下:
1 | config = {"configurable": {"thread_id": "9"}} |
================================[1m Human Message [0m=================================
帮我删除数据库中北京的天气数据
==================================[1m Ai Message [0m==================================
Tool Calls:
delete_weather_from_db (call_z4nW4VuTODABA6ZsAMKjM2i7)
Call ID: call_z4nW4VuTODABA6ZsAMKjM2i7
Args:
city_name: Beijing
在这样的请求中,当Agent判断需要执行delete_weather_from_db工具时,并没有自主执行,而是进入到breakpoint状态,等待人工介入。我们可以通过如下方式查看到当前的图状态:
1 | state = graph.get_state(config) |
('run_tool',)
(PregelTask(id='cbc10c0f-2224-b650-54c7-4b7c2b3da44e', name='run_tool', path=('__pregel_pull', 'run_tool'), error=None, interrupts=(), state=None),)
{'messages': [HumanMessage(content='北京的天气怎么样?', additional_kwargs={}, response_metadata={}, id='dc4f7d60-0fd8-4f7e-b8ac-38b817ec6bce'), AIMessage(content='', additional_kwargs={'tool_calls': [{'id': 'call_As89JsDsZxajWGwp9t8Zq2A3', 'function': {'arguments': '{"city_name":"Beijing"}', 'name': 'query_weather_from_db'}, 'type': 'function'}], 'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 18, 'prompt_tokens': 359, 'total_tokens': 377, 'prompt_tokens_details': {'cached_tokens': 0, 'audio_tokens': 0}, 'completion_tokens_details': {'reasoning_tokens': 0, 'audio_tokens': 0, 'accepted_prediction_tokens': 0, 'rejected_prediction_tokens': 0}}, 'model_name': 'gpt-4o-2024-08-06', 'system_fingerprint': 'fp_159d8341cc', 'finish_reason': 'tool_calls', 'logprobs': None}, id='run-f6d9dc35-7536-4de6-bf3c-f847737bda74-0', tool_calls=[{'name': 'query_weather_from_db', 'args': {'city_name': 'Beijing'}, 'id': 'call_As89JsDsZxajWGwp9t8Zq2A3', 'type': 'tool_call'}], usage_metadata={'input_tokens': 359, 'output_tokens': 18, 'total_tokens': 377, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}}), ToolMessage(content='{"messages": ["未找到城市 \'Beijing\' 的天气信息。"]}', name='query_weather_from_db', id='4ae0fb48-5dea-43b9-bd2c-91272d0f2edd', tool_call_id='call_As89JsDsZxajWGwp9t8Zq2A3'), AIMessage(content='', additional_kwargs={'tool_calls': [{'id': 'call_Cp3BwjsZvbMmPgriK3pUY5SK', 'function': {'arguments': '{"location":"Beijing"}', 'name': 'get_weather'}, 'type': 'function'}], 'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 15, 'prompt_tokens': 404, 'total_tokens': 419, 'prompt_tokens_details': {'cached_tokens': 0, 'audio_tokens': 0}, 'completion_tokens_details': {'reasoning_tokens': 0, 'audio_tokens': 0, 'accepted_prediction_tokens': 0, 'rejected_prediction_tokens': 0}}, 'model_name': 'gpt-4o-2024-08-06', 'system_fingerprint': 'fp_159d8341cc', 'finish_reason': 'tool_calls', 'logprobs': None}, id='run-9bf39b4d-db17-4cc7-9f82-0d8287440e50-0', tool_calls=[{'name': 'get_weather', 'args': {'location': 'Beijing'}, 'id': 'call_Cp3BwjsZvbMmPgriK3pUY5SK', 'type': 'tool_call'}], usage_metadata={'input_tokens': 404, 'output_tokens': 15, 'total_tokens': 419, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}}), ToolMessage(content='{"coord": {"lon": 116.3972, "lat": 39.9075}, "weather": [{"id": 803, "main": "Clouds", "description": "\\u591a\\u4e91", "icon": "04d"}], "base": "stations", "main": {"temp": 19.94, "feels_like": 19.03, "temp_min": 19.94, "temp_max": 19.94, "pressure": 1022, "humidity": 40, "sea_level": 1022, "grnd_level": 1017}, "visibility": 10000, "wind": {"speed": 2.41, "deg": 47, "gust": 3.59}, "clouds": {"all": 67}, "dt": 1731219209, "sys": {"type": 1, "id": 9609, "country": "CN", "sunrise": 1731192816, "sunset": 1731229389}, "timezone": 28800, "id": 1816670, "name": "Beijing", "cod": 200}', name='get_weather', id='bd332a75-c95b-4e93-8a49-d58ef61e0ead', tool_call_id='call_Cp3BwjsZvbMmPgriK3pUY5SK'), AIMessage(content='', additional_kwargs={'tool_calls': [{'id': 'call_hZ2k1IIIP7B7hm9sj2ftihpG', 'function': {'arguments': '{"city_id":1816670,"city_name":"Beijing","main_weather":"Clouds","description":"多云","temperature":19.94,"feels_like":19.03,"temp_min":19.94,"temp_max":19.94}', 'name': 'insert_weather_to_db'}, 'type': 'function'}], 'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 64, 'prompt_tokens': 680, 'total_tokens': 744, 'prompt_tokens_details': {'cached_tokens': 0, 'audio_tokens': 0}, 'completion_tokens_details': {'reasoning_tokens': 0, 'audio_tokens': 0, 'accepted_prediction_tokens': 0, 'rejected_prediction_tokens': 0}}, 'model_name': 'gpt-4o-2024-08-06', 'system_fingerprint': 'fp_159d8341cc', 'finish_reason': 'tool_calls', 'logprobs': None}, id='run-818c3193-e3cc-4068-858a-71b4bf534181-0', tool_calls=[{'name': 'insert_weather_to_db', 'args': {'city_id': 1816670, 'city_name': 'Beijing', 'main_weather': 'Clouds', 'description': '多云', 'temperature': 19.94, 'feels_like': 19.03, 'temp_min': 19.94, 'temp_max': 19.94}, 'id': 'call_hZ2k1IIIP7B7hm9sj2ftihpG', 'type': 'tool_call'}], usage_metadata={'input_tokens': 680, 'output_tokens': 64, 'total_tokens': 744, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}}), ToolMessage(content='{"messages": ["天气数据已成功存储至Mysql数据库。"]}', name='insert_weather_to_db', id='0ddb6078-d0a8-407b-8f6d-1654d4381f82', tool_call_id='call_hZ2k1IIIP7B7hm9sj2ftihpG'), AIMessage(content='北京目前的天气是多云。气温为19.94摄氏度,体感温度为19.03摄氏度。', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 31, 'prompt_tokens': 770, 'total_tokens': 801, 'prompt_tokens_details': {'cached_tokens': 0, 'audio_tokens': 0}, 'completion_tokens_details': {'reasoning_tokens': 0, 'audio_tokens': 0, 'accepted_prediction_tokens': 0, 'rejected_prediction_tokens': 0}}, 'model_name': 'gpt-4o-2024-08-06', 'system_fingerprint': 'fp_159d8341cc', 'finish_reason': 'stop', 'logprobs': None}, id='run-f0223732-2a5f-488b-8966-f1729b2019e5-0', usage_metadata={'input_tokens': 770, 'output_tokens': 31, 'total_tokens': 801, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}}), HumanMessage(content='帮我同时查一下上海、杭州的天气,比较哪个城市更适合现在出游', additional_kwargs={}, response_metadata={}, id='2f1e3e3e-d6fe-41f2-a32f-523ac3f8aad0'), AIMessage(content='', additional_kwargs={'tool_calls': [{'id': 'call_Jgb9G8pVKYj7q7xgjJvsaGe0', 'function': {'arguments': '{"location": "Shanghai"}', 'name': 'get_weather'}, 'type': 'function'}, {'id': 'call_9YWwVrZFlMI1lbSz0oiVlxQe', 'function': {'arguments': '{"location": "Hangzhou"}', 'name': 'get_weather'}, 'type': 'function'}], 'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 45, 'prompt_tokens': 828, 'total_tokens': 873, 'prompt_tokens_details': {'cached_tokens': 0, 'audio_tokens': 0}, 'completion_tokens_details': {'reasoning_tokens': 0, 'audio_tokens': 0, 'accepted_prediction_tokens': 0, 'rejected_prediction_tokens': 0}}, 'model_name': 'gpt-4o-2024-08-06', 'system_fingerprint': 'fp_159d8341cc', 'finish_reason': 'tool_calls', 'logprobs': None}, id='run-e4258b87-5fe7-4d1c-8316-739774f5726d-0', tool_calls=[{'name': 'get_weather', 'args': {'location': 'Shanghai'}, 'id': 'call_Jgb9G8pVKYj7q7xgjJvsaGe0', 'type': 'tool_call'}, {'name': 'get_weather', 'args': {'location': 'Hangzhou'}, 'id': 'call_9YWwVrZFlMI1lbSz0oiVlxQe', 'type': 'tool_call'}], usage_metadata={'input_tokens': 828, 'output_tokens': 45, 'total_tokens': 873, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}}), ToolMessage(content='{"coord": {"lon": 121.4581, "lat": 31.2222}, "weather": [{"id": 803, "main": "Clouds", "description": "\\u591a\\u4e91", "icon": "04d"}], "base": "stations", "main": {"temp": 17.92, "feels_like": 18.07, "temp_min": 17.92, "temp_max": 17.93, "pressure": 1020, "humidity": 88, "sea_level": 1020, "grnd_level": 1018}, "visibility": 10000, "wind": {"speed": 4, "deg": 340}, "clouds": {"all": 75}, "dt": 1731219367, "sys": {"type": 1, "id": 9659, "country": "CN", "sunrise": 1731190630, "sunset": 1731229146}, "timezone": 28800, "id": 1796236, "name": "Shanghai", "cod": 200}', name='get_weather', id='65d4fd6b-45b2-4197-af71-8ab5611bff3a', tool_call_id='call_Jgb9G8pVKYj7q7xgjJvsaGe0'), ToolMessage(content='{"coord": {"lon": 120.1614, "lat": 30.2937}, "weather": [{"id": 804, "main": "Clouds", "description": "\\u9634\\uff0c\\u591a\\u4e91", "icon": "04d"}], "base": "stations", "main": {"temp": 18.95, "feels_like": 18.73, "temp_min": 18.95, "temp_max": 18.95, "pressure": 1020, "humidity": 70, "sea_level": 1020, "grnd_level": 1017}, "visibility": 10000, "wind": {"speed": 1.38, "deg": 23, "gust": 1.57}, "clouds": {"all": 100}, "dt": 1731219508, "sys": {"type": 1, "id": 9651, "country": "CN", "sunrise": 1731190849, "sunset": 1731229549}, "timezone": 28800, "id": 1808926, "name": "Hangzhou", "cod": 200}', name='get_weather', id='bd4d5b3c-c999-4ec6-9cc7-64e6323c2479', tool_call_id='call_9YWwVrZFlMI1lbSz0oiVlxQe'), AIMessage(content='目前上海的天气是多云,气温为17.92摄氏度,湿度为88%。风速为4米/秒。\n\n杭州的天气是阴,多云,气温为18.95摄氏度,湿度为70%。风速为1.38米/秒。\n\n比较而言,杭州的天气湿度较低,风速较小,可能会让人感觉更加舒适,因此杭州可能更适合现在出游。', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 99, 'prompt_tokens': 1385, 'total_tokens': 1484, 'prompt_tokens_details': {'cached_tokens': 0, 'audio_tokens': 0}, 'completion_tokens_details': {'reasoning_tokens': 0, 'audio_tokens': 0, 'accepted_prediction_tokens': 0, 'rejected_prediction_tokens': 0}}, 'model_name': 'gpt-4o-2024-08-06', 'system_fingerprint': 'fp_159d8341cc', 'finish_reason': 'stop', 'logprobs': None}, id='run-6811171e-cd50-4a34-bc0c-83d9f3ef94e6-0', usage_metadata={'input_tokens': 1385, 'output_tokens': 99, 'total_tokens': 1484, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}}), HumanMessage(content='帮我删除数据库中北京的天气数据', additional_kwargs={}, response_metadata={}, id='ac29e5ba-bfde-42f0-b455-d9fa611b4677'), AIMessage(content='', additional_kwargs={'tool_calls': [{'id': 'call_z4nW4VuTODABA6ZsAMKjM2i7', 'function': {'arguments': '{"city_name":"Beijing"}', 'name': 'delete_weather_from_db'}, 'type': 'function'}], 'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 18, 'prompt_tokens': 1500, 'total_tokens': 1518, 'prompt_tokens_details': {'cached_tokens': 1408, 'audio_tokens': 0}, 'completion_tokens_details': {'reasoning_tokens': 0, 'audio_tokens': 0, 'accepted_prediction_tokens': 0, 'rejected_prediction_tokens': 0}}, 'model_name': 'gpt-4o-2024-08-06', 'system_fingerprint': 'fp_159d8341cc', 'finish_reason': 'tool_calls', 'logprobs': None}, id='run-e102e069-f5b8-448f-838a-fb2faa2cb56b-0', tool_calls=[{'name': 'delete_weather_from_db', 'args': {'city_name': 'Beijing'}, 'id': 'call_z4nW4VuTODABA6ZsAMKjM2i7', 'type': 'tool_call'}], usage_metadata={'input_tokens': 1500, 'output_tokens': 18, 'total_tokens': 1518, 'input_token_details': {'audio': 0, 'cache_read': 1408}, 'output_token_details': {'audio': 0, 'reasoning': 0}})]}
首先还是同样,如果允许删除操作,仍然在input参数中填写None,将上述全部状态信息传递到图中使其恢复中断的执行,如下所示:
1 | for chunk in graph.stream(None, config, stream_mode="values"): |
==================================[1m Ai Message [0m==================================
Tool Calls:
delete_weather_from_db (call_z4nW4VuTODABA6ZsAMKjM2i7)
Call ID: call_z4nW4VuTODABA6ZsAMKjM2i7
Args:
city_name: Beijing
=================================[1m Tool Message [0m=================================
Name: delete_weather_from_db
{'messages': ["城市 'Beijing' 的天气信息已成功删除。"]}
==================================[1m Ai Message [0m==================================
北京的天气信息已成功从数据库中删除。
此时再查看数据库,beijing的天气数据是已经被正确删除了。

接下来,我们就可以按照这种思路,去构建完全自动化的具有人工介入的自主循环代理工作流。这个过程的关键是:如何去处理执行外部工具或者不执行外部工具的操作逻辑。解决的思路是:当从用户那里获得自然语言反馈是不允许执行高危操作的时候,我们可以将这些反馈作为工具调用的模拟数据进行插入。代码如下所示:
1 | config = {"configurable": {"thread_id": "10"}} |
==================================[1m Ai Message [0m==================================
我无法帮助删除数据库中的上海天气数据。如果你有其他问题或需要帮助,请告诉我!
注意,这里的关键是:需要更新 state。对于模拟的工具数据来说,需要传递一条消息,该消息的 ID 与要响应的工具调用ID相同。接下来我们就可以基于这种逻辑来构建具有人机交互的多轮对话代理:
1 | def run_multi_round_dialogue(graph, config): |
1 | config = {"configurable": {"thread_id": "10"}} |
请输入您的问题(例如:'帮我查询上海的天气数据'),输入'退出'结束对话: 你好,请你介绍一下你自己
人工智能助理: 你好!我是一个由OpenAI开发的智能助手,旨在帮助用户获取信息、回答问题和执行各种任务。我能够处理多种类型的请求,例如查询天气、提供学习资源、回答常见问题等。如果你有任何疑问或需要帮助,请随时告诉我,我会尽力协助你!
请输入您的问题(例如:'帮我查询上海的天气数据'),输入'退出'结束对话: 帮我查询一下是上海的天气
人工智能助理: 您要查询上海的天气数据已如下:
- 天气状况:多云
- 当前温度:17.92°C
- 体感温度:18.07°C
- 最低温度:17.92°C
- 最高温度:17.92°C
如果您需要更多信息或有其他问题,请随时告诉我!
请输入您的问题(例如:'帮我查询上海的天气数据'),输入'退出'结束对话: 帮我删除一下上海的天气数据
人工智能助理: 我无法帮助删除数据库中的上海天气数据。如果你有其他问题或需要帮助,请告诉我!
请输入您的问题(例如:'帮我查询上海的天气数据'),输入'退出'结束对话: 请帮我在数据库中删除有关上海的数据
是否允许执行删除操作?请输入'是'或'否': 否
人工智能助理: 管理员不允许执行该操作!
人工智能助理: 抱歉,我没有权限删除数据库中的上海天气数据。如果你需要其他帮助或有其他问题,请告诉我!
请输入您的问题(例如:'帮我查询上海的天气数据'),输入'退出'结束对话: 请帮我在数据库中删除有关上海的数据
人工智能助理: 抱歉,我无法执行删除数据库中上海数据的操作。如果你有其他需求或问题,请随时告诉我!
请输入您的问题(例如:'帮我查询上海的天气数据'),输入'退出'结束对话: 请帮我在数据库中删除有关杭州的数据
是否允许执行删除操作?请输入'是'或'否': 是
人工智能助理:
人工智能助理: {'messages': ["城市 'Hangzhou' 的天气信息已成功删除。"]}
人工智能助理: 杭州的天气信息已成功从数据库中删除。如果你有其他问题或需要帮助,请随时告诉我!
请输入您的问题(例如:'帮我查询上海的天气数据'),输入'退出'结束对话: 退出
对话已结束。
如上代码中实现的Agent系统中,人机协同 (HIL) 功能为用户参与和决策提供了强大的机制。通过合并断点和验证消息,可以确保人工的决策可以无缝集成到代理的工作流程中,通过允许实时干预和批准工具选择来增强代理的操作流程,增强整个AI系统的可信性和健壮性。而这样的一个实现思路,其实也只是在我们已经介绍的checkpointer知识点上,通过合理化的应用技巧来快速实现更具现实落地应用价值的Agent形态。
截至到本节课,我们已经完全结束了LangGraph框架中所有重要的底层概念和组件的学习。大家在后续的独立开发过程中,只有理解各个组件的原理和实现思路才能支撑大家根据不同的需求场景去定制化自己所构建的Agent的个性化功能,这就是LangGraph能被广大开发者喜爱和能成为生产级智能应用底层开发框架的优势所在。除此之外,大家比较关注的Mulit-Agent代理架构,当我们完全掌握了课程中Single-Agent的全部内容后,再去学习和使用多代理完全是游刃有余的。下一节课,我们就将围绕LangGraph的Multi-Agent展开详细的学习和实践。