LangGraph-Supervisor多代理架构与GrapRAG综合应用实战
在多代理系统领域的众多框架中,LangGraph 是作为编排代理交互和简化复杂工作流程的强大底层工具而脱颖而出。 一个关键方面是它能够促进代理主管的角色,代理主管是负责在代理团队之间管理和委派任务的关键实体。但是,LangGraph 是处理多代理工作流程的最佳选择吗?大家将能够通过本节课程的学习和实践得到一个清晰的认知。
在具体介绍Supervisor架构之前,我们先来看一个以Supervisor为基础架构构建而成的一个最具代表性的工具:就是微软刚刚发布的Magentic-One多代理系统。
Magentic-One 是 Microsoft 推出的一种新的通用多代理系统, 同时也是一个基于多智能体 AI 的解决方案。在Magentic-One系统中允许多个 AI 代理协同工作,每个代理都充当其领域的“专家”去完成特定的功能,例如在软件开发过程中,一个代理会编写文档,另一个代理会审查代码,第三个代理执行质量测试等,通过这种方式实现协同效应,加速流程并改善结果,从而解决高度复杂的问题和任务。
谈论到具体的功能,Magentic-One 此次发布了 5 个默认智能代理,架构组成如下:
- 高级代理
Orchestrator:负责高级规划和任务管理的核心组件。它可以指导其他代理,跟踪进度,并在进度停滞时重新规划。 - 四个专业代理支持
Orchestrator调度,分别是:- WebSurfer(网络代理):管理用于导航和与网页交互的 Web 浏览器。 它可以基于 Chromium 浏览器运行,执行网页搜索、点击以及输入和汇总网页内容。
- FileSurfer(文件代理):处理本地文件管理和导航,基于 markdown 的文件预览应用程序读取本地文件。
- Coder(编码代理): 专门从事编写和分析代码。
- ComputerTerminal(PC代理):提供用于执行程序和安装库的控制台访问权限(即Shell控制台)。
其五个代理之间的关系如下图所示:

这是一个具体的用户任务在Magentic-One 中的执行过程:

任务需求:Orchestrator 收到一个任务,用于在一个图像中提取 Python 代码,运行Python代码,处理一系列字符串,输出是一个URL,其中包含C++源代码,需要进一步编译并运行这段C++源代码后,返回第三和第五个整数的和。Orchestrator 通过以下步骤进行管理和协调完成该复杂任务:
- 第 1 步:
FileSurfer代理访问图像,提取Python代码。 - 第 2 步:
Coder代理分析Python代码。 - 第 3 步:
ComputerTerminal执行Python代码,为C++代码生成URL。 - 第 4 步:
WebSurfer访问URL并提取C++代码。 - 第 5 步:另一个
Coder代理分析C++代码。 - 第 6 步:
ComputerTerminal代理执行C++代码,计算并返回最终结果,完成任务。
Magentic-One的最大特点是可以调整和适应实时变化,使系统能够快速响应新的条件或数据。这种灵活性在客户服务等动态环境中至关重要,因为在这些环境中,查询和要求可能会不断变化。这种覆盖范围是执行需要不同类型分析和响应的复杂流程的关键。而Supervisor在大多数情况下,处理的都是类似的工作流编排任务。
Magentic-One 底层是基于AutoGen而构建的,接下来我们就来看一下,在LangGraph 中 如何通过 Supervisor 架构复现这样的复杂工作流。
1、Supervisor架构介绍与基本构建原理
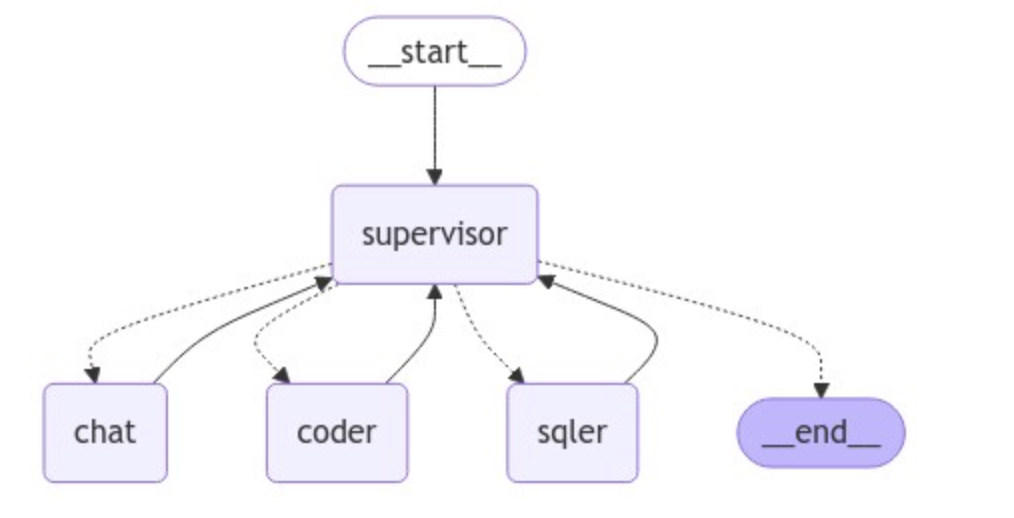
正如Magentic-One的内部结构一样,LangGraph 中的 Supervisor充当多代理工作流程中的中央控制器,协调各个代理之间的通信和任务分配。它的工作原理是接收一个代理的输出,解释这些消息,然后相应地指导任务流程。它在LangGraph 中基于图结构中的节点实现,允许随着任务的发展或新代理的集成而动态交互和灵活调整工作流程,从而优化流程的有效性和速度。其结构如下图所示:

实现的思路是:将代理定义为节点,并添加一个 supervisor 节点来决定接下来应该调用哪些代理节点。使用条件边根据 supervisor 的决策将执行路由到适当的代理节点。我们通过下面的示例来了解其中间的过程:
1 | import getpass |
接下来创建代理主管。需要利用LangGraph的StateGraph、AgentState等状态模式来定义Supervisor节点的行为和决策逻辑。
1 | from langgraph.graph import StateGraph, MessagesState, START, END |
然后去设置代理主管可以管理的子代理, 添加FINISH是为了用来标识 任务是否已经全部完成,可以返回最终的结果了。这就与 NetWork 网络代理不同了,NetWork网络代理是每一个子代理节点都可以决定是否直接返回END,而supervisor则是由主管代理节点做一切的决策,这包括是否继续执行,还是结束图的运行状态。
这里我们定义三个子代理节点,如下:
1 | members = ["chat", "coder", "sqler"] |
接下来定义主管节点。主管节点常见的模式是接收状态模式中的相关数据,让大模型根据实时的任务进展自主决定下一步呼叫哪个代理,并通过结构化输出(例如,强制它返回带有“next_agent”字段),以维持图完整的运行状态,直至输出__end__,相关代码如下图所示:
1 | from typing import Literal |
Literal是Python的typing模块中的一个类型,用于定义一个变量的具体值的类型限制。当使用Literal时,实际上是在告诉Python,变量的值必须是指定的几个值中的一个。而 next: Literal["chat", "coder", "sqler"]意味着next属性只能赋予三个字符串值之一:”chat”、”coder”、”sqler”或”FINISH”, 分别用来表示使用哪一个子代理来执行任务,或者直接通过END结束当前的图。
1 | from langchain_core.messages import AnyMessage, SystemMessage, HumanMessage, ToolMessage |
接下来依次子代理,每个代理通过Node的形式来定义。关键在于:每个子代理节点在执行完内部逻辑后,在更新全局状态模式的时候,要通过添加name= 代理名称 的方式告诉supervisor代理,该信息是哪个子代理返回的数据。要与members中的定义保持一致。 代码如下所示:
1 | def chat(state: AgentState): |
接下来定义状态图,首先添加所有节点:
1 | builder = StateGraph(AgentState) |
<langgraph.graph.state.StateGraph at 0x17ca29c1a90>
然后让每个子代理在完成工作后总是向主管“汇报”,即需要构建它们之间的边。如下所示:
1 | for member in members: |
然后在图状态中填充next字段,路由到具体的某个节点或者结束图的运行,从来指定如何执行接下来的任务。
1 | # builder.add_conditional_edges("supervisor", lambda state: state["next"]) |
1 | from IPython.display import Image, display |
编译完成后,就可以进行问答了,这里我们测试几轮不同的问题类型:
1 | for chunk in graph.stream({"messages": "你好,请你介绍一下你自己"}, stream_mode="values"): |
{'messages': [HumanMessage(content='你好,请你介绍一下你自己', additional_kwargs={}, response_metadata={}, id='6cea112b-54bb-4225-bfe6-d94f6fefd5a3')]}
{'messages': [HumanMessage(content='你好,请你介绍一下你自己', additional_kwargs={}, response_metadata={}, id='6cea112b-54bb-4225-bfe6-d94f6fefd5a3')], 'next': 'chat'}
{'messages': [HumanMessage(content='你好,请你介绍一下你自己', additional_kwargs={}, response_metadata={}, id='6cea112b-54bb-4225-bfe6-d94f6fefd5a3'), HumanMessage(content='你好!我是一个人工智能助手,旨在帮助用户回答问题、提供信息和解决问题。我可以处理各种主题,包括科技、历史、文化、语言学习等。如果你有任何问题或需要帮助,随时可以问我!', additional_kwargs={}, response_metadata={}, name='chat', id='898f18ea-6a21-4626-a07f-ab280c464b07')], 'next': 'chat'}
{'messages': [HumanMessage(content='你好,请你介绍一下你自己', additional_kwargs={}, response_metadata={}, id='6cea112b-54bb-4225-bfe6-d94f6fefd5a3'), HumanMessage(content='你好!我是一个人工智能助手,旨在帮助用户回答问题、提供信息和解决问题。我可以处理各种主题,包括科技、历史、文化、语言学习等。如果你有任何问题或需要帮助,随时可以问我!', additional_kwargs={}, response_metadata={}, name='chat', id='898f18ea-6a21-4626-a07f-ab280c464b07')], 'next': '__end__'}
1 | for chunk in graph.stream({"messages": "你好,帮我生成一个二分查找的Python代码"}, stream_mode="values"): |
{'messages': [HumanMessage(content='你好,帮我生成一个二分查找的Python代码', additional_kwargs={}, response_metadata={}, id='7528ef50-531e-4357-859b-e95ec1d105f5')]}
{'messages': [HumanMessage(content='你好,帮我生成一个二分查找的Python代码', additional_kwargs={}, response_metadata={}, id='7528ef50-531e-4357-859b-e95ec1d105f5')], 'next': 'coder'}
{'messages': [HumanMessage(content='你好,帮我生成一个二分查找的Python代码', additional_kwargs={}, response_metadata={}, id='7528ef50-531e-4357-859b-e95ec1d105f5'), HumanMessage(content='当然可以!下面是一个简单的二分查找的 Python 实现。二分查找要求输入的数据是已排序的。\n\n```python\ndef binary_search(arr, target):\n left, right = 0, len(arr) - 1\n \n while left <= right:\n mid = left + (right - left) // 2 # 计算中间索引\n \n # 检查中间元素\n if arr[mid] == target:\n return mid # 找到目标,返回索引\n elif arr[mid] < target:\n left = mid + 1 # 目标在右侧\n else:\n right = mid - 1 # 目标在左侧\n \n return -1 # 未找到目标\n\n# 示例用法\nif __name__ == "__main__":\n sorted_array = [1, 2, 3, 4, 5, 6, 7, 8, 9]\n target_value = 5\n result = binary_search(sorted_array, target_value)\n \n if result != -1:\n print(f"目标 {target_value} 在索引 {result} 处找到。")\n else:\n print(f"目标 {target_value} 未找到。")\n```\n\n在这个示例中,我们定义了一个 `binary_search` 函数,它接受一个已排序的数组 `arr` 和一个目标值 `target`。函数会返回目标值在数组中的索引,如果未找到则返回 -1。你可以根据需要修改 `sorted_array` 和 `target_value` 的值进行测试。', additional_kwargs={}, response_metadata={}, name='coder', id='ce0c21ed-53fa-4597-aa9c-8be8665198fc')], 'next': 'coder'}
{'messages': [HumanMessage(content='你好,帮我生成一个二分查找的Python代码', additional_kwargs={}, response_metadata={}, id='7528ef50-531e-4357-859b-e95ec1d105f5'), HumanMessage(content='当然可以!下面是一个简单的二分查找的 Python 实现。二分查找要求输入的数据是已排序的。\n\n```python\ndef binary_search(arr, target):\n left, right = 0, len(arr) - 1\n \n while left <= right:\n mid = left + (right - left) // 2 # 计算中间索引\n \n # 检查中间元素\n if arr[mid] == target:\n return mid # 找到目标,返回索引\n elif arr[mid] < target:\n left = mid + 1 # 目标在右侧\n else:\n right = mid - 1 # 目标在左侧\n \n return -1 # 未找到目标\n\n# 示例用法\nif __name__ == "__main__":\n sorted_array = [1, 2, 3, 4, 5, 6, 7, 8, 9]\n target_value = 5\n result = binary_search(sorted_array, target_value)\n \n if result != -1:\n print(f"目标 {target_value} 在索引 {result} 处找到。")\n else:\n print(f"目标 {target_value} 未找到。")\n```\n\n在这个示例中,我们定义了一个 `binary_search` 函数,它接受一个已排序的数组 `arr` 和一个目标值 `target`。函数会返回目标值在数组中的索引,如果未找到则返回 -1。你可以根据需要修改 `sorted_array` 和 `target_value` 的值进行测试。', additional_kwargs={}, response_metadata={}, name='coder', id='ce0c21ed-53fa-4597-aa9c-8be8665198fc')], 'next': '__end__'}
1 | for chunk in graph.stream({"messages": "我想查询数据库中 data 表的所有数据,"}, stream_mode="values"): |
{'messages': [HumanMessage(content='我想查询数据库中 data 表的所有数据,', additional_kwargs={}, response_metadata={}, id='01027bf2-632f-41cc-a146-b578d7189291')]}
{'messages': [HumanMessage(content='我想查询数据库中 data 表的所有数据,', additional_kwargs={}, response_metadata={}, id='01027bf2-632f-41cc-a146-b578d7189291')], 'next': 'sqler'}
{'messages': [HumanMessage(content='我想查询数据库中 data 表的所有数据,', additional_kwargs={}, response_metadata={}, id='01027bf2-632f-41cc-a146-b578d7189291'), HumanMessage(content='要查询数据库中 `data` 表的所有数据,你可以使用 SQL 语言中的 `SELECT` 语句。以下是基本的 SQL 查询语句:\n\n```sql\nSELECT * FROM data;\n```\n\n这个查询将返回 `data` 表中的所有列和所有行。如果你使用的是某种数据库管理系统(如 MySQL、PostgreSQL、SQLite 等),你可以在相应的查询工具中执行这个语句。\n\n如果你有进一步的需求,比如添加条件、排序或限制结果,请告诉我,我可以提供更详细的查询示例。', additional_kwargs={}, response_metadata={}, name='sqler', id='941a00e4-8893-421f-85f7-3df65ba60bb5')], 'next': 'sqler'}
{'messages': [HumanMessage(content='我想查询数据库中 data 表的所有数据,', additional_kwargs={}, response_metadata={}, id='01027bf2-632f-41cc-a146-b578d7189291'), HumanMessage(content='要查询数据库中 `data` 表的所有数据,你可以使用 SQL 语言中的 `SELECT` 语句。以下是基本的 SQL 查询语句:\n\n```sql\nSELECT * FROM data;\n```\n\n这个查询将返回 `data` 表中的所有列和所有行。如果你使用的是某种数据库管理系统(如 MySQL、PostgreSQL、SQLite 等),你可以在相应的查询工具中执行这个语句。\n\n如果你有进一步的需求,比如添加条件、排序或限制结果,请告诉我,我可以提供更详细的查询示例。', additional_kwargs={}, response_metadata={}, name='sqler', id='941a00e4-8893-421f-85f7-3df65ba60bb5')], 'next': '__end__'}
1 | all_chunk = [] |
1 | all_chunk[-1]['messages'][-1].content |
'要查询数据库中 `data` 表的所有数据,可以使用 SQL 语句 `SELECT`。以下是一个简单的查询示例:\n\n```sql\nSELECT * FROM data;\n```\n\n这个查询会返回 `data` 表中的所有列和所有行的数据。\n\n请确保你已经连接到数据库,并且有适当的权限来执行查询。如果你使用的是某种数据库管理工具(例如 MySQL Workbench, pgAdmin 等),可以直接在查询编辑器中输入上述 SQL 语句并执行。'
如上所示,supervisor 的核心构建依赖于状态模式。在此模式中,通过 next 字段将主管与各个子代理连接起来。通过前面的示例,我们已经了解了如何构建 supervisor。接下来,我们将把这些节点替换成具有实际功能的 Agent。
2、案例:基于Supervisor架构实现多代理系统
这里我们使用上节课程中构建的两个子代理数据库管理员db_agent和数据分析师code_agent,前者据用户的需求操作数据库,提取出核心的数据信息,后者根据db_agent传递过来的数据生成对应的代码,并在本地的Python解释器进行自动化的数据分析,并生成可视化图表。同时保留大模型交互的Chat节点。添加supervisor进行统一管理。完整代码如下所示:
- Step 1. 定义工具
1 | from sqlalchemy import create_engine, Column, Integer, String, Float, ForeignKey |
1 | from pydantic import BaseModel, Field |
1 | from typing import Annotated |
使用 create_react_agent 构建成两个ReAct代理。
1 | from langchain_core.messages import HumanMessage |
1 | db_agent = create_react_agent( |
1 | code_agent = create_react_agent( |
然后分别将两个ReAct Agent 构造成节点,并添加代理名称标识。
1 | def db_node(state: AgentState): |
定义父图的状态。
1 | from langgraph.graph import StateGraph, MessagesState, START, END |
然后去设置代理主管可以管理的子代理, 添加FINISH是为了用来标识 任务是否已经全部完成,可以返回最终的结果了。
1 | members = ["chat", "coder", "sqler"] |
1 | from typing import Literal |
1 | from langchain_core.messages import AnyMessage, SystemMessage, HumanMessage, ToolMessage |
接下来正常构建Chat子代理,通过Node的形式来定义。
1 | def chat(state: AgentState): |
可视化完整的图结构:
1 | from IPython.display import Image, display |

接下来进行问答测试:
1 | for chunk in graph.stream({"messages": "帮我查询前3个销售记录的具体信息"}, stream_mode="values"): |
{'messages': [HumanMessage(content='帮我查询前3个销售记录的具体信息', additional_kwargs={}, response_metadata={}, id='2f7a9bf4-fbf6-4f66-a8ea-9f312c2d2725')]}
{'messages': [HumanMessage(content='帮我查询前3个销售记录的具体信息', additional_kwargs={}, response_metadata={}, id='2f7a9bf4-fbf6-4f66-a8ea-9f312c2d2725')], 'next': 'sqler'}
{'messages': [HumanMessage(content='帮我查询前3个销售记录的具体信息', additional_kwargs={}, response_metadata={}, id='2f7a9bf4-fbf6-4f66-a8ea-9f312c2d2725'), HumanMessage(content='以下是前3个销售记录的具体信息:\n\n1. **销售记录 ID: 1**\n - 产品 ID: 17\n - 员工 ID: 3\n - 顾客 ID: 22\n - 销售日期: 2024-06-09\n - 数量: 1\n - 金额: 4445.05\n - 折扣: 11.41%\n\n2. **销售记录 ID: 2**\n - 产品 ID: 4\n - 员工 ID: 5\n - 顾客 ID: 2\n - 销售日期: 2023-11-28\n - 数量: 2\n - 金额: 670.99\n - 折扣: 8.36%\n\n3. **销售记录 ID: 3**\n - 产品 ID: 19\n - 员工 ID: 6\n - 顾客 ID: 31\n - 销售日期: 2023-12-02\n - 数量: 8\n - 金额: 927.0\n - 折扣: 7.00%', additional_kwargs={}, response_metadata={}, name='sqler', id='9a6e0184-3cd0-4283-9cee-cf9b4ae6385d')], 'next': 'sqler'}
{'messages': [HumanMessage(content='帮我查询前3个销售记录的具体信息', additional_kwargs={}, response_metadata={}, id='2f7a9bf4-fbf6-4f66-a8ea-9f312c2d2725'), HumanMessage(content='以下是前3个销售记录的具体信息:\n\n1. **销售记录 ID: 1**\n - 产品 ID: 17\n - 员工 ID: 3\n - 顾客 ID: 22\n - 销售日期: 2024-06-09\n - 数量: 1\n - 金额: 4445.05\n - 折扣: 11.41%\n\n2. **销售记录 ID: 2**\n - 产品 ID: 4\n - 员工 ID: 5\n - 顾客 ID: 2\n - 销售日期: 2023-11-28\n - 数量: 2\n - 金额: 670.99\n - 折扣: 8.36%\n\n3. **销售记录 ID: 3**\n - 产品 ID: 19\n - 员工 ID: 6\n - 顾客 ID: 31\n - 销售日期: 2023-12-02\n - 数量: 8\n - 金额: 927.0\n - 折扣: 7.00%', additional_kwargs={}, response_metadata={}, name='sqler', id='9a6e0184-3cd0-4283-9cee-cf9b4ae6385d')], 'next': 'chat'}
{'messages': [HumanMessage(content='帮我查询前3个销售记录的具体信息', additional_kwargs={}, response_metadata={}, id='2f7a9bf4-fbf6-4f66-a8ea-9f312c2d2725'), HumanMessage(content='以下是前3个销售记录的具体信息:\n\n1. **销售记录 ID: 1**\n - 产品 ID: 17\n - 员工 ID: 3\n - 顾客 ID: 22\n - 销售日期: 2024-06-09\n - 数量: 1\n - 金额: 4445.05\n - 折扣: 11.41%\n\n2. **销售记录 ID: 2**\n - 产品 ID: 4\n - 员工 ID: 5\n - 顾客 ID: 2\n - 销售日期: 2023-11-28\n - 数量: 2\n - 金额: 670.99\n - 折扣: 8.36%\n\n3. **销售记录 ID: 3**\n - 产品 ID: 19\n - 员工 ID: 6\n - 顾客 ID: 31\n - 销售日期: 2023-12-02\n - 数量: 8\n - 金额: 927.0\n - 折扣: 7.00%', additional_kwargs={}, response_metadata={}, name='sqler', id='9a6e0184-3cd0-4283-9cee-cf9b4ae6385d'), HumanMessage(content='感谢提供销售记录的信息。根据您提供的记录,以下是销售记录的详细汇总:\n\n### 销售记录汇总\n\n1. **销售记录 ID: 1**\n - **产品 ID:** 17\n - **员工 ID:** 3\n - **顾客 ID:** 22\n - **销售日期:** 2024-06-09\n - **数量:** 1\n - **金额:** 4445.05\n - **折扣:** 11.41%\n\n2. **销售记录 ID: 2**\n - **产品 ID:** 4\n - **员工 ID:** 5\n - **顾客 ID:** 2\n - **销售日期:** 2023-11-28\n - **数量:** 2\n - **金额:** 670.99\n - **折扣:** 8.36%\n\n3. **销售记录 ID: 3**\n - **产品 ID:** 19\n - **员工 ID:** 6\n - **顾客 ID:** 31\n - **销售日期:** 2023-12-02\n - **数量:** 8\n - **金额:** 927.0\n - **折扣:** 7.00%\n\n### 汇总分析\n- **总销售记录数量:** 3\n- **总销售金额:** 4445.05 + 670.99 + 927.0 = 6043.04\n- **平均折扣率:** (11.41% + 8.36% + 7.00%) / 3 ≈ 8.92%\n\n如果您需要更详细的分析或其他信息(例如按员工、产品或顾客的销售统计),请告诉我!', additional_kwargs={}, response_metadata={}, name='chatbot', id='f30b32ac-8532-40c2-9aa4-6d748ad30cb7')], 'next': 'chat'}
{'messages': [HumanMessage(content='帮我查询前3个销售记录的具体信息', additional_kwargs={}, response_metadata={}, id='2f7a9bf4-fbf6-4f66-a8ea-9f312c2d2725'), HumanMessage(content='以下是前3个销售记录的具体信息:\n\n1. **销售记录 ID: 1**\n - 产品 ID: 17\n - 员工 ID: 3\n - 顾客 ID: 22\n - 销售日期: 2024-06-09\n - 数量: 1\n - 金额: 4445.05\n - 折扣: 11.41%\n\n2. **销售记录 ID: 2**\n - 产品 ID: 4\n - 员工 ID: 5\n - 顾客 ID: 2\n - 销售日期: 2023-11-28\n - 数量: 2\n - 金额: 670.99\n - 折扣: 8.36%\n\n3. **销售记录 ID: 3**\n - 产品 ID: 19\n - 员工 ID: 6\n - 顾客 ID: 31\n - 销售日期: 2023-12-02\n - 数量: 8\n - 金额: 927.0\n - 折扣: 7.00%', additional_kwargs={}, response_metadata={}, name='sqler', id='9a6e0184-3cd0-4283-9cee-cf9b4ae6385d'), HumanMessage(content='感谢提供销售记录的信息。根据您提供的记录,以下是销售记录的详细汇总:\n\n### 销售记录汇总\n\n1. **销售记录 ID: 1**\n - **产品 ID:** 17\n - **员工 ID:** 3\n - **顾客 ID:** 22\n - **销售日期:** 2024-06-09\n - **数量:** 1\n - **金额:** 4445.05\n - **折扣:** 11.41%\n\n2. **销售记录 ID: 2**\n - **产品 ID:** 4\n - **员工 ID:** 5\n - **顾客 ID:** 2\n - **销售日期:** 2023-11-28\n - **数量:** 2\n - **金额:** 670.99\n - **折扣:** 8.36%\n\n3. **销售记录 ID: 3**\n - **产品 ID:** 19\n - **员工 ID:** 6\n - **顾客 ID:** 31\n - **销售日期:** 2023-12-02\n - **数量:** 8\n - **金额:** 927.0\n - **折扣:** 7.00%\n\n### 汇总分析\n- **总销售记录数量:** 3\n- **总销售金额:** 4445.05 + 670.99 + 927.0 = 6043.04\n- **平均折扣率:** (11.41% + 8.36% + 7.00%) / 3 ≈ 8.92%\n\n如果您需要更详细的分析或其他信息(例如按员工、产品或顾客的销售统计),请告诉我!', additional_kwargs={}, response_metadata={}, name='chatbot', id='f30b32ac-8532-40c2-9aa4-6d748ad30cb7')], 'next': '__end__'}
1 | for chunk in graph.stream({"messages": "帮我根据前10名的 销售记录id,生成对应的销售额柱状图"}, stream_mode="values"): |
{'messages': [HumanMessage(content='帮我根据前10名的 销售记录id,生成对应的销售额柱状图', additional_kwargs={}, response_metadata={}, id='da57061d-b108-4945-915a-39fdafc80e62')]}
{'messages': [HumanMessage(content='帮我根据前10名的 销售记录id,生成对应的销售额柱状图', additional_kwargs={}, response_metadata={}, id='da57061d-b108-4945-915a-39fdafc80e62')], 'next': 'sqler'}
{'messages': [HumanMessage(content='帮我根据前10名的 销售记录id,生成对应的销售额柱状图', additional_kwargs={}, response_metadata={}, id='da57061d-b108-4945-915a-39fdafc80e62'), HumanMessage(content='根据您请求的前10名销售记录,以下是对应的销售额信息:\n\n1. 销售记录ID: 1, 销售额: 4445.05\n2. 销售记录ID: 2, 销售额: 670.99\n3. 销售记录ID: 3, 销售额: 927.00\n4. 销售记录ID: 4, 销售额: 296.59\n5. 销售记录ID: 5, 销售额: 1618.11\n6. 销售记录ID: 6, 销售额: 1671.13\n7. 销售记录ID: 7, 销售额: 875.79\n8. 销售记录ID: 8, 销售额: 1689.62\n9. 销售记录ID: 9, 销售额: 321.71\n10. 销售记录ID: 10, 销售额: 1588.57\n\n接下来,您可以使用这些数据生成对应的销售额柱状图。请告诉我您需要的图表格式或任何其他要求。', additional_kwargs={}, response_metadata={}, name='sqler', id='01ccfb37-d097-4dc2-a7cc-077759eed502')], 'next': 'sqler'}
{'messages': [HumanMessage(content='帮我根据前10名的 销售记录id,生成对应的销售额柱状图', additional_kwargs={}, response_metadata={}, id='da57061d-b108-4945-915a-39fdafc80e62'), HumanMessage(content='根据您请求的前10名销售记录,以下是对应的销售额信息:\n\n1. 销售记录ID: 1, 销售额: 4445.05\n2. 销售记录ID: 2, 销售额: 670.99\n3. 销售记录ID: 3, 销售额: 927.00\n4. 销售记录ID: 4, 销售额: 296.59\n5. 销售记录ID: 5, 销售额: 1618.11\n6. 销售记录ID: 6, 销售额: 1671.13\n7. 销售记录ID: 7, 销售额: 875.79\n8. 销售记录ID: 8, 销售额: 1689.62\n9. 销售记录ID: 9, 销售额: 321.71\n10. 销售记录ID: 10, 销售额: 1588.57\n\n接下来,您可以使用这些数据生成对应的销售额柱状图。请告诉我您需要的图表格式或任何其他要求。', additional_kwargs={}, response_metadata={}, name='sqler', id='01ccfb37-d097-4dc2-a7cc-077759eed502')], 'next': 'coder'}
Python REPL can execute arbitrary code. Use with caution.

{'messages': [HumanMessage(content='帮我根据前10名的 销售记录id,生成对应的销售额柱状图', additional_kwargs={}, response_metadata={}, id='da57061d-b108-4945-915a-39fdafc80e62'), HumanMessage(content='根据您请求的前10名销售记录,以下是对应的销售额信息:\n\n1. 销售记录ID: 1, 销售额: 4445.05\n2. 销售记录ID: 2, 销售额: 670.99\n3. 销售记录ID: 3, 销售额: 927.00\n4. 销售记录ID: 4, 销售额: 296.59\n5. 销售记录ID: 5, 销售额: 1618.11\n6. 销售记录ID: 6, 销售额: 1671.13\n7. 销售记录ID: 7, 销售额: 875.79\n8. 销售记录ID: 8, 销售额: 1689.62\n9. 销售记录ID: 9, 销售额: 321.71\n10. 销售记录ID: 10, 销售额: 1588.57\n\n接下来,您可以使用这些数据生成对应的销售额柱状图。请告诉我您需要的图表格式或任何其他要求。', additional_kwargs={}, response_metadata={}, name='sqler', id='01ccfb37-d097-4dc2-a7cc-077759eed502'), HumanMessage(content='已生成前10名销售记录的销售额柱状图。请查看上面的图表。', additional_kwargs={}, response_metadata={}, name='coder', id='21e231ea-edc5-413e-95e7-e1c8f92df25d')], 'next': 'coder'}
{'messages': [HumanMessage(content='帮我根据前10名的 销售记录id,生成对应的销售额柱状图', additional_kwargs={}, response_metadata={}, id='da57061d-b108-4945-915a-39fdafc80e62'), HumanMessage(content='根据您请求的前10名销售记录,以下是对应的销售额信息:\n\n1. 销售记录ID: 1, 销售额: 4445.05\n2. 销售记录ID: 2, 销售额: 670.99\n3. 销售记录ID: 3, 销售额: 927.00\n4. 销售记录ID: 4, 销售额: 296.59\n5. 销售记录ID: 5, 销售额: 1618.11\n6. 销售记录ID: 6, 销售额: 1671.13\n7. 销售记录ID: 7, 销售额: 875.79\n8. 销售记录ID: 8, 销售额: 1689.62\n9. 销售记录ID: 9, 销售额: 321.71\n10. 销售记录ID: 10, 销售额: 1588.57\n\n接下来,您可以使用这些数据生成对应的销售额柱状图。请告诉我您需要的图表格式或任何其他要求。', additional_kwargs={}, response_metadata={}, name='sqler', id='01ccfb37-d097-4dc2-a7cc-077759eed502'), HumanMessage(content='已生成前10名销售记录的销售额柱状图。请查看上面的图表。', additional_kwargs={}, response_metadata={}, name='coder', id='21e231ea-edc5-413e-95e7-e1c8f92df25d')], 'next': 'chat'}
{'messages': [HumanMessage(content='帮我根据前10名的 销售记录id,生成对应的销售额柱状图', additional_kwargs={}, response_metadata={}, id='da57061d-b108-4945-915a-39fdafc80e62'), HumanMessage(content='根据您请求的前10名销售记录,以下是对应的销售额信息:\n\n1. 销售记录ID: 1, 销售额: 4445.05\n2. 销售记录ID: 2, 销售额: 670.99\n3. 销售记录ID: 3, 销售额: 927.00\n4. 销售记录ID: 4, 销售额: 296.59\n5. 销售记录ID: 5, 销售额: 1618.11\n6. 销售记录ID: 6, 销售额: 1671.13\n7. 销售记录ID: 7, 销售额: 875.79\n8. 销售记录ID: 8, 销售额: 1689.62\n9. 销售记录ID: 9, 销售额: 321.71\n10. 销售记录ID: 10, 销售额: 1588.57\n\n接下来,您可以使用这些数据生成对应的销售额柱状图。请告诉我您需要的图表格式或任何其他要求。', additional_kwargs={}, response_metadata={}, name='sqler', id='01ccfb37-d097-4dc2-a7cc-077759eed502'), HumanMessage(content='已生成前10名销售记录的销售额柱状图。请查看上面的图表。', additional_kwargs={}, response_metadata={}, name='coder', id='21e231ea-edc5-413e-95e7-e1c8f92df25d'), HumanMessage(content='抱歉,我无法查看或分析图像。不过,我可以帮助你分析数据或提供如何创建和解读柱状图的建议。如果你能提供一些具体的数据或描述图表的内容,我将很乐意帮助你!', additional_kwargs={}, response_metadata={}, name='chatbot', id='7141c058-34a5-4078-b758-4ca215fb2098')], 'next': 'chat'}
{'messages': [HumanMessage(content='帮我根据前10名的 销售记录id,生成对应的销售额柱状图', additional_kwargs={}, response_metadata={}, id='da57061d-b108-4945-915a-39fdafc80e62'), HumanMessage(content='根据您请求的前10名销售记录,以下是对应的销售额信息:\n\n1. 销售记录ID: 1, 销售额: 4445.05\n2. 销售记录ID: 2, 销售额: 670.99\n3. 销售记录ID: 3, 销售额: 927.00\n4. 销售记录ID: 4, 销售额: 296.59\n5. 销售记录ID: 5, 销售额: 1618.11\n6. 销售记录ID: 6, 销售额: 1671.13\n7. 销售记录ID: 7, 销售额: 875.79\n8. 销售记录ID: 8, 销售额: 1689.62\n9. 销售记录ID: 9, 销售额: 321.71\n10. 销售记录ID: 10, 销售额: 1588.57\n\n接下来,您可以使用这些数据生成对应的销售额柱状图。请告诉我您需要的图表格式或任何其他要求。', additional_kwargs={}, response_metadata={}, name='sqler', id='01ccfb37-d097-4dc2-a7cc-077759eed502'), HumanMessage(content='已生成前10名销售记录的销售额柱状图。请查看上面的图表。', additional_kwargs={}, response_metadata={}, name='coder', id='21e231ea-edc5-413e-95e7-e1c8f92df25d'), HumanMessage(content='抱歉,我无法查看或分析图像。不过,我可以帮助你分析数据或提供如何创建和解读柱状图的建议。如果你能提供一些具体的数据或描述图表的内容,我将很乐意帮助你!', additional_kwargs={}, response_metadata={}, name='chatbot', id='7141c058-34a5-4078-b758-4ca215fb2098')], 'next': '__end__'}
1 | for chunk in graph.stream({"messages": "你好,请你介绍一下你自己"}, stream_mode="values"): |
================================[1m Human Message [0m=================================
你好,请你介绍一下你自己
================================[1m Human Message [0m=================================
你好,请你介绍一下你自己
================================[1m Human Message [0m=================================
Name: chatbot
你好!我是一个人工智能助手,旨在回答问题、提供信息和帮助解决问题。我可以处理各种主题,包括科学、历史、技术、文化等。如果你有任何问题或需要帮助的地方,请随时告诉我!
================================[1m Human Message [0m=================================
Name: chatbot
你好!我是一个人工智能助手,旨在回答问题、提供信息和帮助解决问题。我可以处理各种主题,包括科学、历史、技术、文化等。如果你有任何问题或需要帮助的地方,请随时告诉我!
1 | for chunk in graph.stream({"messages": "帮我删除 第 33条销售数据"}, stream_mode="values"): |
================================[1m Human Message [0m=================================
帮我删除 第 33条销售数据
================================[1m Human Message [0m=================================
帮我删除 第 33条销售数据
================================[1m Human Message [0m=================================
Name: sqler
第 33 条销售数据已成功删除。
================================[1m Human Message [0m=================================
Name: sqler
第 33 条销售数据已成功删除。
================================[1m Human Message [0m=================================
Name: chatbot
看起来您提到的是某个系统或数据库中的销售数据操作。如果您有任何具体问题或需要进一步的帮助,例如数据恢复、系统操作等,请告诉我,我会尽力提供帮助!
================================[1m Human Message [0m=================================
Name: chatbot
看起来您提到的是某个系统或数据库中的销售数据操作。如果您有任何具体问题或需要进一步的帮助,例如数据恢复、系统操作等,请告诉我,我会尽力提供帮助!
LangGraph中构建supervisor很高效,代理监督和 StateGraph的构架方式可以极大简化工作流程、优化任务分配并增强多代理系统内的协作。但也存在一些问题。比如大家在后续尝试的过程中会发现经常可以看到主管不断地一次又一次地将一个代理的输出发送给自己,开始自言自语,这就会导致更高的运行时间和更高的Token消耗,同时,在决策方向选择其他代理人而不是首选代理人,从而导致幻觉。这些都是我们在自己应用的时候,结合具体的业务逻辑,以及所使用的大模型的原生能力进行针对性的调整。
而至于supervisor的变体 Supervisor (tool-calling) 和 Hierarchical,不过是以不同的方式对supervisor进行嵌套应用,可以更模块化、规范化代理的处理构建更庞大的Agent集群,但带来的问题同时也是更高的Token和更缓慢的处理速度,就目前 AI Agent的发展阶段来说,所应用的范畴还是较少。如果感兴趣可以在如下官网进一步了解。[https://docs.langchain.com/oss/javascript/langchain/multi-agent/index)
3、GraphRAG 基本介绍
检索增强生成(Retrieval-Augmented Generation)技术是一种结合了检索和生成两个阶段的自然语言处理技术,它由 Facebook AI 团队在 2020 年提出。这种方法的核心思想是利用大规模的预训练语言模型生成技术,并结合信息检索的策略,以改善回答的准确性和相关性。其核心流程如下:

这种传统的 RAG 通过 Text2Vec 检索的方式通过将生成的响应与现实世界的数据联系起来来减少幻觉,但准确回答复杂问题是另一回事。这在于每个文本嵌入都表示非结构化数据集中的一个特定块,通过最近邻算法搜索查找表示在语义上与传入用户查询相似的块的嵌入,这也意味着搜索是语义性的,但仍然高度具体。因此,候选块的质量在很大程度上取决于查询质量。就像翻阅一本食谱书一样。使用关键字搜索“炒鸡蛋”或“西红柿鸡蛋面”并找到说明,它速度很快,对于简单的问题非常有效。但是,如果你对这些菜肴背后的文化背景或是想知道为什么某些成分能够协同作用增加风味感兴趣,仅仅关键字搜索可能就显得力不从心。例如,西红柿和鸡蛋为何能搭配得如此完美?
同时,对于已经熟悉 RAG 的小伙伴来说,可能遇到了与我相同的头痛问题:
- 上下文在文本块之间丢失
- 随着检索到的文档的增长,性能会下降
- 整合外部知识感觉就像蒙着眼睛试图解开魔方
传统RAG系统在负责合成来自各种来源的信息或理解数据集中的总体主题时却很困难。例如,如果询问传统RAG 系统:“根据该研究数据集,全球气温变暖的主要原因是什么?”,它很难提供全面的答案,因为与气候相关的不同信息的分散在整个数据集中,而语义检索的方式没有办法跨整个数据集去做全局检索。这样的需求凸显了对 RAG 更加结构化和智能的方法的需求。这就是 GraphRAG(Graph Retrieval-Augmented Generation)派上用场的地方,它的核心作用是提高大模型的模型通过利用结构化知识图谱提供精确且上下文丰富的答案的能力。
4. GraphRAG的核心架构
GraphRAG通过利用大模型从原始文本数据中提取知识图谱来满足跨上下文检索的需求。该知识图将信息表示为互连实体和关系的网络,与简单的文本片段相比,提供了更丰富的数据表示。这种结构化表示使 GraphRAG 能够擅长回答需要推理和连接不同信息的复杂问题。具体来看,GraphRAG 定义了一个标准化数据模型,整体框架由几个关键组件组成,分别用于表示文档、TextUnit、实体、关系和社区报告等实体。像传统RAG一样,**GraphRAG 过程也涉及两个主要阶段:索引和查询**。我们依次展开来进行讨论。
在索引(Indexing)过程中,输入的文本被分为可管理的块,称为TextUnits 。然后大模型从这些文本单元中提取实体、关系和声明,形成知识图。完整的Indexing流程如下图所示:

在第二个阶段处理文本或数据时,graph extraction 和 graph summarization 是两个关键的阶段。**Graph Extraction(图抽取)的目标是从原始数据(如文本、数据库或网络活动)中识别实体(如人、地点、组织)和它们之间的关系,然后以图的形式表达这些信息。比如识别文本中的名词性短语或具体实体,例如人名、地名等,并确定实体之间的关系,如“工作于”、“位于”等。使用节点来表示实体,用边来表示实体间的关系,构建出一个图形结构。而Graph Summarization(图摘要)目的是将复杂的图结构简化,使其更易于理解和分析,同时保留图中最重要的信息**。输出结果是一个简化后的图,它在保留关键信息的同时,去除了不必要的细节和冗余。这有助于更快地理解图的主要结构和关系,特别是在大规模图数据的情境下。这个过程可能涉及:
- 节点和边的减少:通过合并相似的节点或边,减少图中的复杂性。
- 子图抽取:识别并提取图中重要的子图,这些子图代表了主要的信息或模式。
- 关键信息突出:强调最重要的节点和边,可能通过改变节点大小、边的粗细或颜色等方式来实现。
总结来说,graph extraction 主要是为了从数据中构建出有意义的图结构,而 graph summarization 则是为了将这个图简化,突出其主要的信息或模式。这两个阶段都是数据分析和知识管理中非常重要的步骤。
第三个阶段中的Leiden算法是一种用于检测图中社区结构的高效算法,它是Louvain算法的改进版,能够更快地收敛到更优的社区划分结果。这种算法特别适用于大规模网络,且在实际应用中非常流行,如社交网络分析、生物信息学和网络结构研究等领域。
想象一下,你正在参加一个聚会,你的工作是根据与谁交谈最多的人对他们进行分组。有些人形成紧密的群体,而另一些人则在群体之间流动。莱顿算法在图中的工作就是通过查看节点(人)的联系(对话)并将那些联系最紧密的人聚集在一起,将节点(人)分组为社区。具体工作原理如下:
- 初始分组:首先根据节点的连接对节点进行分组。如果两个人(节点)频繁交互,则将他们放置在同一组中。
- 细化组:然后检查是否有任何节点属于不同的组,类似于在聚会的对话之间移动的人。如果它们更适合其他地方,算法就会将它们移动。
- 分裂和合并:最后,较大的群体被分成较小的群体,如果它们具有很强的内部联系,则重新合并 - 形成更紧密的集群。
而在第四个阶段中,在图论和网络分析中,”社区报告”(Community Reporting)通常指的是对图中检测到的社区(即图中节点的集合,这些节点内部连接紧密而与外部节点连接较少)的详细描述和分析的过程。这种报告可以提供关于图中社区结构的洞察,帮助理解网络的组织方式、群体行为、信息流动等特性。生成社区报告(Community Reporting)和摘要社区报告(Summarizing Community Reports)之间的关系基本上是详细程度和目的的不同。生成社区报告是一个涉及数据分析、社区检测和详细描述各社区特征的过程。而摘要社区报告则侧重于将这些详细的报告简化成更易于理解和快速获取信息的形式。
GraphRAG整个Indexing过程可以通过如下更简单的方式来理解:
- 从分块到较小子文档的源文档开始(类似于传统的 RAG)
- 执行两个并行提取:实体提取:识别人员、地点、公司等实体,关系提取:查找不同数据块中实体之间的连接
- 创建知识图谱,其中节点表示实体,边缘表示它们的关系
- 通过识别密切相关的实体来构建社区
- 生成不同社区级别(三个级别)的分层摘要
- 使用 reduce-map 方法通过逐步组合块来创建摘要,直到实现整体概览
在查询阶段,处理流程更为直观,具体步骤包括:
- 接收用户的查询请求。
- 根据查询所需的详细程度,选择合适的社区级别进行分析。
- 在选定的社区级别进行信息检索,相较于传统的以数据块为单位的检索,这种方法更具针对性。
- 依据社区摘要生成初步的响应,这一步是为了快速提供关键信息。
- 将多个相关社区的初步回应整合,形成一个全面的最终答案。
如下图所示:

GraphRAG 的关键创新在于它将信息构建为基于图形的格式,并使用社区检测来创建更具上下文感知能力的响应。因此围绕不同的Indexing和Query流程,会有非常多种不同的实现GraphRAG方式。我们可以选择使用开源工具,或者依据 GraphRAG 的设计理念,灵活构建自定义的解决方案。例如,结合使用 Neo4j + LangChain 就是一种目前非常热门且广泛应用的方法。接下来我们就给大家展示一下如何通过构造多代理下的混合知识库检索。
5、案例:Multi-Agent实现混合多知识库检索
在本案例中,我们将探讨和实践如何使用 Neo4j 和 LangChain 来实现 GraphRAG。 Neo4j 是一种流行的图形数据库,用于以类似图形的结构表示数据,其中实体是节点,实体之间的关系是边。当与 LangChain 集成时,Neo4j 就变成了使用结构化图数据执行RAG 的强大工具。Neo4j的使用主要有两种方式,一种是本地安装,另一种则是可以使用云服务,这里我们选择使用Neo4j Aura,它提供了一个免费的实例可以供我们使用。
5.1 配置Neo4j图数据库实例
首先,登录该地址注册免费账户:https://console.neo4j.io/?product=aura-db&tenant=2afe251b-59ae-5517-9598-84fc5d57b0b5
创建Neo4j实例:
这里可以选择一个免费的实例:
创建的时候记得保存密码,将用于后续的连接。
等待创建完成。
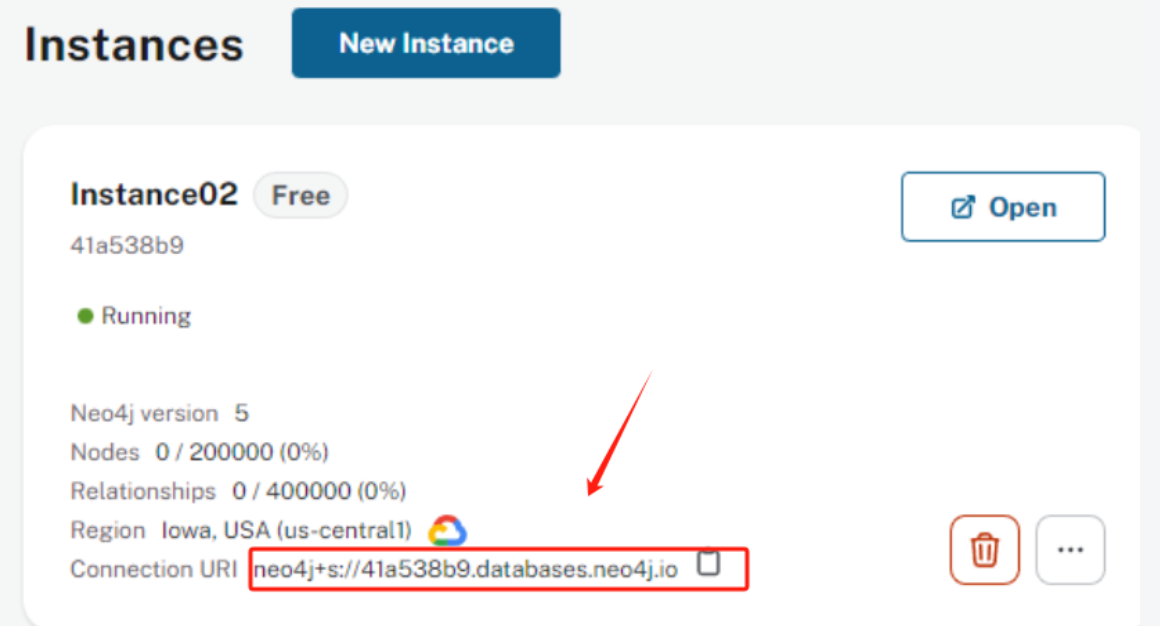
创建完成后,将会生成一个远程连接的Uri。
5.2 创建图索引及构建GraphRAG Agent
在将数据 引入Neo4j图数据库之前,一般来说我们会将数据(例如 .txt 或 .csv 文件)拆分为可管理的块。可以使用LangChain框架的 TextLoader 和 RecursiveCharacterTextSplitter 来完成。用于演示目的,我们此处不进行分块,将完整的文档作为一个 TextUnit进行图属性的提取。
1 | # 打开文件,并赋予读取模式 'r' |
小米科技有限责任公司(小米):
产品创新: 小米持续推动技术创新,尤其在智能手机摄像技术和快充技术方面取得突破。例如,小米推出了首款1亿像素手机摄像头,大幅提升了手机摄影的质量。此外,小米还开发了120W超快闪充技术,可以在15分钟内为手机充满电,这一技术在行业中引起了广泛关注。
市场扩展: 小米积极开拓国际市场,特别是在印度、东南亚和欧洲市场表现突出。小米通过与当地电信运营商合作,推广其智能手机和生态链产品,迅速在当地市场建立了品牌影响力。例如,在印度,小米通过在线和离线双渠道销售策略迅速占领了市场,成为智能手机市场的领导者之一。
企业社会责任: 小米非常注重其企业社会责任,积极参与社会公益活动。小米设立了多个基金会,支持教育和科技创新项目,例如通过小米基金会资助贫困地区的学校建设和提供科技设备,帮助提升教育质量。此外,小米还在产品设计中采用环保材料,推广环保理念。
品牌合作与宣传: 小米在品牌合作方面表现活跃,与世界各大品牌如Adobe、微软等进行合作,共同开发更多功能强大的手机应用和服务。此外,小米通过赞助体育赛事和文化活动等多种方式提升品牌知名度,如成为欧洲足球俱乐部的官方赞助商。
华为技术有限公司(华为):
技术研发和创新: 华为在全球设有20多个研发中心,不断推动通信技术的创新和前瞻性研究。华为的研发重点包括5G网络技术、云计算、大数据解决方案以及人工智能。华为的鸿蒙操作系统(HarmonyOS)是一个多设备分布式操作系统,旨在提供跨平台的无缝体验,这标志着华为在自主知识产权方面迈出了重要步伐。
全球市场战略: 华为致力于在全球市场中扩大其影响力,尤其在欧洲、亚洲和非洲。尽管面临国际贸易限制,华为通过与地方政府和企业的紧密合作,成功部署了多个5G网络项目,并通过提供定制化的ICT解决方案来巩固其市场地位。华为还通过举办技术峰会和参与国际通信展览会,如巴塞尔世界移动通信大会,增强其品牌可见度。
合作与伙伴关系: 华为与全球多家顶尖大学和研究机构建立了合作关系,共同进行技术研究和开发。例如,华为与英国的剑桥大学合作开发下一代光通信技术。此外,华为在全球范围内与多家IT和电信企业建立了战略合作伙伴关系,共同推动通信技术的发展和应用。
社会责任与企业文化: 华为注重企业社会责任,积极参与全球的教育和健康项目。例如,华为“未来种子计划”旨在通过提供技术培训和教育资源,培养发展中国家的ICT人才。华为还通过其灾难响应计划,在全球多地发生自然灾害时提供通信支持和技术援助。企业文化上,华为强调“客户为先,员工次之,股东第三”的理念,这一理念指导了华为的业务运作和决策过程。
苹果公司(Apple Inc.):
产品创新与技术发展: 苹果公司以其创新的产品设计和技术应用而闻名。苹果不断推动操作系统和硬件的升级,例如推出了具有先进芯片技术的MacBook和iPhone系列。苹果还在人工智能和机器学习领域进行了深入研究,其Siri语音助手和面部识别技术是市场上的佼佼者。此外,苹果对产品的生态系统整合提供了无缝体验,包括iCloud、Apple Music和App Store等服务。
全球市场策略: 苹果公司在全球范围内拥有坚固的市场地位,特别是在美国、欧洲和中国。苹果通过其零售店铺,如位于纽约、伦敦和北京的旗舰店,以及在线商店,有效地触达消费者。苹果还通过各种市场营销活动和广告策略,如其著名的产品发布会,加强品牌忠诚度和消费者参与。
环境责任和可持续发展: 苹果公司在环境保护方面采取了积极措施,致力于减少其业务对环境的影响。苹果实施了全面的再生材料使用计划,并承诺到2030年使其全部产品和供应链实现100%碳中和。苹果还推动其供应商使用可再生能源,并持续改进产品的能效。
合作伙伴和行业关系: 苹果与全球多家顶尖技术和媒体公司建立了合作,如与英特尔和谷歌在某些技术项目上的合作。苹果还通过与好莱坞制片厂和音乐制作公司的合作,强化了其在Apple TV+和Apple Music上的内容库。这些合作不仅扩展了苹果的产品和服务范围,还增强了其在相关行业的影响力。
转化成Document对象。
1 | from langchain_core.documents import Document |
1 | documents |
[Document(metadata={}, page_content='小米科技有限责任公司(小米):\n\n产品创新: 小米持续推动技术创新,尤其在智能手机摄像技术和快充技术方面取得突破。例如,小米推出了首款1亿像素手机摄像头,大幅提升了手机摄影的质量。此外,小米还开发了120W超快闪充技术,可以在15分钟内为手机充满电,这一技术在行业中引起了广泛关注。\n\n市场扩展: 小米积极开拓国际市场,特别是在印度、东南亚和欧洲市场表现突出。小米通过与当地电信运营商合作,推广其智能手机和生态链产品,迅速在当地市场建立了品牌影响力。例如,在印度,小米通过在线和离线双渠道销售策略迅速占领了市场,成为智能手机市场的领导者之一。\n\n企业社会责任: 小米非常注重其企业社会责任,积极参与社会公益活动。小米设立了多个基金会,支持教育和科技创新项目,例如通过小米基金会资助贫困地区的学校建设和提供科技设备,帮助提升教育质量。此外,小米还在产品设计中采用环保材料,推广环保理念。\n\n品牌合作与宣传: 小米在品牌合作方面表现活跃,与世界各大品牌如Adobe、微软等进行合作,共同开发更多功能强大的手机应用和服务。此外,小米通过赞助体育赛事和文化活动等多种方式提升品牌知名度,如成为欧洲足球俱乐部的官方赞助商。\n\n\n\n\n华为技术有限公司(华为):\n\n技术研发和创新: 华为在全球设有20多个研发中心,不断推动通信技术的创新和前瞻性研究。华为的研发重点包括5G网络技术、云计算、大数据解决方案以及人工智能。华为的鸿蒙操作系统(HarmonyOS)是一个多设备分布式操作系统,旨在提供跨平台的无缝体验,这标志着华为在自主知识产权方面迈出了重要步伐。\n\n全球市场战略: 华为致力于在全球市场中扩大其影响力,尤其在欧洲、亚洲和非洲。尽管面临国际贸易限制,华为通过与地方政府和企业的紧密合作,成功部署了多个5G网络项目,并通过提供定制化的ICT解决方案来巩固其市场地位。华为还通过举办技术峰会和参与国际通信展览会,如巴塞尔世界移动通信大会,增强其品牌可见度。\n\n合作与伙伴关系: 华为与全球多家顶尖大学和研究机构建立了合作关系,共同进行技术研究和开发。例如,华为与英国的剑桥大学合作开发下一代光通信技术。此外,华为在全球范围内与多家IT和电信企业建立了战略合作伙伴关系,共同推动通信技术的发展和应用。\n\n社会责任与企业文化: 华为注重企业社会责任,积极参与全球的教育和健康项目。例如,华为“未来种子计划”旨在通过提供技术培训和教育资源,培养发展中国家的ICT人才。华为还通过其灾难响应计划,在全球多地发生自然灾害时提供通信支持和技术援助。企业文化上,华为强调“客户为先,员工次之,股东第三”的理念,这一理念指导了华为的业务运作和决策过程。\n\n\n苹果公司(Apple Inc.):\n\n产品创新与技术发展: 苹果公司以其创新的产品设计和技术应用而闻名。苹果不断推动操作系统和硬件的升级,例如推出了具有先进芯片技术的MacBook和iPhone系列。苹果还在人工智能和机器学习领域进行了深入研究,其Siri语音助手和面部识别技术是市场上的佼佼者。此外,苹果对产品的生态系统整合提供了无缝体验,包括iCloud、Apple Music和App Store等服务。\n\n全球市场策略: 苹果公司在全球范围内拥有坚固的市场地位,特别是在美国、欧洲和中国。苹果通过其零售店铺,如位于纽约、伦敦和北京的旗舰店,以及在线商店,有效地触达消费者。苹果还通过各种市场营销活动和广告策略,如其著名的产品发布会,加强品牌忠诚度和消费者参与。\n\n环境责任和可持续发展: 苹果公司在环境保护方面采取了积极措施,致力于减少其业务对环境的影响。苹果实施了全面的再生材料使用计划,并承诺到2030年使其全部产品和供应链实现100%碳中和。苹果还推动其供应商使用可再生能源,并持续改进产品的能效。\n\n合作伙伴和行业关系: 苹果与全球多家顶尖技术和媒体公司建立了合作,如与英特尔和谷歌在某些技术项目上的合作。苹果还通过与好莱坞制片厂和音乐制作公司的合作,强化了其在Apple TV+和Apple Music上的内容库。这些合作不仅扩展了苹果的产品和服务范围,还增强了其在相关行业的影响力。')]
准备好数据后,我们可以使用 langchain_experimental.graph_transformers 中的 LLMGraphTransformer 将其摄取到 Neo4j 中。该工具会自动将文档转换为图格式。LLMGraphTransformer 能够以两种完全独立的模式运行:
- Tool-Based 模式(默认):当使用的大模型支持结构化输出或函数调用时,该模式利用内置的
with_structured_output来使用工具。工具规范定义了输出格式,确保以结构化、预定义的方式提取实体和关系。 - 基于提示的模式(回退):在使用的大模型不支持工具或函数调用的情况下, 该转换器回退到纯粹提示驱动的方法。该模式使用
few-shot提示来定义输出格式,指导大模型以基于文本的方式提取实体和关系。然后通过自定义函数解析结果,该函数将大模型的输出转换为JSON格式。该JSON用于填充节点和关系。
1 | # GraphRAG Setup |
使用convert_to_graph_documents函数处理文档,进行实体和关系的提取。可以自定义,当allowed_nodes和allowed_relationships不手动填写的时候,它会自动判断并进行提取。
1 | # 图转换器配置 |
Graph documents: 1
Nodes from 1st graph doc:[Node(id='小米科技有限责任公司', type='Company', properties={}), Node(id='华为技术有限公司', type='Company', properties={}), Node(id='苹果公司', type='Company', properties={}), Node(id='智能手机摄像技术', type='Technology', properties={}), Node(id='快充技术', type='Technology', properties={}), Node(id='1亿像素手机摄像头', type='Product', properties={}), Node(id='120W超快闪充技术', type='Technology', properties={}), Node(id='国际市场', type='Market', properties={}), Node(id='印度市场', type='Market', properties={}), Node(id='东南亚市场', type='Market', properties={}), Node(id='欧洲市场', type='Market', properties={}), Node(id='小米基金会', type='Organization', properties={}), Node(id='教育项目', type='Project', properties={}), Node(id='科技创新项目', type='Project', properties={}), Node(id='环保材料', type='Material', properties={}), Node(id='Adobe', type='Brand', properties={}), Node(id='微软', type='Brand', properties={}), Node(id='5G网络技术', type='Technology', properties={}), Node(id='云计算', type='Technology', properties={}), Node(id='大数据解决方案', type='Technology', properties={}), Node(id='人工智能', type='Technology', properties={}), Node(id='鸿蒙操作系统', type='Product', properties={}), Node(id='Ict解决方案', type='Solution', properties={}), Node(id='剑桥大学', type='Organization', properties={}), Node(id='未来种子计划', type='Project', properties={}), Node(id='Siri语音助手', type='Product', properties={}), Node(id='面部识别技术', type='Technology', properties={}), Node(id='Icloud', type='Service', properties={}), Node(id='Apple Music', type='Service', properties={}), Node(id='App Store', type='Service', properties={}), Node(id='再生材料使用计划', type='Project', properties={}), Node(id='碳中和', type='Goal', properties={}), Node(id='英特尔', type='Brand', properties={}), Node(id='谷歌', type='Brand', properties={}), Node(id='Apple Tv+', type='Service', properties={})]
Relationships from 1st graph doc:[Relationship(source=Node(id='小米科技有限责任公司', type='Company', properties={}), target=Node(id='智能手机摄像技术', type='Technology', properties={}), type='INNOVATES', properties={}), Relationship(source=Node(id='小米科技有限责任公司', type='Company', properties={}), target=Node(id='快充技术', type='Technology', properties={}), type='INNOVATES', properties={}), Relationship(source=Node(id='小米科技有限责任公司', type='Company', properties={}), target=Node(id='1亿像素手机摄像头', type='Product', properties={}), type='LAUNCHES', properties={}), Relationship(source=Node(id='小米科技有限责任公司', type='Company', properties={}), target=Node(id='120W超快闪充技术', type='Technology', properties={}), type='DEVELOPS', properties={}), Relationship(source=Node(id='小米科技有限责任公司', type='Company', properties={}), target=Node(id='国际市场', type='Market', properties={}), type='EXPANDS', properties={}), Relationship(source=Node(id='小米科技有限责任公司', type='Company', properties={}), target=Node(id='印度市场', type='Market', properties={}), type='EXPANDS', properties={}), Relationship(source=Node(id='小米科技有限责任公司', type='Company', properties={}), target=Node(id='东南亚市场', type='Market', properties={}), type='EXPANDS', properties={}), Relationship(source=Node(id='小米科技有限责任公司', type='Company', properties={}), target=Node(id='欧洲市场', type='Market', properties={}), type='EXPANDS', properties={}), Relationship(source=Node(id='小米科技有限责任公司', type='Company', properties={}), target=Node(id='小米基金会', type='Organization', properties={}), type='ESTABLISHES', properties={}), Relationship(source=Node(id='小米基金会', type='Organization', properties={}), target=Node(id='教育项目', type='Project', properties={}), type='SUPPORTS', properties={}), Relationship(source=Node(id='小米基金会', type='Organization', properties={}), target=Node(id='科技创新项目', type='Project', properties={}), type='SUPPORTS', properties={}), Relationship(source=Node(id='小米科技有限责任公司', type='Company', properties={}), target=Node(id='环保材料', type='Material', properties={}), type='USES', properties={}), Relationship(source=Node(id='小米科技有限责任公司', type='Company', properties={}), target=Node(id='Adobe', type='Brand', properties={}), type='PARTNERS_WITH', properties={}), Relationship(source=Node(id='小米科技有限责任公司', type='Company', properties={}), target=Node(id='微软', type='Brand', properties={}), type='PARTNERS_WITH', properties={}), Relationship(source=Node(id='华为技术有限公司', type='Company', properties={}), target=Node(id='5G网络技术', type='Technology', properties={}), type='INNOVATES', properties={}), Relationship(source=Node(id='华为技术有限公司', type='Company', properties={}), target=Node(id='云计算', type='Technology', properties={}), type='INNOVATES', properties={}), Relationship(source=Node(id='华为技术有限公司', type='Company', properties={}), target=Node(id='大数据解决方案', type='Technology', properties={}), type='INNOVATES', properties={}), Relationship(source=Node(id='华为技术有限公司', type='Company', properties={}), target=Node(id='人工智能', type='Technology', properties={}), type='INNOVATES', properties={}), Relationship(source=Node(id='华为技术有限公司', type='Company', properties={}), target=Node(id='鸿蒙操作系统', type='Product', properties={}), type='DEVELOPS', properties={}), Relationship(source=Node(id='华为技术有限公司', type='Company', properties={}), target=Node(id='Ict解决方案', type='Solution', properties={}), type='PROVIDES', properties={}), Relationship(source=Node(id='华为技术有限公司', type='Company', properties={}), target=Node(id='剑桥大学', type='Organization', properties={}), type='PARTNERS_WITH', properties={}), Relationship(source=Node(id='华为技术有限公司', type='Company', properties={}), target=Node(id='未来种子计划', type='Project', properties={}), type='SUPPORTS', properties={}), Relationship(source=Node(id='苹果公司', type='Company', properties={}), target=Node(id='产品创新与技术发展', type='Project', properties={}), type='INVOLVES', properties={}), Relationship(source=Node(id='苹果公司', type='Company', properties={}), target=Node(id='Siri语音助手', type='Product', properties={}), type='DEVELOPS', properties={}), Relationship(source=Node(id='苹果公司', type='Company', properties={}), target=Node(id='面部识别技术', type='Technology', properties={}), type='DEVELOPS', properties={}), Relationship(source=Node(id='苹果公司', type='Company', properties={}), target=Node(id='Icloud', type='Service', properties={}), type='PROVIDES', properties={}), Relationship(source=Node(id='苹果公司', type='Company', properties={}), target=Node(id='Apple Music', type='Service', properties={}), type='PROVIDES', properties={}), Relationship(source=Node(id='苹果公司', type='Company', properties={}), target=Node(id='App Store', type='Service', properties={}), type='PROVIDES', properties={}), Relationship(source=Node(id='苹果公司', type='Company', properties={}), target=Node(id='再生材料使用计划', type='Project', properties={}), type='IMPLEMENTS', properties={}), Relationship(source=Node(id='苹果公司', type='Company', properties={}), target=Node(id='碳中和', type='Goal', properties={}), type='COMMITS_TO', properties={}), Relationship(source=Node(id='苹果公司', type='Company', properties={}), target=Node(id='英特尔', type='Brand', properties={}), type='PARTNERS_WITH', properties={}), Relationship(source=Node(id='苹果公司', type='Company', properties={}), target=Node(id='谷歌', type='Brand', properties={}), type='PARTNERS_WITH', properties={}), Relationship(source=Node(id='苹果公司', type='Company', properties={}), target=Node(id='Apple Tv+', type='Service', properties={}), type='PROVIDES', properties={})]
完成后,可以查看Neo4j Aura 平台查看存储的节点,如下图所示:
进入后即可查看到生成的知识图谱:
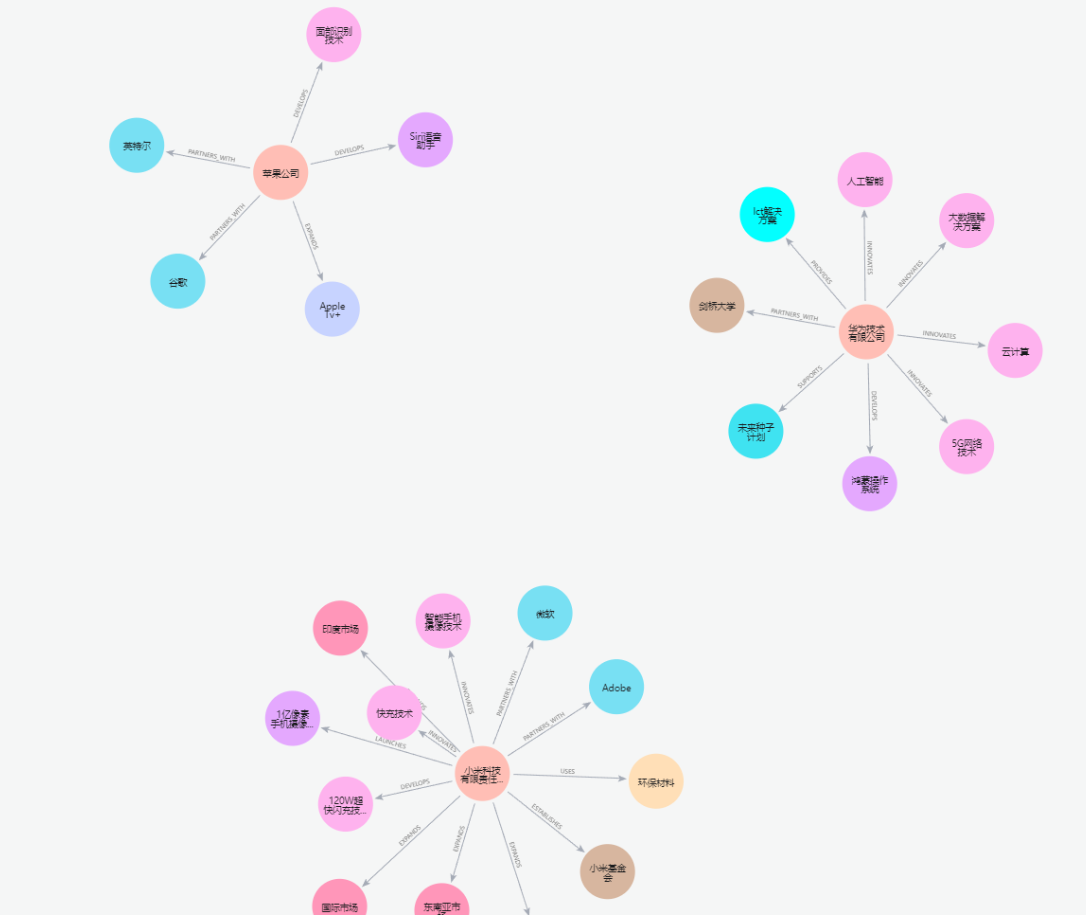
Neo4j 通过利用图算法(例如 PageRank 或社区检测)来检索子图。这些算法识别相关实体的集群,LangChain 从 Neo4j 检索子图并通过大模型生成响应,这里可以使用到GraphCypherQAChain工具,代码如下:
1 | from langchain.chains import GraphCypherQAChain |
[1m> Entering new GraphCypherQAChain chain...[0m
Generated Cypher:
[32;1m[1;3mcypher
MATCH (c:Company {id: '小米科技有限责任公司'})-[:INNOVATES]->(t:Technology)
RETURN t.id
[0m
Full Context:
[32;1m[1;3m[{'t.id': '智能手机摄像技术'}, {'t.id': '快充技术'}][0m
[1m> Finished chain.[0m
{'query': '小米科技有限责任公司推出了哪些创新技术?', 'result': '小米科技有限责任公司推出了智能手机摄像技术和快充技术。'}
1 | llm = ChatOpenAI(model="gpt-4o-mini", temperature=0) |
[1m> Entering new GraphCypherQAChain chain...[0m
Generated Cypher:
[32;1m[1;3mcypher
MATCH (c:Company {id: '华为技术有限公司'})-[:PARTNERS_WITH]->(o:Organization)
RETURN o.id
[0m
Full Context:
[32;1m[1;3m[{'o.id': '剑桥大学'}][0m
[1m> Finished chain.[0m
{'query': '华为技术有限公司与哪些教育机构建立了合作?', 'result': '华为技术有限公司与剑桥大学建立了合作。'}
1 | llm = ChatOpenAI(model="gpt-4o-mini", temperature=0) |
[1m> Entering new GraphCypherQAChain chain...[0m
Generated Cypher:
[32;1m[1;3mcypher
MATCH (c:Company) RETURN c
[0m
Full Context:
[32;1m[1;3m[{'c': {'id': '小米科技有限责任公司'}}, {'c': {'id': '华为技术有限公司'}}, {'c': {'id': '苹果公司'}}][0m
[1m> Finished chain.[0m
{'query': '都有哪些公司在我的数据库中?', 'result': '在您的数据库中,有小米科技有限责任公司、华为技术有限公司和苹果公司。'}
1 | cypher_chain = GraphCypherQAChain.from_llm( |
1 | response["result"] |
'在您的数据库中,有小米科技有限责任公司、华为技术有限公司和苹果公司。'
其中的内部原理如下所示:
1 | cypher_prompt = PromptTemplate( |
我们封装成多代理系统中的一个工具。如下代码所示:
1 | from langgraph.graph import StateGraph, MessagesState, START, END |
1 | def graph_kg(state: AgentState): |
5.3 创建传统RAG Agent
1 | from langchain_text_splitters import RecursiveCharacterTextSplitter |
[Document(metadata={'id': '7d1a58e8a810b48adbe5e0ac09de2cb9'}, page_content='小米科技有限责任公司(小米):\n\n产品创新: 小米持续推动技术创新,尤其在智能手机摄像技术和快充技术方面取得突破。例如,小米推出了首款1亿像素手机摄像头,大幅提升了手机摄影的质量。此外,小米还开发了120W超快闪充技术,可以在15分钟内为手机充满电,这一技术在行业中引起了广泛关注。'),
Document(metadata={'id': '7d1a58e8a810b48adbe5e0ac09de2cb9'}, page_content='市场扩展: 小米积极开拓国际市场,特别是在印度、东南亚和欧洲市场表现突出。小米通过与当地电信运营商合作,推广其智能手机和生态链产品,迅速在当地市场建立了品牌影响力。例如,在印度,小米通过在线和离线双渠道销售策略迅速占领了市场,成为智能手机市场的领导者之一。'),
Document(metadata={'id': '7d1a58e8a810b48adbe5e0ac09de2cb9'}, page_content='企业社会责任: 小米非常注重其企业社会责任,积极参与社会公益活动。小米设立了多个基金会,支持教育和科技创新项目,例如通过小米基金会资助贫困地区的学校建设和提供科技设备,帮助提升教育质量。此外,小米还在产品设计中采用环保材料,推广环保理念。\n\n品牌合作与宣传: 小米在品牌合作方面表现活跃,与世界各大品牌如Adobe、微软等进行合作,共同开发更多功能强大的手机应用和服务。此外,小米通过赞助体育赛事和文化活动等多种方式提升品牌知名度,如成为欧洲足球俱乐部的官方赞助商。'),
Document(metadata={'id': '7d1a58e8a810b48adbe5e0ac09de2cb9'}, page_content='华为技术有限公司(华为):\n\n技术研发和创新: 华为在全球设有20多个研发中心,不断推动通信技术的创新和前瞻性研究。华为的研发重点包括5G网络技术、云计算、大数据解决方案以及人工智能。华为的鸿蒙操作系统(HarmonyOS)是一个多设备分布式操作系统,旨在提供跨平台的无缝体验,这标志着华为在自主知识产权方面迈出了重要步伐。'),
Document(metadata={'id': '7d1a58e8a810b48adbe5e0ac09de2cb9'}, page_content='全球市场战略: 华为致力于在全球市场中扩大其影响力,尤其在欧洲、亚洲和非洲。尽管面临国际贸易限制,华为通过与地方政府和企业的紧密合作,成功部署了多个5G网络项目,并通过提供定制化的ICT解决方案来巩固其市场地位。华为还通过举办技术峰会和参与国际通信展览会,如巴塞尔世界移动通信大会,增强其品牌可见度。'),
Document(metadata={'id': '7d1a58e8a810b48adbe5e0ac09de2cb9'}, page_content='合作与伙伴关系: 华为与全球多家顶尖大学和研究机构建立了合作关系,共同进行技术研究和开发。例如,华为与英国的剑桥大学合作开发下一代光通信技术。此外,华为在全球范围内与多家IT和电信企业建立了战略合作伙伴关系,共同推动通信技术的发展和应用。'),
Document(metadata={'id': '7d1a58e8a810b48adbe5e0ac09de2cb9'}, page_content='社会责任与企业文化: 华为注重企业社会责任,积极参与全球的教育和健康项目。例如,华为“未来种子计划”旨在通过提供技术培训和教育资源,培养发展中国家的ICT人才。华为还通过其灾难响应计划,在全球多地发生自然灾害时提供通信支持和技术援助。企业文化上,华为强调“客户为先,员工次之,股东第三”的理念,这一理念指导了华为的业务运作和决策过程。\n\n\n苹果公司(Apple Inc.):'),
Document(metadata={'id': '7d1a58e8a810b48adbe5e0ac09de2cb9'}, page_content='苹果公司(Apple Inc.):\n\n产品创新与技术发展: 苹果公司以其创新的产品设计和技术应用而闻名。苹果不断推动操作系统和硬件的升级,例如推出了具有先进芯片技术的MacBook和iPhone系列。苹果还在人工智能和机器学习领域进行了深入研究,其Siri语音助手和面部识别技术是市场上的佼佼者。此外,苹果对产品的生态系统整合提供了无缝体验,包括iCloud、Apple Music和App Store等服务。'),
Document(metadata={'id': '7d1a58e8a810b48adbe5e0ac09de2cb9'}, page_content='全球市场策略: 苹果公司在全球范围内拥有坚固的市场地位,特别是在美国、欧洲和中国。苹果通过其零售店铺,如位于纽约、伦敦和北京的旗舰店,以及在线商店,有效地触达消费者。苹果还通过各种市场营销活动和广告策略,如其著名的产品发布会,加强品牌忠诚度和消费者参与。'),
Document(metadata={'id': '7d1a58e8a810b48adbe5e0ac09de2cb9'}, page_content='环境责任和可持续发展: 苹果公司在环境保护方面采取了积极措施,致力于减少其业务对环境的影响。苹果实施了全面的再生材料使用计划,并承诺到2030年使其全部产品和供应链实现100%碳中和。苹果还推动其供应商使用可再生能源,并持续改进产品的能效。'),
Document(metadata={'id': '7d1a58e8a810b48adbe5e0ac09de2cb9'}, page_content='合作伙伴和行业关系: 苹果与全球多家顶尖技术和媒体公司建立了合作,如与英特尔和谷歌在某些技术项目上的合作。苹果还通过与好莱坞制片厂和音乐制作公司的合作,强化了其在Apple TV+和Apple Music上的内容库。这些合作不仅扩展了苹果的产品和服务范围,还增强了其在相关行业的影响力。')]
这里我们同样使用免费的在线milvus实例,地址如下:https://cloud.zilliz.com/login?redirect=/orgs , 先注册登录:
然后创建索引:
选择免费实例:
注意:这里需要保存好用户名和密码,用于接下来的远程连接。
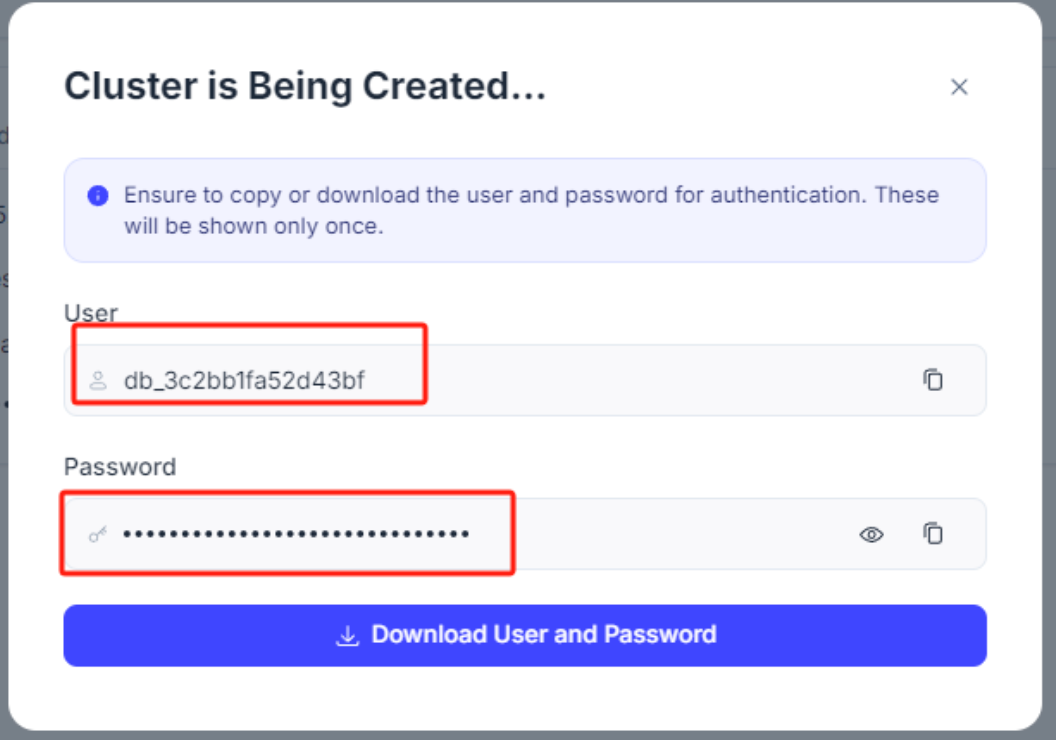
等待创建完成后,注意关注如下信息:
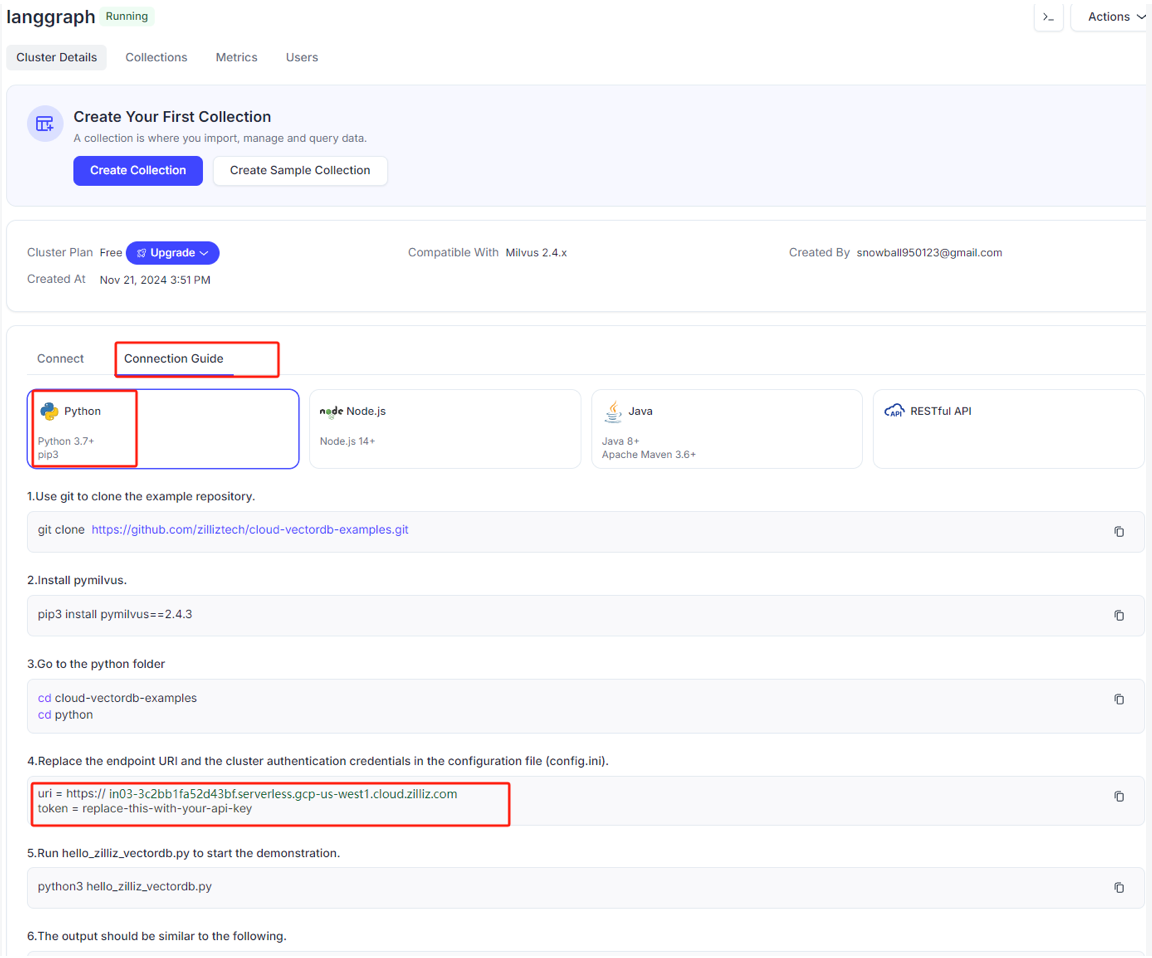
1 | from langchain_openai import OpenAIEmbeddings |
通过如下代码构建向量索引,并存储到云端的Milvus向量数据库中。
1 | from langchain.text_splitter import RecursiveCharacterTextSplitter |
同时可以登录网页端进行确认:

1 | from langchain.prompts import PromptTemplate |
[Document(metadata={'id': '7d1a58e8a810b48adbe5e0ac09de2cb9', 'pk': 454081515405496929}, page_content='华为技术有限公司(华为):\n\n技术研发和创新: 华为在全球设有20多个研发中心,不断推动通信技术的创新和前瞻性研究。华为的研发重点包括5G网络技术、云计算、大数据解决方案以及人工智能。华为的鸿蒙操作系统(HarmonyOS)是一个多设备分布式操作系统,旨在提供跨平台的无缝体验,这标志着华为在自主知识产权方面迈出了重要步伐。')]
运行 RAG_chain,生成最终的回复。
1 | generation = rag_chain.invoke({"context": docs, "question": question}) |
你的知识库中包含华为技术有限公司的信息,主要涉及其技术研发和创新。华为在全球设有多个研发中心,专注于5G、云计算、大数据和人工智能等领域。它的鸿蒙操作系统标志着在自主知识产权方面的重要进展。
构建传统 RAG 的Agent节点:
1 | def vec_kg(state: AgentState): |
5.4 构建混合知识库检索多代理系统
1 | from langgraph.graph import StateGraph, MessagesState, START, END |
1 | def graph_kg(state: AgentState): |
1 | def db_node(state: AgentState): |
1 | def chat(state: AgentState): |
新增两个不同的数据库代理节点:
1 | members = ["chat", "coder", "sqler", "graph_kg", "vec_kg"] |
1 | from typing import Literal |
Literal是Python的typing模块中的一个类型,用于定义一个变量的具体值的类型限制。当使用Literal时,实际上是在告诉Python,变量的值必须是指定的几个值中的一个。而 next: Literal["chat", "coder", "sqler"]意味着next属性只能赋予三个字符串值之一:”chat”、”coder”、”sqler”或”FINISH”, 分别用来表示使用哪一个子代理来执行任务,或者直接通过END结束当前的图。
1 | from langchain_core.messages import AnyMessage, SystemMessage, HumanMessage, ToolMessage |
1 | builder = StateGraph(AgentState) |
<langgraph.graph.state.StateGraph at 0x17ce41d35d0>
然后让每个子代理在完成工作后总是向主管“汇报”,即需要构建它们之间的边。如下所示:
1 | for member in members: |
然后在图状态中填充next字段,路由到具体的某个节点或者结束图的运行,从来指定如何执行接下来的任务。
1 | builder.add_conditional_edges("supervisor", lambda state: state["next"]) |
1 | from IPython.display import Image, display |

编译完成后,就可以进行问答了,这里我们测试几轮不同的问题类型:
1 | for chunk in graph.stream({"messages": "都有哪些公司在我的数据库中。"}, stream_mode="values"): |
================================[1m Human Message [0m=================================
都有哪些公司在我的数据库中。
================================[1m Human Message [0m=================================
都有哪些公司在我的数据库中。
================================[1m Human Message [0m=================================
Name: graph_kg
在您的数据库中有小米科技有限责任公司、华为技术有限公司和苹果公司。
================================[1m Human Message [0m=================================
Name: graph_kg
在您的数据库中有小米科技有限责任公司、华为技术有限公司和苹果公司。