MySQL锁机制
1、锁机制介绍
概念
- 锁是计算机协调多个进程或线程并发访问某一资源的机制,在数据库中,数据是一种供许多用户共享的资源,因此需要借助锁来解决数据并发访问的一致性、有效性。
锁的分类
从锁的粒度分:
- 行锁:是MySQL中锁定粒度最细的一种锁,表示只针对当前操作的行进行加锁。行级锁能大大减少数据库操作的冲突。其加锁粒度最小,但加锁的开销也最大。有可能会出现死锁的情况。 InnoDB行锁是通过给索引项加锁实现的,如果没有索引,InnoDB会通过隐藏的聚簇索引来对记录加锁。
- 表锁:是MySQL锁中粒度最大的一种锁,表示当前的操作对整张表加锁,资源开销比行锁少,不会出现死锁的情况,但是发生锁冲突的概率很大。被大部分的MySQL引擎支持,MyISAM和InnoDB都支持表级锁,但是InnoDB默认的是行级锁。
- 页锁:是MySQL中锁定粒度介于行级锁和表级锁中间的一种锁。表级锁速度快,但冲突多,行级冲突少,但速度慢。所以取了折衷的页级,一次锁定相邻的一组记录。BDB支持页级锁。
从使用的方式分:
读锁(共享锁):针对同一份数据,多个读操作可以同时进行而不会相互影响。共享锁就是允许多个线程同时获取一个锁,一个锁可以同时被多个线程拥有。语法如下:
1
2
3
4# 对读取到的数据行加读锁,其它事务能够能够读取加锁的的行,但是不能修改。当事务提交时锁会释放。
select ... lock in share mode
# 对指定的表加读锁,其它事务只可以查询此表,但是不能修改。可以使用unlock tables命令解锁或者当一个事务提交时也会自动解锁。
lock table <表名> read- 假设事务A对表1加了读锁,则:
- 事务A可以读取表1但不可以修改表1的记录;其它事务可以查询表1的记录,但对表1的修改操作都会被阻塞直至事务A释放读锁。
- 其它事务只能对表1加读锁而不能加写锁,直至事务A释放读锁。
- 假设事务A对表1加了读锁,则:
写锁(排他锁):当前写操作没有完成前,它会阻断其他写锁和读锁。语法如下:
1
2
3
4# 对读取到的数据行加写锁,其它事务不能读取和修改这些记录。当事务提交时锁会释放。
select ... for update
# 对指定的表加写锁,其它事务不可以查询和修改此表。可以使用unlock tables命令解锁或者当一个事务提交时也会自动解锁。
lock table <表名> write- 假设事务A对表1加了写锁,则:
- 事务A可以对表1进行查询和修改操作;其它事务对表1既不能读也不能写,直至事务A释放写锁。
- 其它事务不能对表1加任何锁,直至事务A释放写锁。
- 假设事务A对表1加了写锁,则:
锁算法
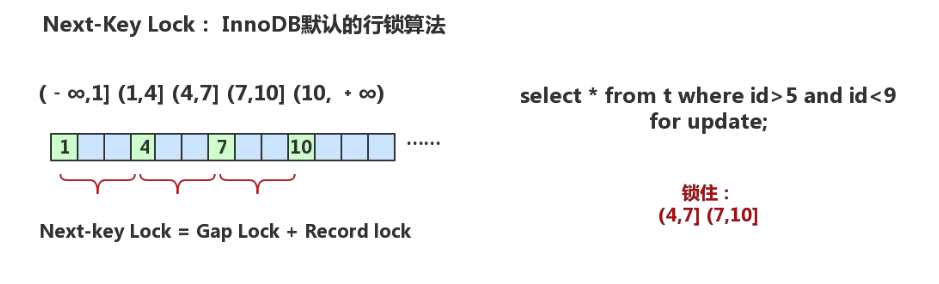
行锁算法:
①Record Lock:记录锁,单个行记录上的锁。即锁住具体的索引项,当SQL执行按照唯一性索引进行数据的检索时,查询条件等值匹配且查询的数据存在,这时SQL语句加上的锁即为记录锁。
1
select * from table where id = 1 FOR UPDATE; # 排它锁的记录锁算法
②Gap Lock:间隙锁,锁定一个范围,但不包含记录本身。当SQL执行按照索引进行数据的范围检索时,对于查询条件范围不存在的数据会加上间隙锁,间隙锁只在隔离级别为Repeatable Read存在。
- 间隙锁的目的是为了防止幻读,其主要通过两个方面实现这个目的:
- 防止间隙内有新数据被插入。
- 防止已存在的数据,更新成间隙内的数据。
1
select * FROM table where id > 1 and id < 100 FOR UPDATE; #排它锁的间隙锁算法
③Next-Key Lock: 是行锁和间隙锁的组合,当InnoDB扫描索引记录的时候,会首先对索引记录加上行锁(Record Lock),再对索引记录两边的间隙加上间隙锁(Gap Lock)。加上间隙锁之后,其它事务就不能在这个间隙修改或者插入记录。
![]()
表锁算法:
①意向锁:是表锁的一种。意向锁分为意向共享锁和意向排它锁。意向锁是有数据引擎自己维护的,用户无法手动操作意向锁,在为数据行加共享/排他锁之前,InooDB会先获取该数据行所在在数据表的对应意向锁。 意向锁的作用是:如果另一个任务试图在该表级别上应用共享或排它锁,则受到由第一个任务控制的表级别意向锁的阻塞。第二个任务在锁定该表前不必检查各个页或行锁,而只需检查表上的意向锁。
意向共享锁(intention shared lock, IS):事务有意向对表中的某些行加共享锁(S锁)。
1
2# 事务要获取某些行的S锁,必须先获得表的IS锁。
select column from table ... LOCK IN SHARE MODE意向排他锁(intention exclusive lock, IX):事务有意向对表中的某些行加排他锁(X锁)。
1
2# 事务要获取某些行的X锁,必须先获得表的IX锁。
SELECT column FROM table ... FOR UPDATE;假如无意向锁,且有一张users表:InnoDB,Repeatable-Read:users(id PK,name):
id name 1 abc 2 def 3 hij ①事务A获取了某一行的排他锁,并未提交:
1
select * from users WHERE id = 2 for update;
②事务B想要获取users表的共享锁:
1
lock table users read;
因为共享锁与排他锁互斥,所以事务B在视图对users表加共享锁的时候,必须保证:
- 当前没有其他事务持有users表的排他锁。
- 当前没有其他事务持有users表中任意一行的排他锁。
为了检测是否满足第二个条件,事务B必须在确保users表不存在任何排他锁的前提下,去检测表中的每一行是否存在排他锁。很明显这是一个效率很差的做法,但是有了意向锁之后,情况就不一样了。
假如有意向锁:
①事务A获取了某一行的排他锁,并未提交:
1
select * from users WHERE id = 2 for update;
- 此时users表存在两把锁:users表上的意向排他锁与id为2的数据行上的排他锁。
②事务B想要获取users表的共享锁:
1
lock table users read;
- 此时事务B检测事务A持有users表的意向排他锁,就可以得知事务A必然持有该表中某些数据行的排他锁,那么事务B对users表的加锁请求就会被排斥(阻塞),而无需去检测表中的每一行数据是否存在排他锁。
**意向锁不会与行级的共享/排他锁互斥,即意向锁并不会影响到多个事务对不同数据行加排他锁时的并发性(不然直接用普通的表锁就行了)。 **
①事务A获取了某一行的排他锁,并未提交:
1
select * from users WHERE id = 2 for update;
- 此时事务A获取了users表上的意向排他锁和id为2的数据行上的排他锁。
②事务B想要获取users表的共享锁:
1
lock table users read;
- 此时事务B检测事务A持有users表的意向排他锁,就可以得知事务A必然持有该表中某些数据行的排他锁,那么事务B对users表的加锁请求就会被排斥(阻塞)。
③最后事务C也想获取users表中某一行的排他锁:
1
select * from users WHERE id = 3 for update;
- 事务C申请users表的意向排他锁并检测到事务A持有users表的意向排他锁。因为意向锁之间并不互斥,所以事务C获取到了users表的意向排他锁。因为id为3的数据行上不存在任何排他锁,最终事务C成功获取到了该数据行上的排他锁。
总结:
- InnoDB支持多粒度锁,特定场景下,行级锁可以与表级锁共存。
- 意向锁之间互不排斥,但除了IS(意向共享锁)与S(表级别的共享锁)兼容外,意向锁会与表级别的共享锁/排他锁互斥。
- IX,IS是表级锁,不会和行级的X,S锁发生冲突。只会和表级的X,S发生冲突。
- 意向锁在保证并发性的前提下,实现了行锁和表锁共存且满足事务隔离性的要求。
②自增锁:是MySQL一种特殊的锁,如果表中存在自增字段,MySQL便会自动维护一个自增锁。
2、测试MyISAM锁机制
MyISAM执行引擎只支持表锁,并且有两种实现方式: 共享读锁和独占写锁。
测试表级写锁
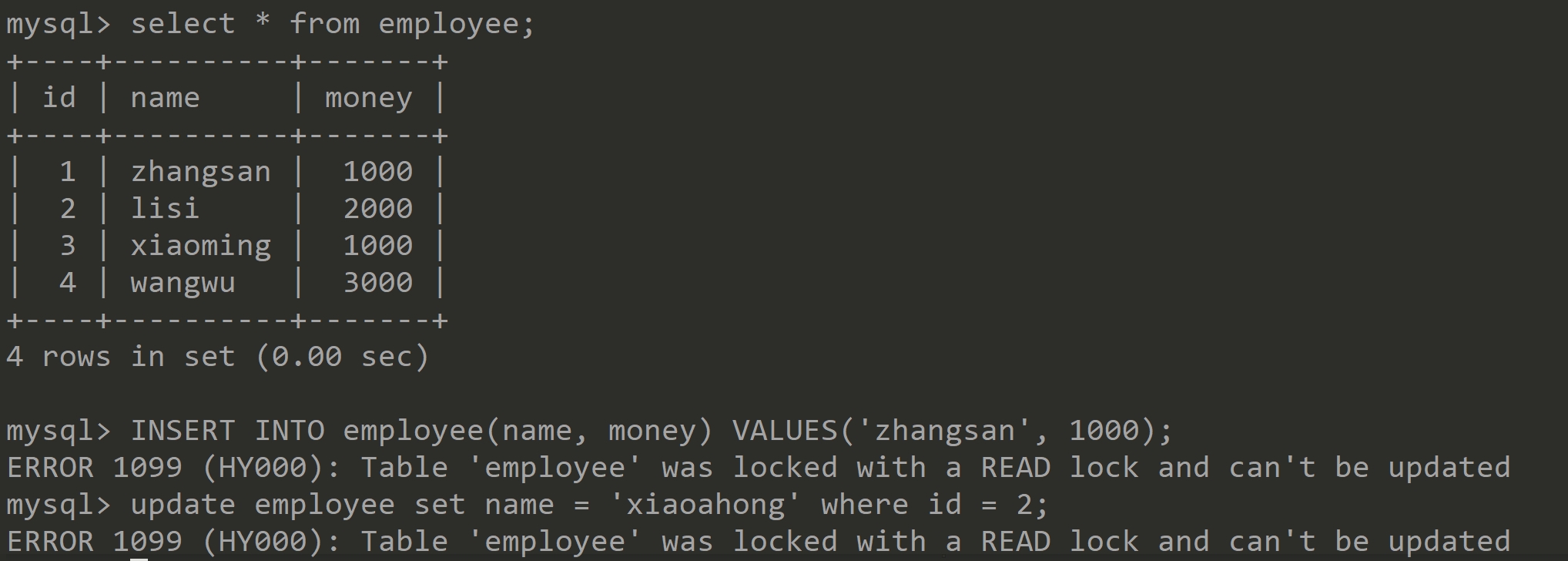
①首先创建一个测试表employee,这里要指定存储引擎为MyISAM,并插入两条测试数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21mysql> CREATE TABLE IF NOT EXISTS employee (
-> id INT PRIMARY KEY auto_increment,
-> name VARCHAR(40),
-> money INT
-> )ENGINE MyISAM;
Query OK, 0 rows affected (0.07 sec)
mysql> INSERT INTO employee(name, money) VALUES('zhangsan', 1000);
Query OK, 1 row affected (0.01 sec)
mysql> INSERT INTO employee(name, money) VALUES('lisi', 2000);
Query OK, 1 row affected (0.00 sec)
mysql> select * from employee;
+----+----------+-------+
| id | name | money |
+----+----------+-------+
| 1 | zhangsan | 1000 |
| 2 | lisi | 2000 |
+----+----------+-------+
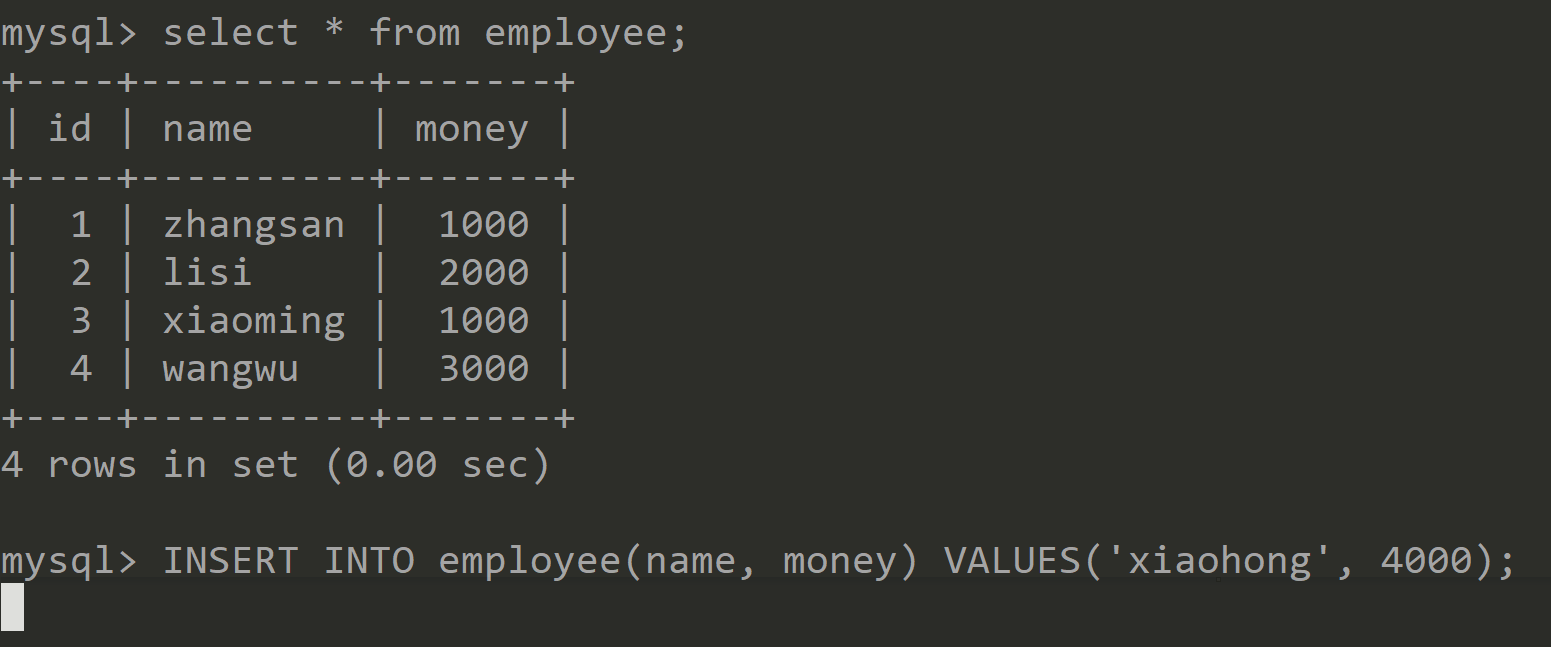
2 rows in set (0.00 sec)②开启另一个Session,并在两个Session中依次进行如下操作:
Session1 Session2 加表级别的写锁 ![]()
进行查询、插入或更新数据,都可以执行成功 ![]()
进行查询、插入或更新数据,可以发现都会处于等待状态 ![]()
释放写锁 ![]()
写锁释放后,插入数据操作完成 ![]()
结论:当一个线程获取到表级写锁后,只能由该线程对表进行读写操作,别的线程必须等待该线程释放锁以后才能操作。
测试表级读锁
开启两个Session,并在两个Session中依次进行如下操作:
Session1 Session2 加表级别的读锁 ![]()
进行插入、更新数据,发现都会报错,只能查询数据 ![]()
进行插入、更新数据,程序都会进入等待状态,只能查询数据 ![]()
释放读锁 ![]()
读锁释放后,插入数据操作完成 ![]()
结论:当一个线程获取到表级读锁后,该线程只能读取数据不能修改数据,其它线程也只能加读锁,不能加写锁。







3、测试InnoDB锁机制
InnoDB执行引擎除了同时支持表锁和行锁,还支持间隙锁等,并且有两种实现方式: 共享读锁和独占写锁。
测试使用非索引查询,直接就是使用的表级锁:
①首先创建一个测试表user,这里要指定存储引擎为InnoDB,并插入两条测试数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21mysql> CREATE TABLE IF NOT EXISTS user (
-> id INT PRIMARY KEY auto_increment,
-> name VARCHAR(40),
-> money INT
-> )ENGINE INNODB;
Query OK, 0 rows affected (0.14 sec)
mysql> INSERT INTO user(name, money) VALUES('zhangsan', 1000);
Query OK, 1 row affected (0.01 sec)
mysql> INSERT INTO user(name, money) VALUES('lisi', 2000);
Query OK, 1 row affected (0.04 sec)
mysql> select * from user;
+----+----------+-------+
| id | name | money |
+----+----------+-------+
| 1 | zhangsan | 1000 |
| 2 | lisi | 2000 |
+----+----------+-------+
2 rows in set (0.00 sec)②开启两个Session,并在两个Session中依次进行如下操作:
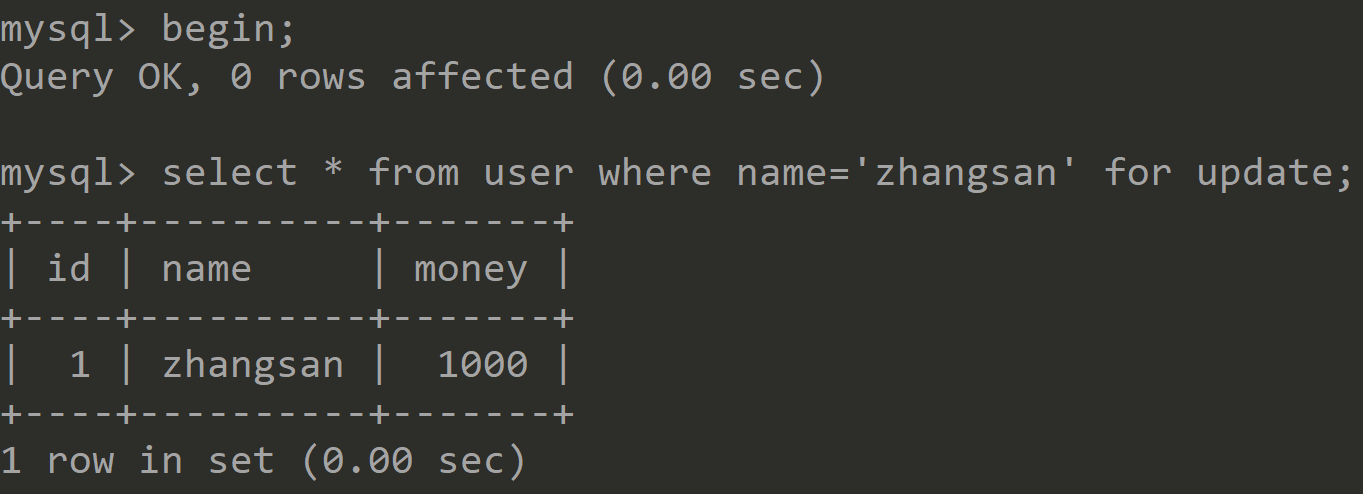
Session1 Session2 开启事务,使用非索引字段查询,并显式地添加写锁 ![]()
执行更新语句,上面加锁的是id=1的数据行,下面更新的是id=2的数据行,会发现程序也会进入等待状态 ![]()
提交事务,此时写锁释放 ![]()
更新语句执行成功 ![]()
测试使用索引查询,使用的是行锁(建议使用数据量大的表进行测试,因为是否执行索引还得看MySQL的执行计划,对于一些小表的操作,可能就直接使用全表扫描):
开启两个Session,并在两个Session中依次进行如下操作:
Session1 Session2 开启事务,使用索引字段查询,并显式地添加写锁 ![]()
可以成功更新其它数据行 ![]()
测试普通索引的间隙锁:
①新增一个字段num,并将num添加为普通索引,修改之前的数据使得num之间的值存在间隙。
![]()
![]()
![]()
②开启两个Session,并在两个Session中依次进行如下操作:
Session1 Session2 开启事务,并执行下面操作 ![]()
依次执行以下新增记录语句 ![]()
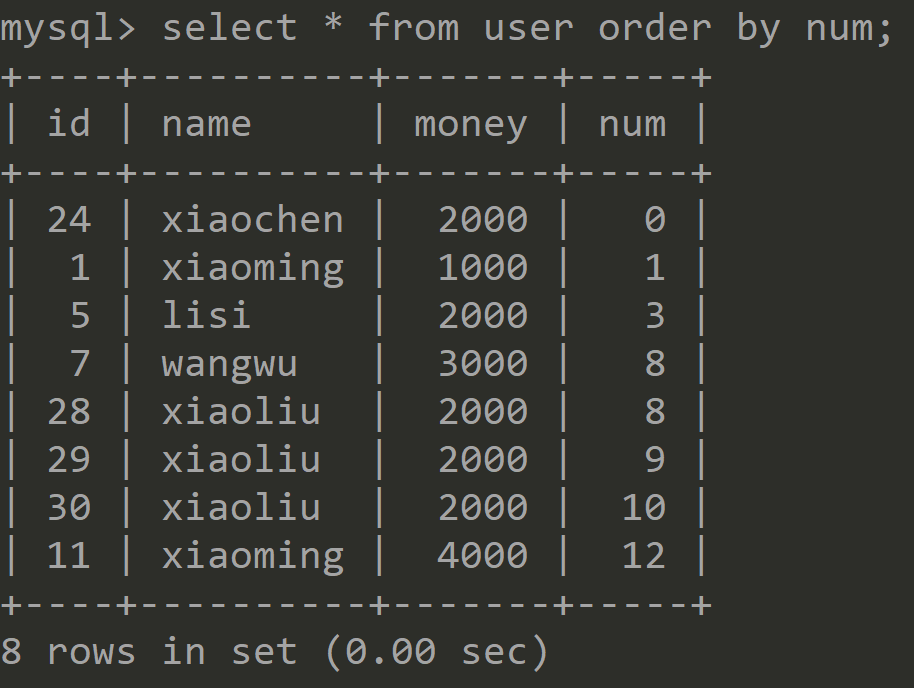
以num字段升序打印表中所有记录 ![]()
根据索引的有序性,而普通索引是可以出现重复值,当Session1查询的时候只出现一条数据num=3, 为了防止第二次查询的时候出现幻读,也就是出现两条或者更多num=3这样查询条件的数据,所以理论上会给(1,3]U[3,8)区间加上锁,也就是能再插入num=1或num=8的数据(两者不在范围内),但从打印结果发现Session却不可以插入num=1的记录,这是为什么呢?
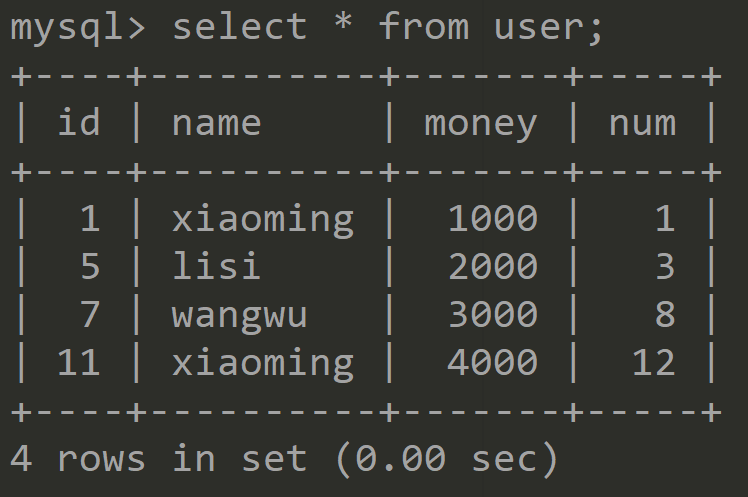
③为了更好理解,先把user表数据还原成原始数据。
![]()
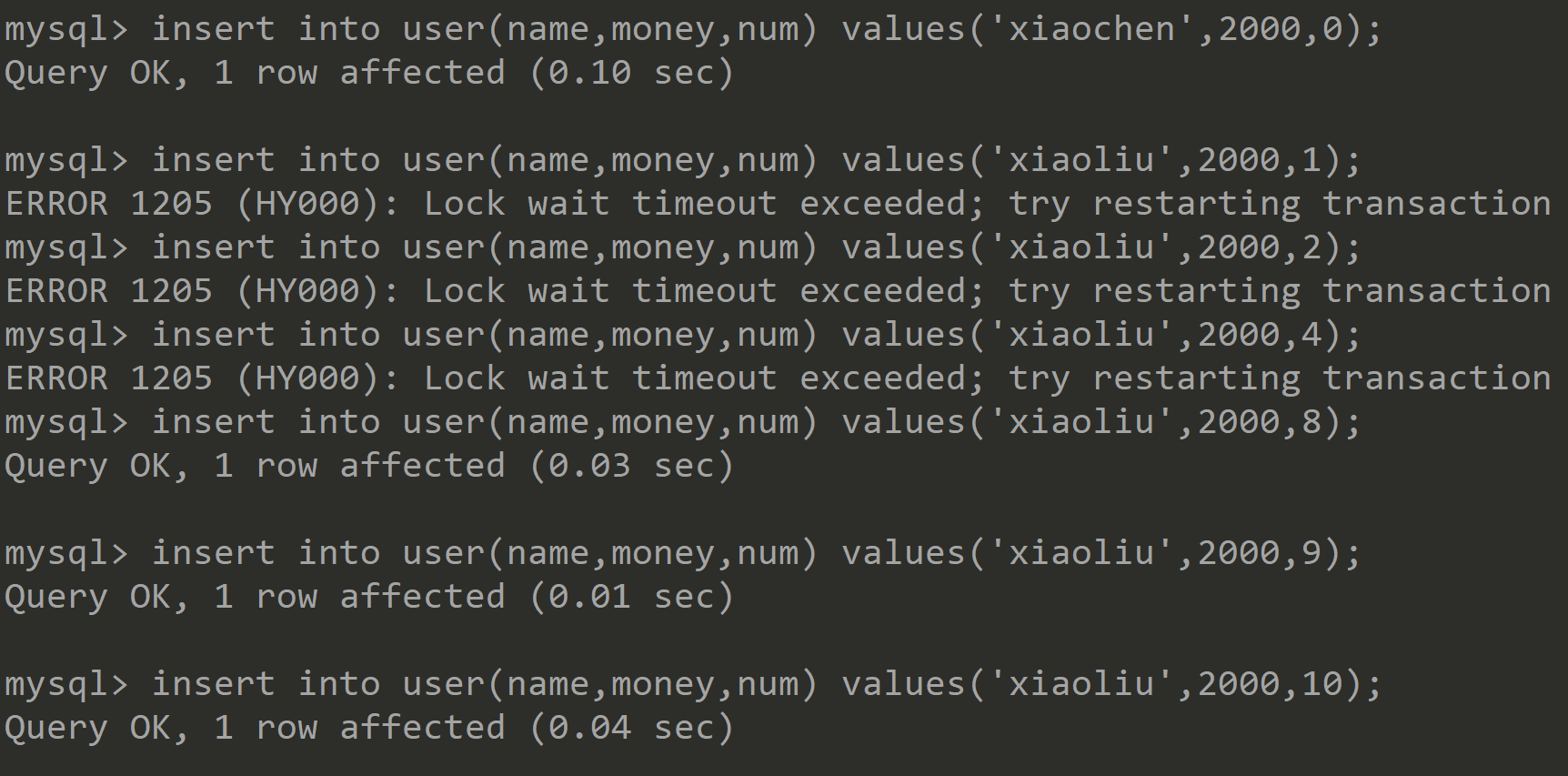
④接着还是开启两个Session,并在两个Session中依次进行如下操作:
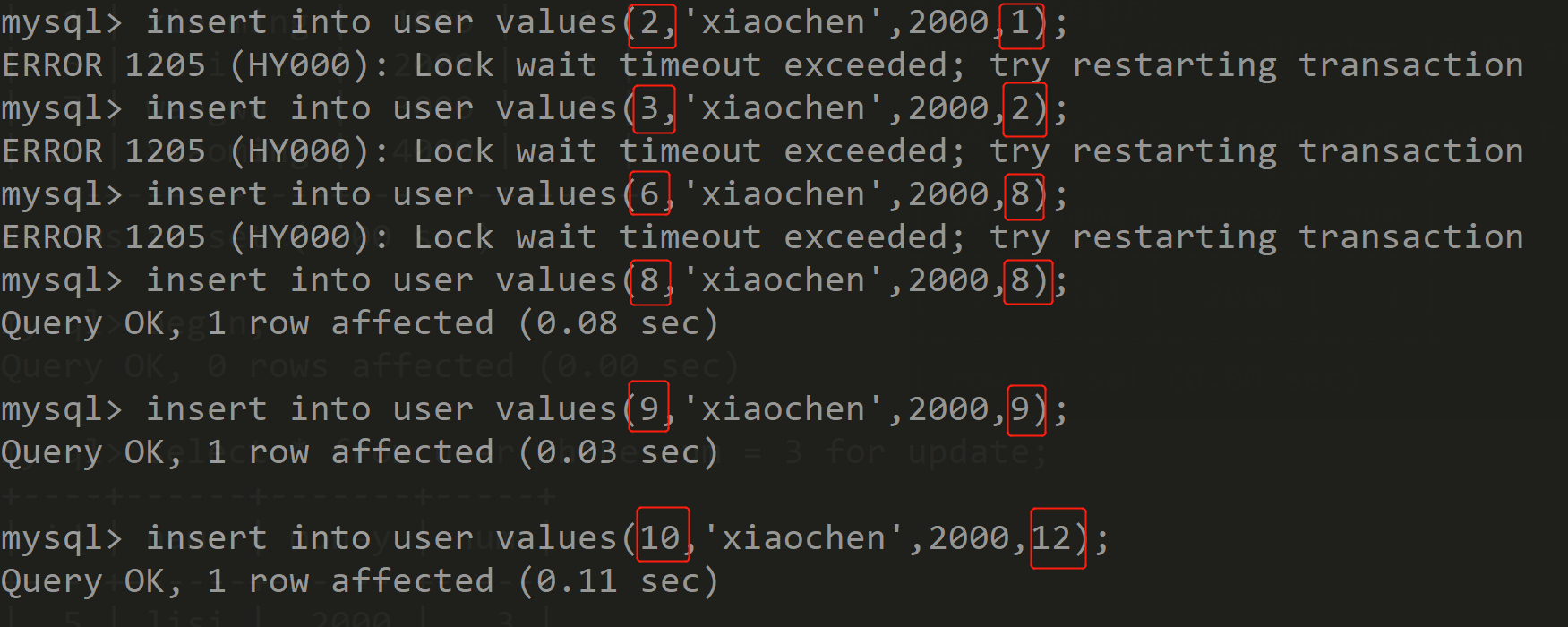
Session1 Session2 开启事务,并执行下面操作 ![]()
依次执行以下新增记录语句 ![]()
执行以下更新记录语句 ![]()
可以发现添加id=6,num=8的记录被阻塞而添加id=8,num=8的记录成功,并且将id=11,num=12的记录改成id=11,num=5也被阻塞。原因如下图,可以得出结论:在普通索引跟唯一索引中,数据间隙的分析,数据行是优先根据普通索引排序,再根据唯一索引排序,所以由于添加的id=6,num=8在num=(3, 8)的区间里,所以会被阻塞;而添加的id=8,num=8则是在num=(8, 12)区间里,所以不会被阻塞; 修改的语句相当于在num=(3, 8)的区间里插入一条数据,所以也被阻塞了:
![]()
测试唯一索引是否存在间隙锁:
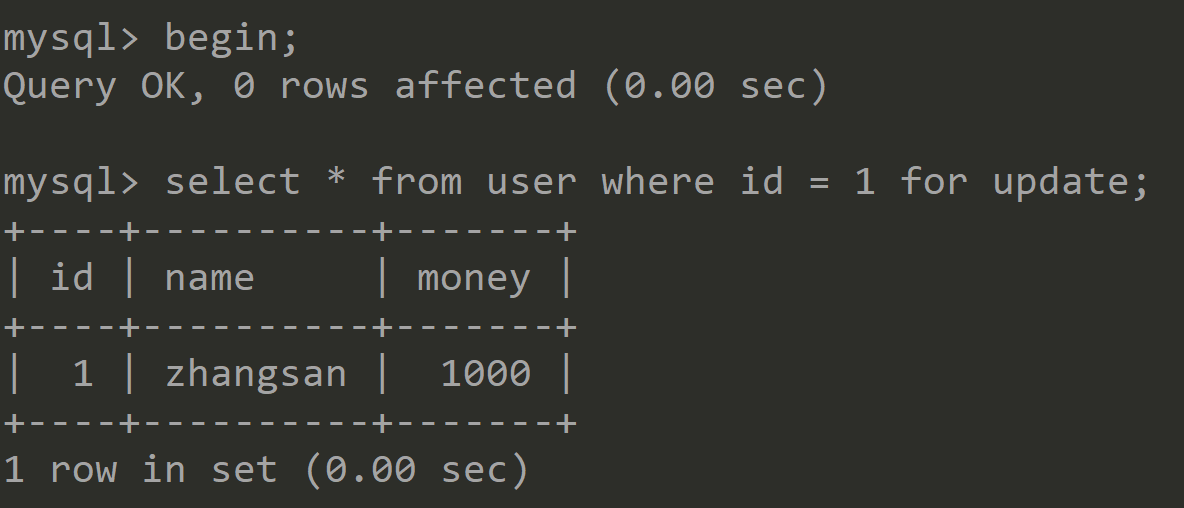
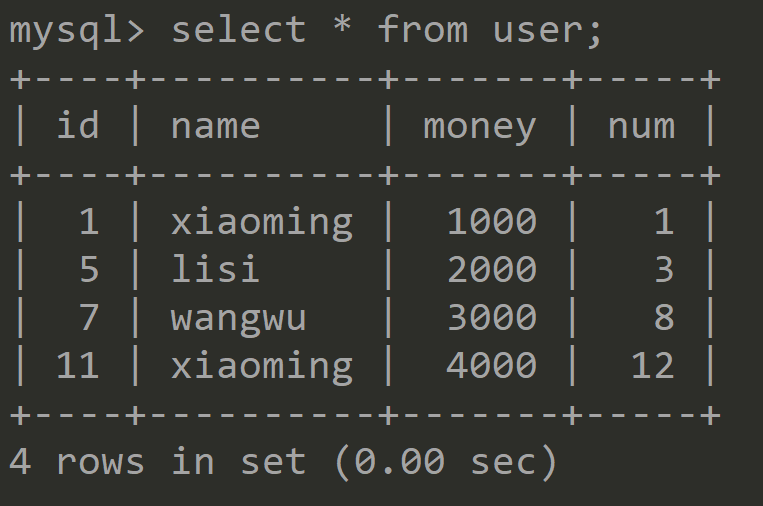
①初始化user表数据如下:
![]()
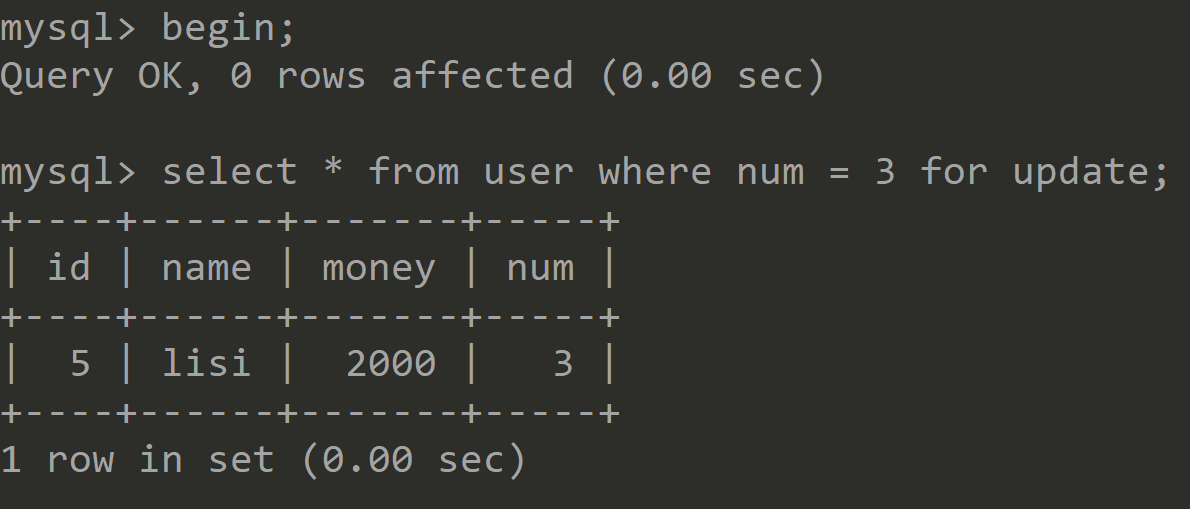
②开启两个Session,并在两个Session中依次进行如下操作:
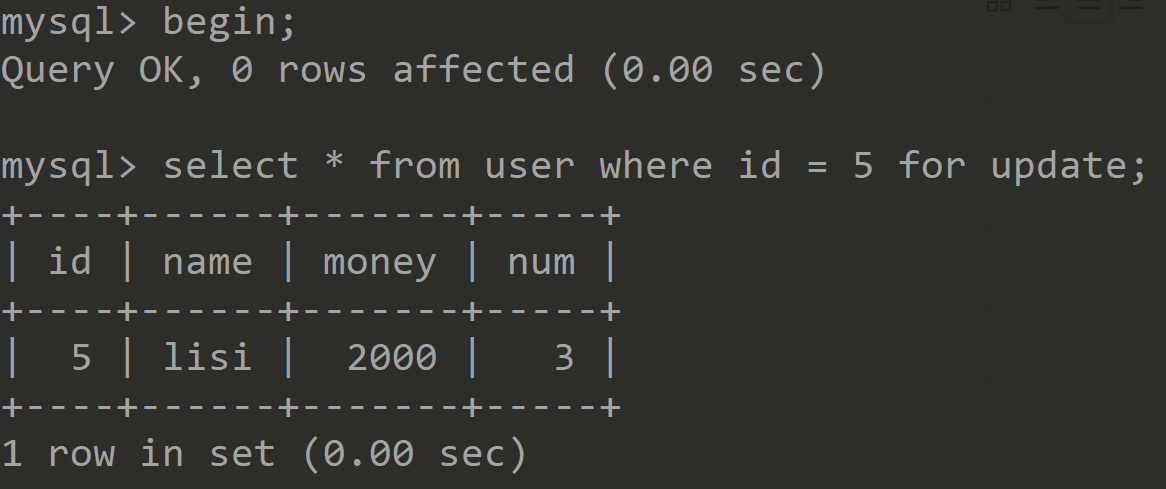
Session1 Session2 开启事务,并执行下面操作 ![]()
依次执行以下插入记录语句 ![]()
结论:由于主键是唯一索引,而且是只使用一个索引查询,并且只锁定一条记录,所以以上的例子,只会对id=5的数据加上记录锁,而不会产生间隙锁。







参考链接: