ClickHouse基础
- ClickHouse是俄罗斯的Yandex于2016年开源的列式存储数据库(DBMS),使用C++语言编写,主要用于在线分析处理查询(OLAP),能够使用SQL查询实时生成分析数据报告。
1、ClickHouse的特点
1.1 列式存储
以下面的表为例:
![]()

采用行式存储时,数据在磁盘上的组织结构为:
![]()
好处是想查某个人所有的属性时,可以通过一次磁盘查找加顺序读取就可以。但是当想查所有人的年龄时,需要不停的查找,或者全表扫描才行,遍历的很多数据都是不需要的。
采用列式存储时,数据在磁盘上的组织结构为:
![]()
这时想查所有人的年龄只需把年龄那一列拿出来就可以了。
列式储存的好处:
- 对于列的聚合,计数,求和等统计操作原因优于行式存储。
- 由于某一列的数据类型都是相同的,针对于数据存储更容易进行数据压缩,每一列选择更优的数据压缩算法,大大提高了数据的压缩比重。
- 由于数据压缩比更好,一方面节省了磁盘空间,另一方面对于cache也有了更大的发挥空间。


1.2 DBMS的功能
- 几乎覆盖了标准SQL的大部分语法,包括DDL和DML,以及配套的各种函数,用户管理及权限管理,数据的备份与恢复。
1.3 多样化引擎
- ClickHouse和MySQL类似,把表级的存储引擎插件化,根据表的不同需求可以设定不同的存储引擎。目前包括合并树、日志、接口和其他四大类20多种引擎。
1.4 高吞吐写入能力
- ClickHouse采用类LSM Tree的结构,数据写入后定期在后台Compaction。通过类LSM tree的结构,ClickHouse在数据导入时全部是顺序append写,写入后数据段不可更改,在后台compaction时也是多个段merge sort后顺序写回磁盘。顺序写的特性,充分利用了磁盘的吞吐能力,即便在HDD上也有着优异的写入性能。
- 官方公开benchmark测试显示能够达到50MB-200MB/s的写入吞吐能力,按照每行100Byte估算,大约相当于50W-200W条/s的写入速度。
1.5 数据分区与线程级并行
- ClickHouse将数据划分为多个partition,每个partition再进一步划分为多个index granularity(索引粒度),然后通过多个CPU核心分别处理其中的一部分来实现并行数据处理。在这种设计下,单条Query就能利用整机所有CPU。极致的并行处理能力,极大的降低了查询延时。
- 所以,ClickHouse即使对于大量数据的查询也能够化整为零平行处理。但是有一个弊端就是对于单条查询使用多cpu,就不利于同时并发多条查询。所以对于高qps的查询业务,ClickHouse并不是强项。
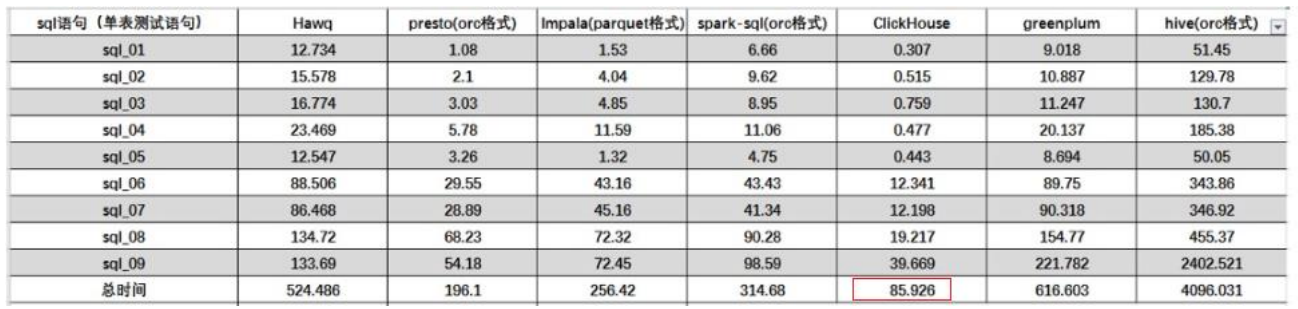
1.6 性能对比
单表查询。
![]()
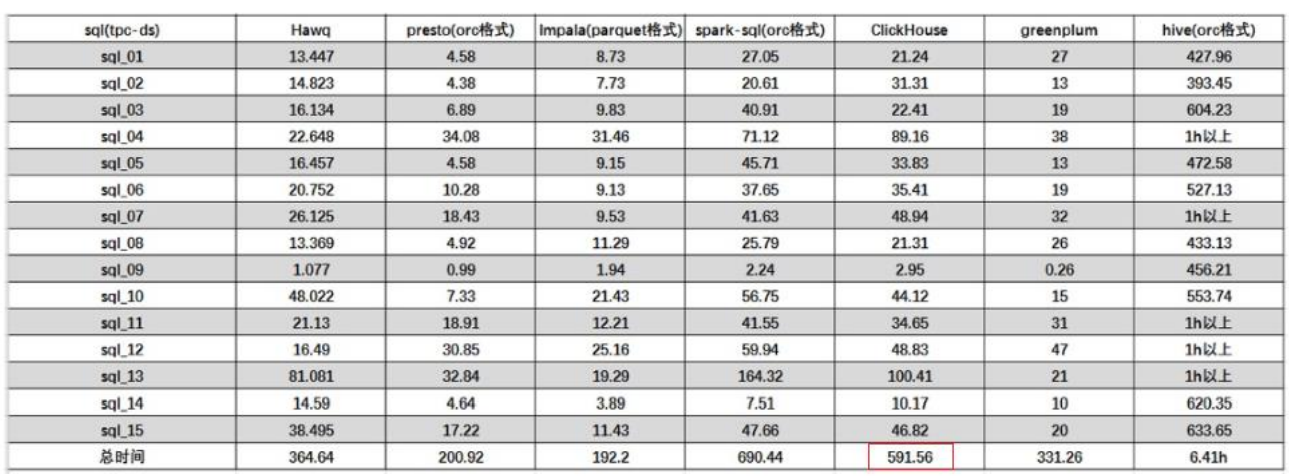
关联查询。
![]()
结论:ClickHouse像很多OLAP数据库一样,单表查询速度优于关联查询,而且ClickHouse的两者差距更为明显。
2、docker安装clickhouse
1 | # 拉取clickhouse-server镜像 |
3、数据类型
- 官网
https://clickhouse.com/docs/zh/sql-reference/data-types/。
3.1 整型
- 固定长度的整型,包括有符号整型或无符号整型。创建表时,可以为整数设置类型参数 (例如.
TINYINT(8),SMALLINT(16),INT(32),BIGINT(64)),但ClickHouse会忽略它们。 - 有符号整型范围:
Int8— [-128 : 127]Int16— [-32768 : 32767]Int32— [-2147483648 : 2147483647]Int64— [-9223372036854775808 : 9223372036854775807]Int128— [-170141183460469231731687303715884105728 : 170141183460469231731687303715884105727]Int256— [-57896044618658097711785492504343953926634992332820282019728792003956564819968 : 57896044618658097711785492504343953926634992332820282019728792003956564819967]
- 别名:
Int8—TINYINT,BOOL,BOOLEAN,INT1.Int16—SMALLINT,INT2.Int32—INT,INT4,INTEGER.Int64—BIGINT.
- 无符号整型范围:
UInt8— [0 : 255]UInt16— [0 : 65535]UInt32— [0 : 4294967295]UInt64— [0 : 18446744073709551615]UInt128— [0 : 340282366920938463463374607431768211455]UInt256— [0 : 115792089237316195423570985008687907853269984665640564039457584007913129639935]
- 使用场景:个数、数量、也可以存储型id。
3.2 浮点型
类型与以下C语言中类型是相同的:
Float32-floatFloat64-double
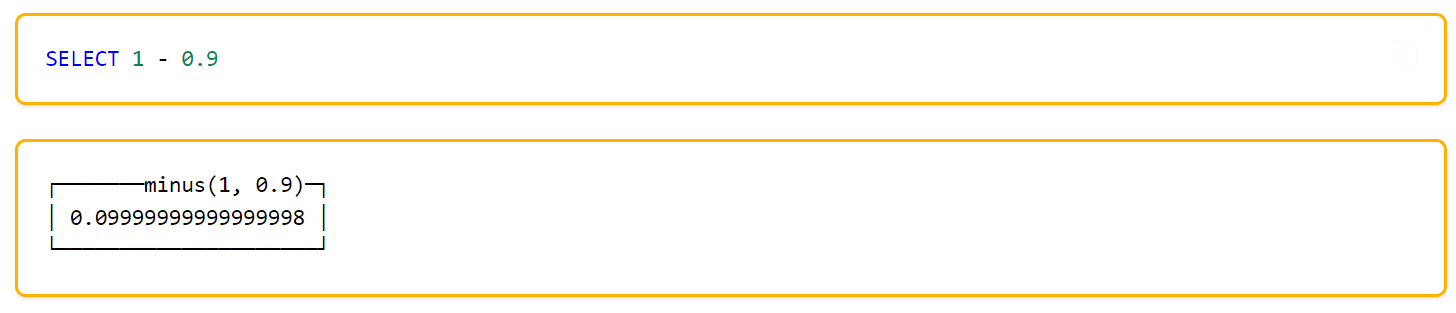
建议尽可能以整数形式存储数据。例如,将固定精度的数字转换为整数值,如时间用毫秒为单位表示,因为浮点型进行计算时可能引起四舍五入的误差。
![]()
- 计算的结果取决于计算方法(计算机系统的处理器类型和体系结构)。
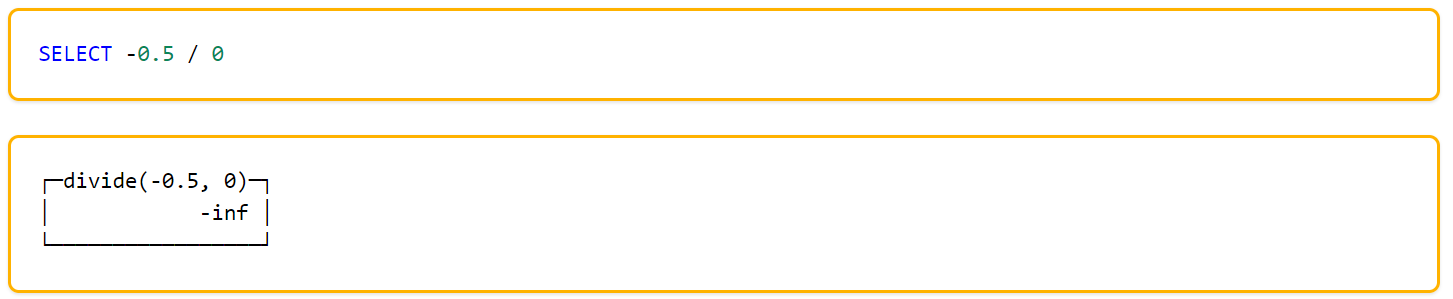
- 浮点计算结果可能是诸如无穷大(
INF)和«非数字»(NaN)。对浮点数计算的时候应该考虑到这点。 - 当一行行阅读浮点数的时候,浮点数的结果可能不是机器最近显示的数值。
与标准SQL相比,ClickHouse支持以下类别的浮点数:
Inf– 正无穷![]()
-Inf– 负无穷![]()
NaN– 非数字![]()
使用场景:一般数据值比较小,不涉及大量的统计计算,精度要求不高的时候。比如保存商品的重量。


3.3 布尔型
- 没有单独的类型来存储布尔值。可以使用UInt8类型,取值限制为0或1。
3.4 Decimal型
有符号的定点数,可在加、减和乘法运算过程中保持精度。对于除法,最低有效数字会被丢弃(不舍入)。
s标识小数位
- Decimal32(s)相当于Decimal(9-s,s)
- Decimal64(s)相当于Decimal(18-s,s)
- Decimal128(s)相当于Decimal(38-s,s)
使用场景:一般金额字段、汇率、利率等字段为了保证小数点精度,都使用Decimal进行存储。
3.5 字符串
- String
- 字符串可以任意长度的。它可以包含任意的字节集,包含空字节。
- FixedString(N)
- 固定长度N的字符串,N必须是严格的正自然数。当服务端读取长度小于N的字符串时候,通过在字符串末尾添加空字节来达到N字节长度。当服务端读取长度大于N的字符串时候,将返回错误消息。 与String相比,极少会使用FixedString,因为使用起来不是很方便。
- 使用场景:名称、文字描述、字符型编码。 固定长度的可以保存一些定长的内容,比如一些编码,性别等但是考虑到一定的变化风险,带来收益不够明显,所以定长字符串使用意义有限。
3.6 枚举类型
包括
Enum8和Enum16类型。Enum保存'string'= integer的对应关系。在ClickHouse中,尽管用户使用的是字符串常量,但所有含有Enum数据类型的操作都是按照包含整数的值来执行。这在性能方面比使用String数据类型更有效。Enum8用'String'= Int8对描述。Enum16用'String'= Int16对描述。
举例:
创建一个带有一个枚举
Enum8('hello' = 1, 'world' = 2)类型的列:1
2
3
4
5CREATE TABLE t_enum
(
x Enum8('hello' = 1, 'world' = 2)
)
ENGINE = TinyLog这个
x列只能存储类型定义中列出的值:'hello'或'world'。如果尝试保存任何其他值,ClickHouse抛出异常。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15:) INSERT INTO t_enum VALUES ('hello'), ('world'), ('hello')
INSERT INTO t_enum VALUES
Ok.
3 rows in set. Elapsed: 0.002 sec.
:) insert into t_enum values('a')
INSERT INTO t_enum VALUES
Exception on client:
Code: 49. DB::Exception: Unknown element 'a' for type Enum8('hello' = 1, 'world' = 2)当从表中查询数据时,ClickHouse从
Enum中输出字符串值。1
2
3
4
5
6
7SELECT * FROM t_enum
┌─x─────┐
│ hello │
│ world │
│ hello │
└───────┘如果需要看到对应行的数值,则必须将
Enum值转换为整数类型。1
2
3
4
5
6
7SELECT CAST(x, 'Int8') FROM t_enum
┌─CAST(x, 'Int8')─┐
│ 1 │
│ 2 │
│ 1 │
└─────────────────┘在查询中创建枚举值,还需要使用
CAST。1
2
3
4
5SELECT toTypeName(CAST('a', 'Enum8(\'a\' = 1, \'b\' = 2)'))
┌─toTypeName(CAST('a', 'Enum8(\'a\' = 1, \'b\' = 2)'))─┐
│ Enum8('a' = 1, 'b' = 2) │
└──────────────────────────────────────────────────────┘
使用场景:对一些状态、类型的字段算是一种空间优化,也算是一种数据约束。但是实际使用中往往因为一些数据内容的变化增加一定的维护成本,甚至是数据丢失问题。所以谨慎使用。
3.7 时间类型
目前ClickHouse有三种时间类型:
- Date接受年-月-日的字符串,比如:2019-12-16
- Datetime接受年-月-日 时:分:秒的字符串,比如2019-12-16 20:50:10
- Datetime64接受年-月-日 时:分:秒.亚秒的字符串,比如2019-12-16 20:50:10.66
日期类型用两个字节存储,表示从1970-01-01到当前的日期值。
3.8 数组
Array(T):由T类型元素组成的数组。T可以是任意类型,包含数组类型。但不推荐使用多维数组,ClickHouse对多维数组的支持有限。例如,不能在MergeTree表中存储多维数组。
创建数组方式:
使用array函数
1
2
3
4
5
6
7
8
9
10
11
12
1391f7f636ff6f :) select array(1, 2) as x, toTypeName(x);
SELECT
[1, 2] AS x,
toTypeName(x)
Query id: c7fea243-195e-45fc-809a-4ebc0004caf4
┌─x─────┬─toTypeName(array(1, 2))─┐
│ [1,2] │ Array(UInt8) │
└───────┴─────────────────────────┘
1 rows in set. Elapsed: 0.015 sec.使用方括号
1
2
3
4
5
6
7
8
9
10
11
12
1391f7f636ff6f :) select [1, 2] as x, toTypeName(x);
SELECT
[1, 2] AS x,
toTypeName(x)
Query id: 9fe8c010-ad7c-45d5-99f1-1302fb50e24a
┌─x─────┬─toTypeName([1, 2])─┐
│ [1,2] │ Array(UInt8) │
└───────┴────────────────────┘
1 rows in set. Elapsed: 0.002 sec.
4、表引擎
4.1 表引擎的使用
- 表引擎决定了如何存储表的数据。包括:
- 数据的存储方式和位置,写到哪里以及从哪里读取数据。
- 支持哪些查询以及如何支持。
- 并发数据访问。
- 索引的使用(如果存在)。
- 是否可以执行多线程请求。
- 数据复制参数。
- 表引擎的使用方式就是必须显式在创建表时定义该表使用的引擎,以及引擎使用的相关参数。
- 特别注意:引擎的名称大小写敏感。
4.2 TinyLog
以列文件的形式保存在磁盘上,不支持索引,没有并发控制。一般保存少量数据的小表,生产环境上作用有限。可以用于平时练习测试用。
1
create table t_tinylog ( id String, name String) engine=TinyLog;
4.3 Memory
- 内存引擎:数据以未压缩的原始形式直接保存在内存当中,服务器重启数据就会消失。读写操作不会相互阻塞,不支持索引。简单查询下有非常非常高的性能表现(超过10G/s)。
- 一般用到它的地方不多,除了用来测试,就是在需要非常高的性能,同时数据量又不太大(上限大概1亿行)的场景。
4.4 MergeTree
官方文档:
https://clickhouse.com/docs/en/engines/table-engines/mergetree-family/mergetreeClickHouse中最强大的表引擎当属MergeTree(合并树)引擎及该系列(*MergeTree) 中的其他引擎,支持索引和分区,地位可以相当于innodb之于Mysql。而且基于MergeTree,还衍生除了很多小弟,也是非常有特色的引擎。
建表语句:
1
2
3
4
5
6
7
8
9create table t_order_mt (
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime
) engine =MergeTree
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id,sku_id);插入数据:
1
2
3
4
5
6
7insert into t_order_mt values
(101,'sku_001',1000.00,'2020-06-01 12:00:00'),
(102,'sku_002',2000.00,'2020-06-01 11:00:00'),
(102,'sku_004',2500.00,'2020-06-01 12:00:00'),
(102,'sku_002',2000.00,'2020-06-01 13:00:00'),
(102,'sku_002',12000.00,'2020-06-01 13:00:00'),
(102,'sku_002',600.00,'2020-06-02 12:00:00');查询数据:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
1991f7f636ff6f :) select * from t_order_mt;
SELECT *
FROM t_order_mt
Query id: 333ce647-6bbb-4ebe-a879-f2e4b083deda
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 102 │ sku_002 │ 600 │ 2020-06-02 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 101 │ sku_001 │ 1000 │ 2020-06-01 12:00:00 │
│ 102 │ sku_002 │ 2000 │ 2020-06-01 11:00:00 │
│ 102 │ sku_002 │ 2000 │ 2020-06-01 13:00:00 │
│ 102 │ sku_002 │ 12000 │ 2020-06-01 13:00:00 │
│ 102 │ sku_004 │ 2500 │ 2020-06-01 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
6 rows in set. Elapsed: 0.005 sec.- 主键可重复。
- 根据日期分区,2020-06-01、2020-06-02共两个分区。
- 分区内根据id和sku_id排序。
4.4.1 partition by分区(可选)
分区的目的主要是降低扫描的范围,优化查询速度。
如果不填,只会使用一个分区。
MergeTree是以列文件+索引文件+表定义文件组成的,但是如果设定了分区那么这些文件就会保存到不同的分区目录中。
分区后,面对涉及跨分区的查询统计,ClickHouse会以分区为单位并行处理。
1
2
3
4
5[root@centos7 ~]# docker exec -it clickhouse01 /bin/bash
root@91f7f636ff6f:/# cd /var/lib/clickhouse/
root@91f7f636ff6f:/var/lib/clickhouse# ls
access dictionaries_lib format_schemas metadata_dropped status tmp user_files uuid
data flags metadata preprocessed_configs store user_defined user_scriptsdata:数据存储的路径。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24root@91f7f636ff6f:/var/lib/clickhouse# cd data
root@91f7f636ff6f:/var/lib/clickhouse/data# ll
total 16
drwxr-x--- 4 clickhouse clickhouse 4096 Jul 17 12:56 ./
drwxr-xr-x 15 clickhouse clickhouse 4096 Jul 17 14:41 ../
drwxr-x--- 2 clickhouse clickhouse 4096 Jul 17 15:05 default/
drwxr-x--- 2 clickhouse clickhouse 4096 Jul 17 15:07 system/
root@91f7f636ff6f:/var/lib/clickhouse/data# cd default/
root@91f7f636ff6f:/var/lib/clickhouse/data/default# ll
total 12
drwxr-x--- 2 clickhouse clickhouse 4096 Jul 17 15:05 ./
drwxr-x--- 4 clickhouse clickhouse 4096 Jul 17 12:56 ../
lrwxrwxrwx 1 clickhouse clickhouse 67 Jul 17 15:05 t_order_mt -> /var/lib/clickhouse/store/33e/33eab85d-6dcd-48d8-b3ea-b85d6dcd08d8//
root@91f7f636ff6f:/var/lib/clickhouse/data/default# cd t_order_mt
# 20200601_1_1_0、20200602_2_2_0共两个分区目录
# 分区目录命名格式:PartitionId_MinBlockNum_MaxBlockNum_Level,分表代表分区值、最小分区块编号、最大分区块编号、合并层级
root@91f7f636ff6f:/var/lib/clickhouse/data/default/t_order_mt# ll
total 24
drwxr-x--- 5 clickhouse clickhouse 4096 Jul 17 15:07 ./
drwxr-x--- 3 clickhouse clickhouse 4096 Jul 17 15:05 ../
drwxr-x--- 2 clickhouse clickhouse 4096 Jul 17 15:07 20200601_1_1_0/
drwxr-x--- 2 clickhouse clickhouse 4096 Jul 17 15:07 20200602_2_2_0/
drwxr-x--- 2 clickhouse clickhouse 4096 Jul 17 15:05 detached/
-rw-r----- 1 clickhouse clickhouse 1 Jul 17 15:05 format_version.txt- PartitionId:数据分区规则由分区ID决定,分区ID由partition by分区键决定。根据分区键字段类型,ID生成规则可分为:
- 未定义分区键:没有定义partition by,默认生成一个目录名为all的数据分区,所有数据均存放在all目录下。
- 整型分区键:分区键为整型,直接用该整型值的字符串形式作为分区ID。
- 日期类分区键:分区键为日期类型,或者可以转换为日期类型。
- 其他类型分区键:String、Float类型等,通过128位的Hash算法取其Hash值作为分区ID。
- MinBlockNum:最小分区块编号,自增类型,从1开始向上递增。每产生一个新的目录分区就向上递增一个数字。
- MaxBlockNum:最大分区块编号,新创建的分区MinBlockNum等于MaxBlockNum的编号。
- Level:合并的层级,被合并的次数。合并次数越多,层级值越大。
1
2
3
4
5
6
7
8
9
10
11
12
13
14root@91f7f636ff6f:/var/lib/clickhouse/data/default/t_order_mt# cd 20200601_1_1_0/
root@91f7f636ff6f:/var/lib/clickhouse/data/default/t_order_mt/20200601_1_1_0# ll
total 44
drwxr-x--- 2 clickhouse clickhouse 4096 Jul 17 15:07 ./
drwxr-x--- 5 clickhouse clickhouse 4096 Jul 17 15:07 ../
-rw-r----- 1 clickhouse clickhouse 259 Jul 17 15:07 checksums.txt
-rw-r----- 1 clickhouse clickhouse 118 Jul 17 15:07 columns.txt
-rw-r----- 1 clickhouse clickhouse 1 Jul 17 15:07 count.txt
-rw-r----- 1 clickhouse clickhouse 189 Jul 17 15:07 data.bin
-rw-r----- 1 clickhouse clickhouse 144 Jul 17 15:07 data.mrk3
-rw-r----- 1 clickhouse clickhouse 10 Jul 17 15:07 default_compression_codec.txt
-rw-r----- 1 clickhouse clickhouse 8 Jul 17 15:07 minmax_create_time.idx
-rw-r----- 1 clickhouse clickhouse 4 Jul 17 15:07 partition.dat
-rw-r----- 1 clickhouse clickhouse 8 Jul 17 15:07 primary.idx- checksums.txt:校验文件,用校验各个文件的正确性。存放各个文件的size以及hash值。
- data.bin:数据文件。
- mrk文件:标记文件,标记文件在idx索引文件和bin数据文件之间起到了桥梁作用。以mrk2结尾的文件,表示该表启用了自适应索引间隔。
- count.txt:有几条数据。
- default_compression_codec.txt:默认压缩格式。
- columns.txt:列的信息。
- primary.idx:主键索引文件。
- partition.dat与minmax_[Column].idx:如果使用了分区键,则会额外生成这2个文件,均使用二进制存储。partition.dat保存当前分区下分区表达式最终生成的值;minmax索引用于记录当前分区下分区字段对应原始数据的最小值和最大值。以t_order_mt的20200601分区为例,partition.dat中的值为20200601,minmax索引中保存的值为2020-06-01 12:00:00 2020-06-01 13:00:00。
- PartitionId:数据分区规则由分区ID决定,分区ID由partition by分区键决定。根据分区键字段类型,ID生成规则可分为:
metadata:表结构信息。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29root@91f7f636ff6f:/var/lib/clickhouse# cd metadata
root@91f7f636ff6f:/var/lib/clickhouse/metadata# ll
total 40
drwxr-x--- 4 clickhouse clickhouse 4096 Jul 17 12:56 ./
drwxr-xr-x 15 clickhouse clickhouse 4096 Jul 17 14:41 ../
lrwxrwxrwx 1 clickhouse clickhouse 67 Jul 17 12:56 default -> /var/lib/clickhouse/store/35c/35c1f5fc-6ffb-46b5-b5c1-f5fc6ffb66b5//
-rw-r----- 1 clickhouse clickhouse 78 Jul 17 12:56 default.sql
drwxr-x--- 2 clickhouse clickhouse 4096 Jul 17 12:56 information_schema/
drwxr-x--- 2 clickhouse clickhouse 4096 Jul 17 12:56 INFORMATION_SCHEMA/
-rw-r----- 1 clickhouse clickhouse 51 Jul 17 12:56 information_schema.sql
-rw-r----- 1 clickhouse clickhouse 51 Jul 17 12:56 INFORMATION_SCHEMA.sql
lrwxrwxrwx 1 clickhouse clickhouse 67 Jul 17 12:56 system -> /var/lib/clickhouse/store/d71/d71cd763-f296-4023-971c-d763f2963023//
-rw-r----- 1 clickhouse clickhouse 78 Jul 17 12:56 system.sql
root@91f7f636ff6f:/var/lib/clickhouse/metadata# cd default
root@91f7f636ff6f:/var/lib/clickhouse/metadata/default# ls
t_order_mt.sql
root@91f7f636ff6f:/var/lib/clickhouse/metadata/default# cat t_order_mt.sql
ATTACH TABLE _ UUID '33eab85d-6dcd-48d8-b3ea-b85d6dcd08d8'
(
`id` UInt32,
`sku_id` String,
`total_amount` Decimal(16, 2),
`create_time` DateTime
)
ENGINE = MergeTree
PARTITION BY toYYYYMMDD(create_time)
PRIMARY KEY id
ORDER BY (id, sku_id)
SETTINGS index_granularity = 8192
数据写入与分区合并,任何一个批次的数据写入都会产生一个临时分区,不会纳入任何一个已有的分区。写入后的某个时刻(大概10-15分钟后),ClickHouse会自动执行合并操作(等不及也可以手动通过optimize执行),把临时分区的数据,合并到已有分区中。
1
optimize table xxxx final;
例如,再次执行上面的插入操作:
1
2
3
4
5
6
7insert into t_order_mt values
(101,'sku_001',1000.00,'2020-06-01 12:00:00'),
(102,'sku_002',2000.00,'2020-06-01 11:00:00'),
(102,'sku_004',2500.00,'2020-06-01 12:00:00'),
(102,'sku_002',2000.00,'2020-06-01 13:00:00'),
(102,'sku_002',12000.00,'2020-06-01 13:00:00'),
(102,'sku_002',600.00,'2020-06-02 12:00:00');查看数据并没有纳入任何分区:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
2991f7f636ff6f :) select * from t_order_mt;
SELECT *
FROM t_order_mt
Query id: 14f869c1-6a5b-47b3-9672-6015629b0a71
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 102 │ sku_002 │ 600 │ 2020-06-02 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 102 │ sku_002 │ 600 │ 2020-06-02 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 101 │ sku_001 │ 1000 │ 2020-06-01 12:00:00 │
│ 102 │ sku_002 │ 2000 │ 2020-06-01 11:00:00 │
│ 102 │ sku_002 │ 2000 │ 2020-06-01 13:00:00 │
│ 102 │ sku_002 │ 12000 │ 2020-06-01 13:00:00 │
│ 102 │ sku_004 │ 2500 │ 2020-06-01 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 101 │ sku_001 │ 1000 │ 2020-06-01 12:00:00 │
│ 102 │ sku_002 │ 2000 │ 2020-06-01 11:00:00 │
│ 102 │ sku_002 │ 2000 │ 2020-06-01 13:00:00 │
│ 102 │ sku_002 │ 12000 │ 2020-06-01 13:00:00 │
│ 102 │ sku_004 │ 2500 │ 2020-06-01 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
12 rows in set. Elapsed: 0.003 sec.查看
/var/lib/clickhouse/data/default/t_order_mt路径,发现多出两个目录20200601_3_3_0和20200602_4_4_0:1
2
3
4
5
6
7
8
9
10root@91f7f636ff6f:/var/lib/clickhouse/data/default/t_order_mt# ll
total 32
drwxr-x--- 7 clickhouse clickhouse 4096 Jul 17 15:59 ./
drwxr-x--- 3 clickhouse clickhouse 4096 Jul 17 15:05 ../
drwxr-x--- 2 clickhouse clickhouse 4096 Jul 17 15:07 20200601_1_1_0/
drwxr-x--- 2 clickhouse clickhouse 4096 Jul 17 15:59 20200601_3_3_0/
drwxr-x--- 2 clickhouse clickhouse 4096 Jul 17 15:07 20200602_2_2_0/
drwxr-x--- 2 clickhouse clickhouse 4096 Jul 17 15:59 20200602_4_4_0/
drwxr-x--- 2 clickhouse clickhouse 4096 Jul 17 15:05 detached/
-rw-r----- 1 clickhouse clickhouse 1 Jul 17 15:05 format_version.txt手动optimize之后再次查看上面目录:
1
2
3
4
5
6
7
8
991f7f636ff6f :) optimize table t_order_mt final;
OPTIMIZE TABLE t_order_mt FINAL
Query id: a8297d19-8d80-4793-8590-a8b220799f6e
Ok.
0 rows in set. Elapsed: 0.011 sec.1
2
3
4
5
6
7
8
9
10
11
12root@91f7f636ff6f:/var/lib/clickhouse/data/default/t_order_mt# ll
total 40
drwxr-x--- 9 clickhouse clickhouse 4096 Jul 17 16:03 ./
drwxr-x--- 3 clickhouse clickhouse 4096 Jul 17 15:05 ../
drwxr-x--- 2 clickhouse clickhouse 4096 Jul 17 15:07 20200601_1_1_0/
drwxr-x--- 2 clickhouse clickhouse 4096 Jul 17 16:03 20200601_1_3_1/
drwxr-x--- 2 clickhouse clickhouse 4096 Jul 17 15:59 20200601_3_3_0/
drwxr-x--- 2 clickhouse clickhouse 4096 Jul 17 15:07 20200602_2_2_0/
drwxr-x--- 2 clickhouse clickhouse 4096 Jul 17 16:03 20200602_2_4_1/
drwxr-x--- 2 clickhouse clickhouse 4096 Jul 17 15:59 20200602_4_4_0/
drwxr-x--- 2 clickhouse clickhouse 4096 Jul 17 15:05 detached/
-rw-r----- 1 clickhouse clickhouse 1 Jul 17 15:05 format_version.txt- 发现多了目录
20200601_1_3_1,其由目录20200601_1_1_0和20200601_3_3_0合并而来(1和3选最小的1_1和3选最大的3_合并1次),这两个目录最后会被自动清理。 - 发现多了目录
20200602_2_4_1,其由目录20200602_2_2_0和20200602_4_4_0合并而来(2和4选最小的2_2和4选最大的4_合并1次),这两个目录最后会被自动清理。
- 发现多了目录
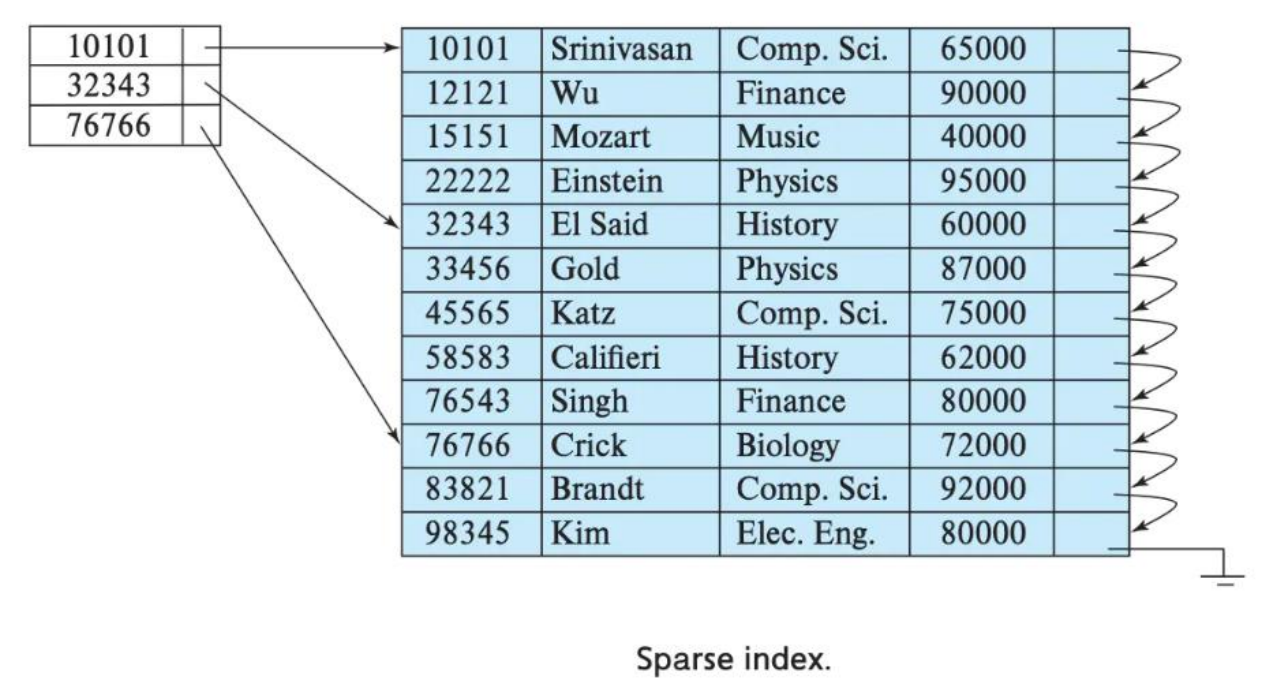
4.4.2 primary key主键(可选)
ClickHouse中的主键,和其他数据库不太一样,它只提供了数据的一级索引,但是却不是唯一约束。这就意味着是可以存在相同primary key的数据。
主键的设定主要依据是查询语句中的where条件。
根据条件通过对主键进行某种形式的二分查找,能够定位到对应的index granularity,避免了全表扫描。
index granularity:直接翻译的话就是索引粒度,指在稀疏索引中两个相邻索引对应数据的间隔。ClickHouse中的MergeTree默认是8192。官方不建议修改这个值,除非该列存在大量重复值,比如在一个分区中几万行才有一个不同数据。稀疏索引的好处就是可以用很少的索引数据,定位更多的数据,代价就是只能定位到索引粒度的第一行,然后再进行一点扫描。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
2291f7f636ff6f :) show create table t_order_mt;
SHOW CREATE TABLE t_order_mt
Query id: 96317444-3135-4e3e-934c-a4c2b4c064a0
┌─statement──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ CREATE TABLE default.t_order_mt
(
`id` UInt32,
`sku_id` String,
`total_amount` Decimal(16, 2),
`create_time` DateTime
)
ENGINE = MergeTree
PARTITION BY toYYYYMMDD(create_time)
PRIMARY KEY id
ORDER BY (id, sku_id)
SETTINGS index_granularity = 8192 │
└────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
1 rows in set. Elapsed: 0.003 sec.![]()
4.4.3 order by(必选)
order by设定了分区内的数据按照哪些字段顺序进行有序保存。
order by是MergeTree中唯一一个必填项,甚至比primary key还重要,因为当用户不设置主键的情况,很多处理会依照order by的字段进行处理。
要求:主键必须是order by字段的前缀字段。比如order by字段是(id,sku_id),那么主键必须是id或者(id,sku_id)。
4.4.4 二级索引
目前在ClickHouse的官网上二级索引的功能在v20.1.2.4之前是被标注为实验性的,在这个版本之后默认是开启的。老版本使用二级索引前需要增加设置,是否允许使用实验性的二级索引(v20.1.2.4开始,这个参数已被删除,默认开启):
1
set allow_experimental_data_skipping_indices=1;
案例:
创建测试表:
1
2
3
4
5
6
7
8
9
10
11
12create table t_order_mt2(
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime,
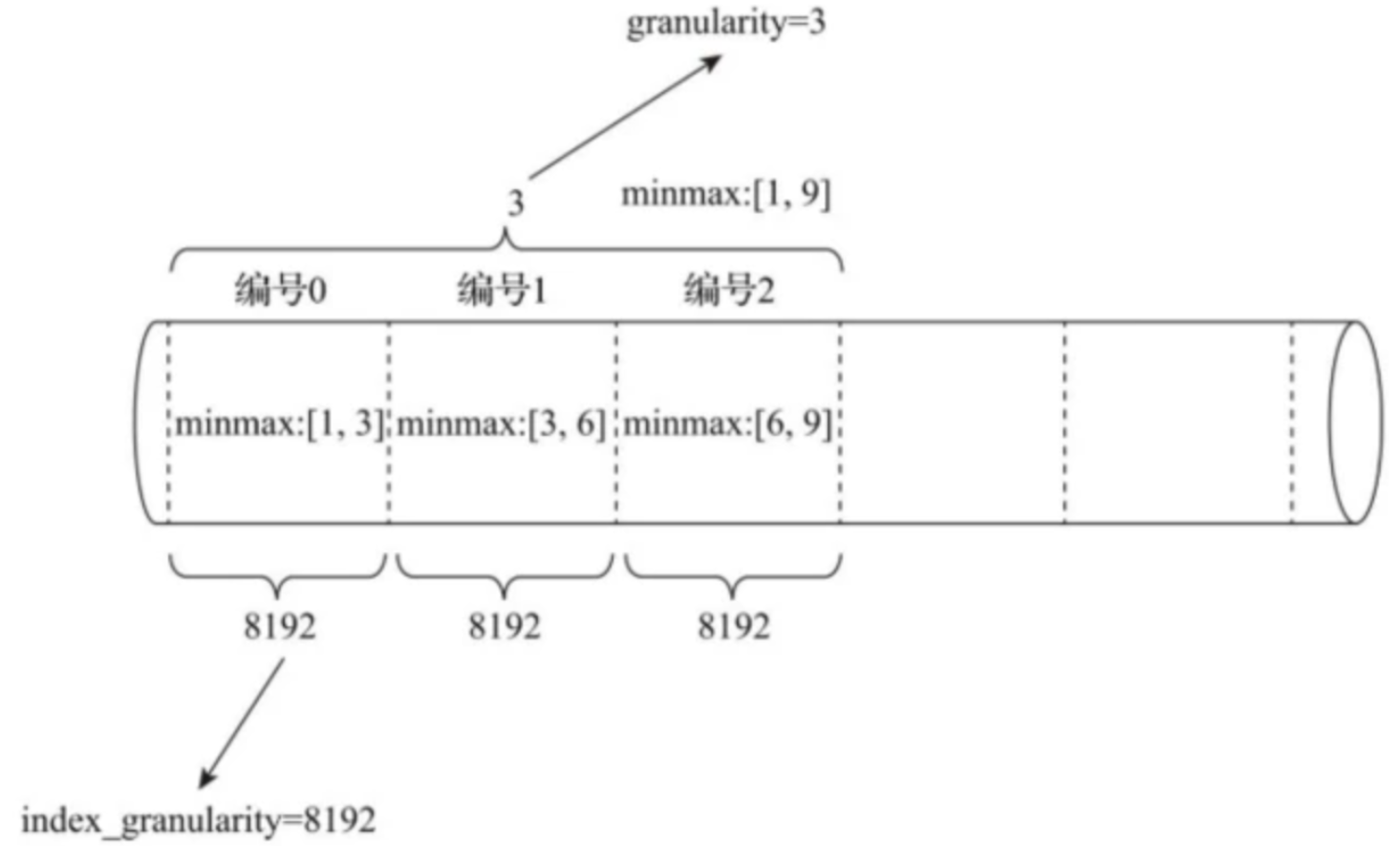
-- GRANULARITY N是设定二级索引对于一级索引粒度的粒度
-- minmax索引的聚合信息是在一个index_granularity区间内数据的最小和最大值。以下图为例,假设index_granularity=8192且granularity=3,则数据会按照index_granularity划分为n等份,MergeTree从第0段分区开始,依次获取聚合信息。当获取到第3个分区时(granularity=3),则汇总并会生成第一行minmax索引(前3段minmax汇总后取值为[1, 9])
INDEX a total_amount TYPE minmax GRANULARITY 5
) engine =MergeTree
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id, sku_id);![]()
插入数据:
1
2
3
4
5
6
7insert into t_order_mt2 values
(101,'sku_001',1000.00,'2020-06-01 12:00:00'),
(102,'sku_002',2000.00,'2020-06-01 11:00:00'),
(102,'sku_004',2500.00,'2020-06-01 12:00:00'),
(102,'sku_002',2000.00,'2020-06-01 13:00:00'),
(102,'sku_002',12000.00,'2020-06-01 13:00:00'),
(102,'sku_002',600.00,'2020-06-02 12:00:00');对比效果:
1
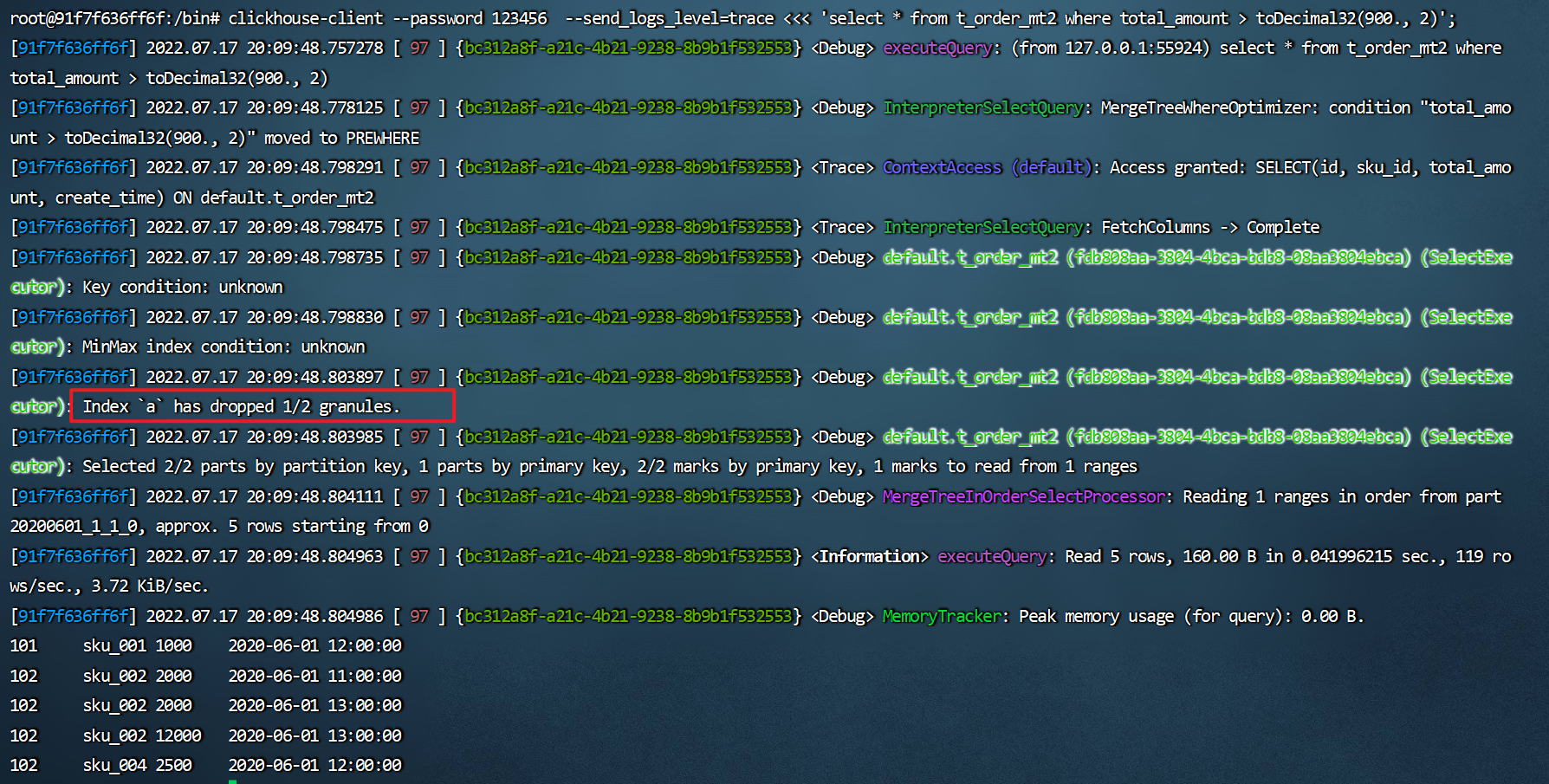
root@91f7f636ff6f:/bin# clickhouse-client --password 123456 --send_logs_level=trace <<< 'select * from t_order_mt2 where total_amount > toDecimal32(900., 2)';
![]()
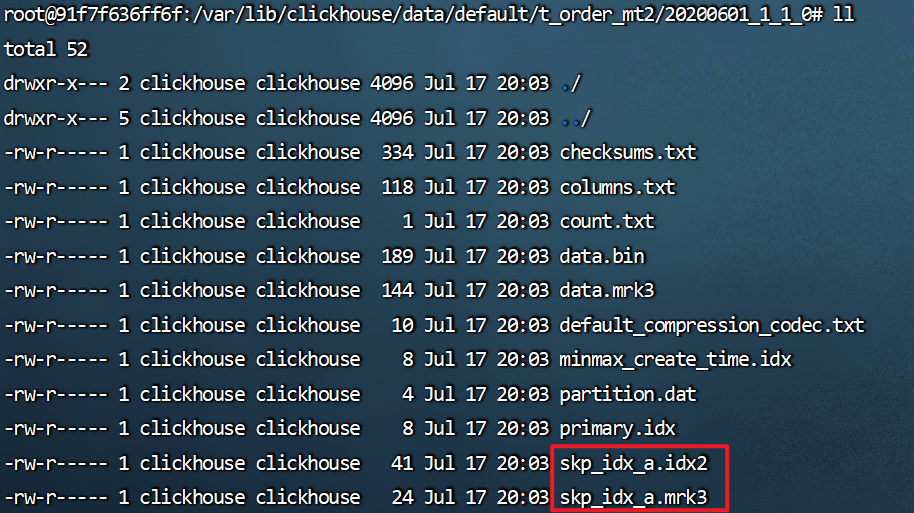
从日志中可以看到二级索引能够为非主键字段的查询发挥作用,分区下文件
skp_idx_a.idx和skp_idx_a.mrk3为跳数索引文件:1
root@91f7f636ff6f:/# cd /var/lib/clickhouse/data/default/t_order_mt2/20200601_1_1_0
![]()
4.4.5 数据TTL
- TTL即Time To Live,MergeTree提供了可以管理数据
表或者列的生命周期的功能。
列级别TTL
创建测试表:
1
2
3
4
5
6
7
8
9
10create table t_order_mt3(
id UInt32,
sku_id String,
-- create_time不能是主键字段并且需要是Datetime类型的
total_amount Decimal(16,2) TTL create_time+interval 10 SECOND,
create_time Datetime
) engine =MergeTree
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id, sku_id);插入数据(注意:根据实际时间改变):
1
2
3
4insert into t_order_mt3 values
(106,'sku_001',1000.00,'2022-07-17 20:30:50'),
(107,'sku_002',2000.00,'2022-07-17 20:30:50'),
(110,'sku_003',600.00,'2022-07-17 20:30:50');手动合并,查看效果到期后,指定的字段数据归0。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
4091f7f636ff6f :) select * from t_order_mt3;
SELECT *
FROM t_order_mt3
Query id: 28df0bf7-9f51-465f-b10c-83100f6d63b3
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 106 │ sku_001 │ 1000 │ 2022-07-17 20:30:50 │
│ 107 │ sku_002 │ 2000 │ 2022-07-17 20:30:50 │
│ 110 │ sku_003 │ 600 │ 2022-07-17 20:30:50 │
└─────┴─────────┴──────────────┴─────────────────────┘
3 rows in set. Elapsed: 0.002 sec.
# 手动合并
91f7f636ff6f :) optimize table t_order_mt3 final;
OPTIMIZE TABLE t_order_mt3 FINAL
Query id: 2b8401e4-6020-408b-b3b3-3e76118038cd
Ok.
0 rows in set. Elapsed: 0.006 sec.
91f7f636ff6f :) select * from t_order_mt3;
SELECT *
FROM t_order_mt3
Query id: 370b35fc-2477-4c2c-bced-03f90f76bb16
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 106 │ sku_001 │ 0 │ 2022-07-17 20:30:50 │
│ 107 │ sku_002 │ 0 │ 2022-07-17 20:30:50 │
│ 110 │ sku_003 │ 0 │ 2022-07-17 20:30:50 │
└─────┴─────────┴──────────────┴─────────────────────┘
3 rows in set. Elapsed: 0.002 sec.
表级TTL
下面的这条语句是数据会在create_time之后10秒丢失。
1
alter table t_order_mt3 MODIFY TTL create_time + INTERVAL 10 SECOND;
涉及判断的字段必须是Date或者Datetime类型,推荐使用分区的日期字段:
- SECOND
- MINUTE
- HOUR
- DAY
- WEEK
- MONTH
- QUARTER
- YEAR
4.5 ReplacingMergeTree
ReplacingMergeTree是MergeTree的一个变种,它存储特性完全继承MergeTree,只是多了一个去重的功能(根据order by去重)。尽管MergeTree可以设置主键,但是primary key其实没有唯一约束的功能。如果你想处理掉重复的数据,可以借助这个ReplacingMergeTree。
- 去重时机:数据的去重只会在合并的过程中出现。合并会在未知的时间在后台进行,所以你无法预先作出计划。有一些数据可能仍未被处理。
- 去重范围:如果表经过了分区,去重只会在分区内部进行去重,不能执行跨分区的去重。所以ReplacingMergeTree能力有限,ReplacingMergeTree适用于在后台清除重复的数据以节省空间,但是它不保证没有重复的数据出现。
案例:
创建表:
1
2
3
4
5
6
7
8
9create table t_order_rmt(
id UInt32,
sku_id String,
total_amount Decimal(16,2) ,
create_time Datetime
) engine =ReplacingMergeTree(create_time)
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id, sku_id);ReplacingMergeTree()填入的参数为版本字段,重复数据保留版本字段值最大的。如果不填版本字段,默认按照插入顺序保留最后一条。插入数据:
1
2
3
4
5
6
7insert into t_order_rmt values
(101,'sku_001',1000.00,'2020-06-01 12:00:00'),
(102,'sku_002',2000.00,'2020-06-01 11:00:00'),
(102,'sku_004',2500.00,'2020-06-01 12:00:00'),
(102,'sku_002',2000.00,'2020-06-01 13:00:00'),
(102,'sku_002',12000.00,'2020-06-01 13:00:00'),
(102,'sku_002',600.00,'2020-06-02 12:00:00');执行第一次查询:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
1791f7f636ff6f :) select * from t_order_rmt;
SELECT *
FROM t_order_rmt
Query id: 029004f5-dee8-430a-924d-b178ff6f6bd7
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 102 │ sku_002 │ 600 │ 2020-06-02 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 101 │ sku_001 │ 1000 │ 2020-06-01 12:00:00 │
│ 102 │ sku_002 │ 12000 │ 2020-06-01 13:00:00 │
│ 102 │ sku_004 │ 2500 │ 2020-06-01 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
4 rows in set. Elapsed: 0.002 sec.再插入数据:
1
2
3
4
5
6
7insert into t_order_rmt values
(101,'sku_001',1000.00,'2020-06-01 12:00:00'),
(102,'sku_002',2000.00,'2020-06-01 11:00:00'),
(102,'sku_004',2500.00,'2020-06-01 12:00:00'),
(102,'sku_002',2000.00,'2020-06-01 13:00:00'),
(102,'sku_002',12000.00,'2020-06-01 13:00:00'),
(102,'sku_002',600.00,'2020-06-02 12:00:00');再一次查询:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
2591f7f636ff6f :) select * from t_order_rmt;
SELECT *
FROM t_order_rmt
Query id: 2c339c83-bfef-44a6-adfd-6389f128052e
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 102 │ sku_002 │ 600 │ 2020-06-02 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 102 │ sku_002 │ 600 │ 2020-06-02 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 101 │ sku_001 │ 1000 │ 2020-06-01 12:00:00 │
│ 102 │ sku_002 │ 12000 │ 2020-06-01 13:00:00 │
│ 102 │ sku_004 │ 2500 │ 2020-06-01 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 101 │ sku_001 │ 1000 │ 2020-06-01 12:00:00 │
│ 102 │ sku_002 │ 12000 │ 2020-06-01 13:00:00 │
│ 102 │ sku_004 │ 2500 │ 2020-06-01 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
8 rows in set. Elapsed: 0.003 sec.手动合并:
1
2
3
4
5
6
7
8
991f7f636ff6f :) optimize table t_order_rmt final;
OPTIMIZE TABLE t_order_rmt FINAL
Query id: 696bd4fe-0cc1-4bf4-ae62-4b436688c2ff
Ok.
0 rows in set. Elapsed: 0.009 sec.再次查询:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
1791f7f636ff6f :) select * from t_order_rmt;
SELECT *
FROM t_order_rmt
Query id: f9993d6f-2624-4f69-85dd-7089dd562781
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 102 │ sku_002 │ 600 │ 2020-06-02 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 101 │ sku_001 │ 1000 │ 2020-06-01 12:00:00 │
│ 102 │ sku_002 │ 12000 │ 2020-06-01 13:00:00 │
│ 102 │ sku_004 │ 2500 │ 2020-06-01 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
4 rows in set. Elapsed: 0.003 sec
结论:
- 实际上是使用order by字段作为唯一键进行去重。
- 去重不能跨分区。
- 只有同一批插入(新版本)或合并分区时才会进行去重。
- 认定重复的数据保留,版本字段值最大的。
- 如果版本字段相同则按插入顺序保留最后一笔。
4.6 SummingMergeTree
对于不查询明细,只关心以维度进行汇总聚合结果的场景。如果只使用普通的MergeTree的话,无论是存储空间的开销,还是查询时临时聚合的开销都比较大。
ClickHouse为了这种场景,提供了一种能够”预聚合”的引擎SummingMergeTree。
案例:
创建表:
1
2
3
4
5
6
7
8
9create table t_order_smt(
id UInt32,
sku_id String,
total_amount Decimal(16,2) ,
create_time Datetime
) engine =SummingMergeTree(total_amount)
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id,sku_id );插入数据。
1
2
3
4
5
6
7insert into t_order_smt values
(101,'sku_001',1000.00,'2020-06-01 12:00:00'),
(102,'sku_002',2000.00,'2020-06-01 11:00:00'),
(102,'sku_004',2500.00,'2020-06-01 12:00:00'),
(102,'sku_002',2000.00,'2020-06-01 13:00:00'),
(102,'sku_002',12000.00,'2020-06-01 13:00:00'),
(102,'sku_002',600.00,'2020-06-02 12:00:00');执行第一次查询,发现分区内以(id,sku_id)合并total_amount的值,并且create_time取的是最早插入的一条:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
1791f7f636ff6f :) select * from t_order_smt;
SELECT *
FROM t_order_smt
Query id: c8491a4b-cdd6-4752-8053-eac0fc922dbc
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 102 │ sku_002 │ 600 │ 2020-06-02 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 101 │ sku_001 │ 1000 │ 2020-06-01 12:00:00 │
│ 102 │ sku_002 │ 16000 │ 2020-06-01 11:00:00 │
│ 102 │ sku_004 │ 2500 │ 2020-06-01 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
4 rows in set. Elapsed: 0.006 sec.
通过结果可以得到以下结论:
- 以
SummingMergeTree()中指定的列作为汇总数据列。 - 可以填写多列必须数字列,如果不填,以所有非维度列(除了order by的列之外)且为数字列的字段为汇总数据列。
- 以order by的列为准,作为维度列。
- 其他的列按插入顺序保留第一行。
- 不在一个分区的数据不会被聚合。
- 只有在同一批次插入(新版本)或分片合并时才会进行聚合。
- 以
开发建议:设计聚合表的话,唯一键值、流水号可以去掉,所有字段全部是维度、度量或者时间戳。
5、SQL操作
- 基本上来说传统关系型数据库(以 MySQL 为例)的SQL语句,ClickHouse基本都支持,这里不会从头讲解SQL语法只介绍ClickHouse与标准SQL(MySQL)不一致的地方。
5.1 Insert
基本与标准SQL(MySQL)基本一致。
标准
1
insert into [table_name] values(…),(…)
从表到表的插入
1
insert into [table_name] select a,b,c from [table_name_2]
5.2 Update和Delete
ClickHouse提供了Delete和Update的能力,这类操作被称为Mutation查询,它可以看做Alter的一种。
虽然可以实现修改和删除,但是和一般的OLTP数据库不一样,Mutation语句是一种很”重”的操作,而且不支持事务。
“重”的原因主要是每次修改或者删除都会导致放弃目标数据的原有分区,重建新分区。所以尽量做批量的变更,不要进行频繁小数据的操作。
删除操作
1
alter table t_order_smt delete where sku_id ='sku_001';
修改操作
1
alter table t_order_smt update total_amount=toDecimal32(2000.00,2) where id=102;
由于操作比较”重”,所以Mutation语句分两步执行,同步执行的部分其实只是进行新增数据、新增分区和并把旧分区打上逻辑上的失效标记。直到触发分区合并的时候,才会删除旧数据释放磁盘空间,一般不会开放这样的功能给用户,由管理员完成。
实现高性能update或者delete的思路:
![]()

5.3 查询操作
- ClickHouse基本上与标准SQL差别不大。
支持子查询。
支持CTE(Common Table Expression公用表表达式with子句)。
支持各种JOIN,但是JOIN操作无法使用缓存,所以即使是两次相同的JOIN语句,ClickHouse也会视为两条新SQL。
窗口函数(官方正在测试中…)。
不支持自定义函数。
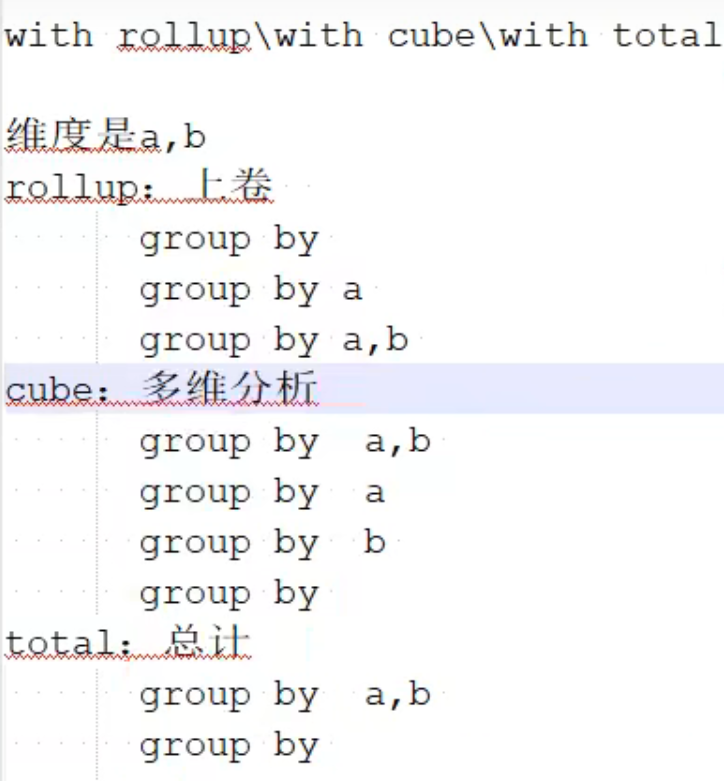
GROUP BY操作增加了with rollup、with cube、with total用来计算小计和总计。
![1658240702438]()
插入数据:
1
2
3
4
5
6
7
8
9
10
11
12
13alter table t_order_mt delete where 1=1;
insert into t_order_mt values
(101,'sku_001',1000.00,'2020-06-01 12:00:00'),
(101,'sku_002',2000.00,'2020-06-01 12:00:00'),
(103,'sku_004',2500.00,'2020-06-01 12:00:00'),
(104,'sku_002',2000.00,'2020-06-01 12:00:00'),
(105,'sku_003',600.00,'2020-06-02 12:00:00'),
(106,'sku_001',1000.00,'2020-06-04 12:00:00'),
(107,'sku_002',2000.00,'2020-06-04 12:00:00'),
(108,'sku_004',2500.00,'2020-06-04 12:00:00'),
(109,'sku_002',2000.00,'2020-06-04 12:00:00'),
(110,'sku_003',600.00,'2020-06-01 12:00:00');with rollup:从右至左去掉维度进行小计。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
4291f7f636ff6f :) select id,sku_id,sum(total_amount) from t_order_mt group by id,sku_id with rollup;
SELECT
id,
sku_id,
sum(total_amount)
FROM t_order_mt
GROUP BY
id,
sku_id
WITH ROLLUP
Query id: ed67ef26-8a93-4752-8172-dae661f9037d
┌──id─┬─sku_id──┬─sum(total_amount)─┐
│ 110 │ sku_003 │ 600 │
│ 109 │ sku_002 │ 2000 │
│ 107 │ sku_002 │ 2000 │
│ 106 │ sku_001 │ 1000 │
│ 104 │ sku_002 │ 2000 │
│ 101 │ sku_002 │ 2000 │
│ 103 │ sku_004 │ 2500 │
│ 108 │ sku_004 │ 2500 │
│ 105 │ sku_003 │ 600 │
│ 101 │ sku_001 │ 1000 │
└─────┴─────────┴───────────────────┘
┌──id─┬─sku_id─┬─sum(total_amount)─┐
│ 110 │ │ 600 │
│ 106 │ │ 1000 │
│ 105 │ │ 600 │
│ 109 │ │ 2000 │
│ 107 │ │ 2000 │
│ 104 │ │ 2000 │
│ 103 │ │ 2500 │
│ 108 │ │ 2500 │
│ 101 │ │ 3000 │
└─────┴────────┴───────────────────┘
┌─id─┬─sku_id─┬─sum(total_amount)─┐
│ 0 │ │ 16200 │
└────┴────────┴───────────────────┘
20 rows in set. Elapsed: 0.014 sec.with cube : 从右至左去掉维度进行小计,再从左至右去掉维度进行小计。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
4891f7f636ff6f :) select id,sku_id,sum(total_amount) from t_order_mt group by id,sku_id with cube;
SELECT
id,
sku_id,
sum(total_amount)
FROM t_order_mt
GROUP BY
id,
sku_id
WITH CUBE
Query id: 5199a844-3087-4e22-8511-09ebe161e33b
┌──id─┬─sku_id──┬─sum(total_amount)─┐
│ 110 │ sku_003 │ 600 │
│ 109 │ sku_002 │ 2000 │
│ 107 │ sku_002 │ 2000 │
│ 106 │ sku_001 │ 1000 │
│ 104 │ sku_002 │ 2000 │
│ 101 │ sku_002 │ 2000 │
│ 103 │ sku_004 │ 2500 │
│ 108 │ sku_004 │ 2500 │
│ 105 │ sku_003 │ 600 │
│ 101 │ sku_001 │ 1000 │
└─────┴─────────┴───────────────────┘
┌──id─┬─sku_id─┬─sum(total_amount)─┐
│ 110 │ │ 600 │
│ 106 │ │ 1000 │
│ 105 │ │ 600 │
│ 109 │ │ 2000 │
│ 107 │ │ 2000 │
│ 104 │ │ 2000 │
│ 103 │ │ 2500 │
│ 108 │ │ 2500 │
│ 101 │ │ 3000 │
└─────┴────────┴───────────────────┘
┌─id─┬─sku_id──┬─sum(total_amount)─┐
│ 0 │ sku_003 │ 1200 │
│ 0 │ sku_004 │ 5000 │
│ 0 │ sku_001 │ 2000 │
│ 0 │ sku_002 │ 8000 │
└────┴─────────┴───────────────────┘
┌─id─┬─sku_id─┬─sum(total_amount)─┐
│ 0 │ │ 16200 │
└────┴────────┴───────────────────┘
24 rows in set. Elapsed: 0.003 sec.with totals:只计算合计。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
3391f7f636ff6f :) select id,sku_id,sum(total_amount) from t_order_mt group by id,sku_id with totals;
SELECT
id,
sku_id,
sum(total_amount)
FROM t_order_mt
GROUP BY
id,
sku_id
WITH TOTALS
Query id: dffea091-597c-42ec-bf19-c4ff93d0dfc9
┌──id─┬─sku_id──┬─sum(total_amount)─┐
│ 110 │ sku_003 │ 600 │
│ 109 │ sku_002 │ 2000 │
│ 107 │ sku_002 │ 2000 │
│ 106 │ sku_001 │ 1000 │
│ 104 │ sku_002 │ 2000 │
│ 101 │ sku_002 │ 2000 │
│ 103 │ sku_004 │ 2500 │
│ 108 │ sku_004 │ 2500 │
│ 105 │ sku_003 │ 600 │
│ 101 │ sku_001 │ 1000 │
└─────┴─────────┴───────────────────┘
Totals:
┌─id─┬─sku_id─┬─sum(total_amount)─┐
│ 0 │ │ 16200 │
└────┴────────┴───────────────────┘
10 rows in set. Elapsed: 0.003 sec.
5.4 alter操作
- 同MySQL的修改字段基本一致。
新增字段
1
alter table tableName add column newcolname String after col1;
修改字段类型
1
alter table tableName modify column newcolname String;
删除字段
1
alter table tableName drop column newcolname;
5.5 导出数据
1 | clickhouse-client --query "select * from t_order_mt where create_time='2020-06-01 12:00:00'" --format CSVWithNames > /opt/module/data/rs1.csv |
官网:https://clickhouse.com/docs/en/interfaces/formats#csv。
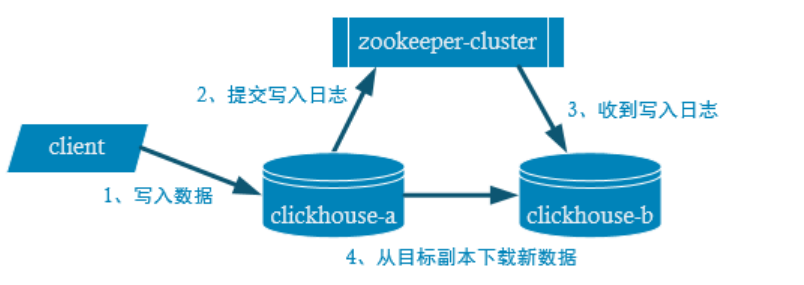
6、副本
- 副本的目的主要是保障数据的高可用性,即使一台ClickHouse节点宕机,那么也可以从其他服务器获得相同的数据。参考文档:
https://clickhouse.com/docs/en/engines/table-engines/mergetree-family/replication。
6.1 副本写入流程
6.2 配置步骤
6.2.1 安装两个副本的ck
安装zookeeper。
1
2
3
4
5
6
7
8
9
10
11
12
13
14[root@iz2zecc4mo4hoc75p0frn8z ~]# docker pull zookeeper:3.5.7
3.5.7: Pulling from library/zookeeper
afb6ec6fdc1c: Pull complete
ee19e84e8bd1: Pull complete
6ac787417531: Pull complete
f3f781d4d83e: Pull complete
424c9e43d19a: Pull complete
f0929561e8a7: Pull complete
f1cf0c087cb3: Pull complete
2f47bb4dd07a: Pull complete
Digest: sha256:883b014b6535574503bda8fc6a7430ba009c0273242f86d401095689652e5731
Status: Downloaded newer image for zookeeper:3.5.7
[root@iz2zecc4mo4hoc75p0frn8z ~]# docker run -d -p 2181:2181 --name single-zookeeper zookeeper:3.5.7
6f0444fa75ce40fa63450d05ec9410954f85e6e2cc14dadccc978b899f2b5a1d创建自定义网络。
1
[root@iz2zecc4mo4hoc75p0frn8z ~]# docker network create --driver bridge --subnet=172.18.0.0/16 --gateway=172.18.0.1 cknet
修改/data/udata/clickhouse01/conf/config.xml配置文件,打开zookeeper有关的配置信息。
1
2
3
4
5
6<zookeeper>
<node>
<host>192.168.200.129</host>
<port>2181</port>
</node>
</zookeeper>![]()
创建clickhouse2的有关目录并拷贝配置文件。
1
2
3[root@centos7 ~]# mkdir -p /data/udata/clickhouse02/conf /data/udata/clickhouse02/data /data/udata/clickhouse02/log
[root@centos7 ~]# cp /data/udata/clickhouse01/conf/users.xml /data/udata/clickhouse02/conf/users.xml
[root@centos7 ~]# cp /data/udata/clickhouse01/conf/config.xml /data/udata/clickhouse02/conf/config.xml分别启动clickhouse01和clickhouse02。
1
2
3
4
5[root@izbp149369l18v794wqfxaz ~]# docker run -d --name clickhouse01 -e TZ="Asia/Shanghai" --network cknet --ip 172.18.0.2 --hostname clickhouse01 -p 8123:8123 -p 9009:9009 -p 9000:9000 --ulimit nofile=262144:262144 --volume=/data/udata/clickhouse01/data:/var/lib/clickhouse --volume=/data/udata/clickhouse01/log:/var/log/clickhouse-server --volume=/data/udata/clickhouse01/conf/config.xml:/etc/clickhouse-server/config.xml --volume=/data/udata/v/conf/metrika.xml:/etc/clickhouse-server/metrika.xml --volume=/data/udata/clickhouse01/conf/users.xml:/etc/clickhouse-server/users.xml yandex/clickhouse-server:21.12.4.1
c555ae45396a0871663c4a18522c2dddbdfa5810cb4cf3b2b00520c374456f2b
[root@izbp149369l18v794wqfxaz ~]# docker run -d --name clickhouse02 -e TZ="Asia/Shanghai" --network cknet --ip 172.18.0.3 --hostname clickhouse02 -p 8124:8123 -p 9010:9009 -p 9001:9000 --ulimit nofile=262144:262144 --volume=/data/udata/clickhouse02/data:/var/lib/clickhouse --volume=/data/udata/clickhouse02/log:/var/log/clickhouse-server --volume=/data/udata/clickhouse02/conf/config.xml:/etc/clickhouse-server/config.xml --volume=/data/udata/v2/conf/metrika.xml:/etc/clickhouse-server/metrika.xml --volume=/data/udata/clickhouse02/conf/users.xml:/etc/clickhouse-server/users.xml yandex/clickhouse-server:21.12.4.1
b7ae4932cc2f9b35fbe8f7ca6dce4d953a3d6eb9fff6ae123ca9d2e1d0a05978
6.2.2 副本验证
在clickhouse01和clickhouse02上分别建表。副本只能同步数据,不能同步表结构,所以我们需要在每台机器上自己手动建表。
- ReplicatedMergeTree 中,第一个参数是分片的zk_path一般按照:/clickhouse/table/{shard}/{table_name}的格式写,如果只有一个分片就写01即可。
- 第二个参数是副本名称,相同的分片副本名称不能相同。
1
2
3
4
5
6
7
8
9create table t_order_rep2 (
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime
) engine =ReplicatedMergeTree('/clickhouse/table/01/t_order_rep','rep_102')
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id,sku_id);1
2
3
4
5
6
7
8
9create table t_order_rep2 (
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime
) engine =ReplicatedMergeTree('/clickhouse/table/01/t_order_rep','rep_103')
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id,sku_id);此时可以看到zookeeper上已经创建了有关的节点信息。
![]()
在clickhouse01上执行insert语句。
1
2
3
4
5
6insert into t_order_rep2 values
(101,'sku_001',1000.00,'2020-06-01 12:00:00'),
(102,'sku_002',2000.00,'2020-06-01 12:00:00'),
(103,'sku_004',2500.00,'2020-06-01 12:00:00'),
(104,'sku_002',2000.00,'2020-06-01 12:00:00'),
(105,'sku_003',600.00,'2020-06-02 12:00:00');此时可以在clickhouse02查到这些数据。
![]()
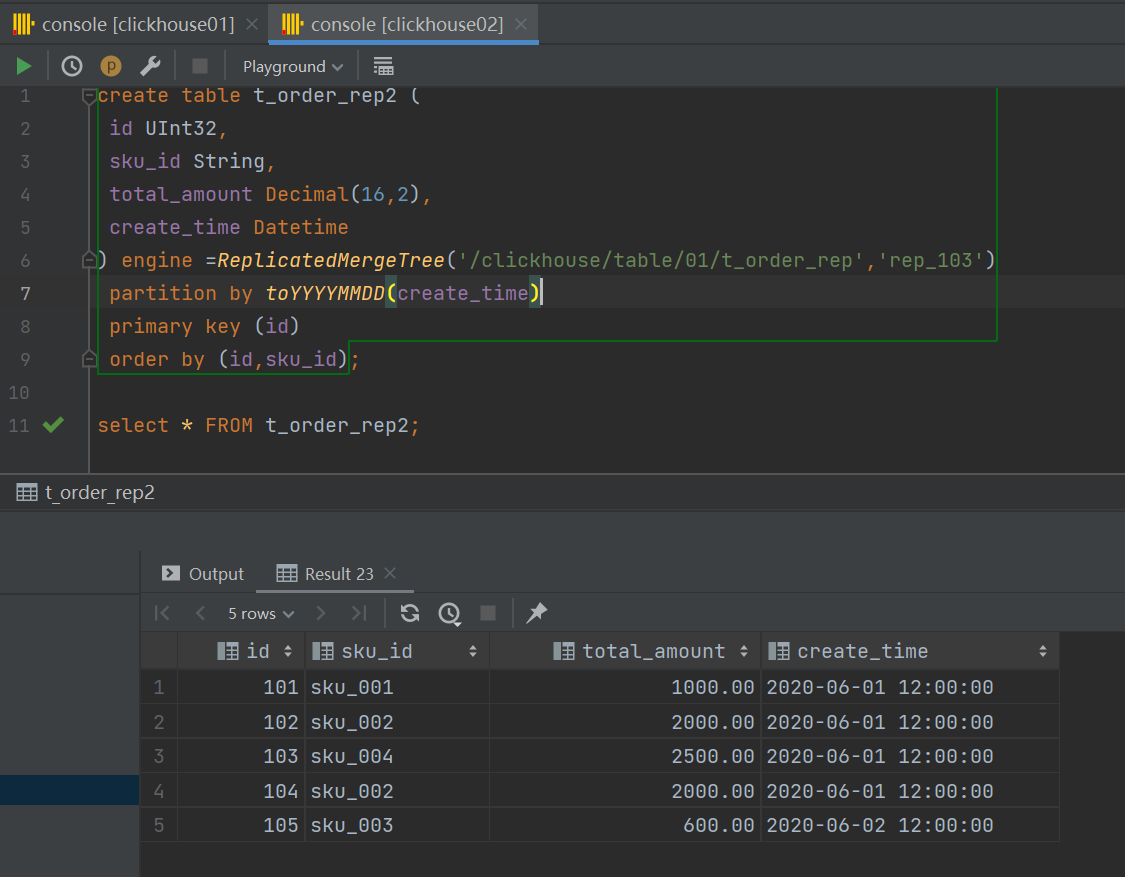
7、分片集群
- 副本虽然能够提高数据的可用性,降低丢失风险,但是每台服务器实际上必须容纳全量数据,对数据的横向扩容没有解决。
- 要解决数据水平切分的问题,需要引入分片的概念。通过分片把一份完整的数据进行切分,不同的分片分布到不同的节点上,再通过Distributed表引擎把数据拼接起来一同使用。
- Distributed表引擎本身不存储数据,有点类似于MyCat之于MySql,成为一种中间件,通过分布式逻辑表来写入、分发、路由来操作多台节点不同分片的分布式数据。
- 注意:ClickHouse的集群是表级别的,实际企业中,大部分做了高可用,但是没有用分片,避免降低查询性能以及操作集群的复杂性。
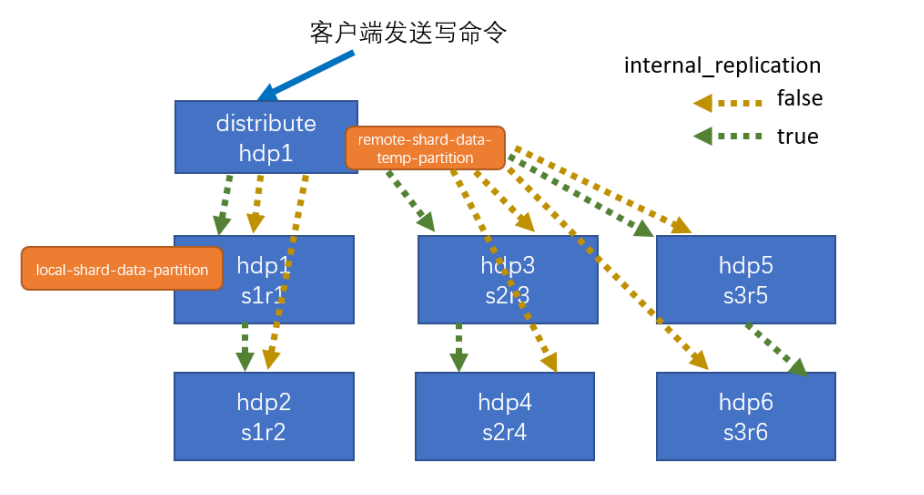
7.1 集群写入流程(3分片2副本共6个节点)
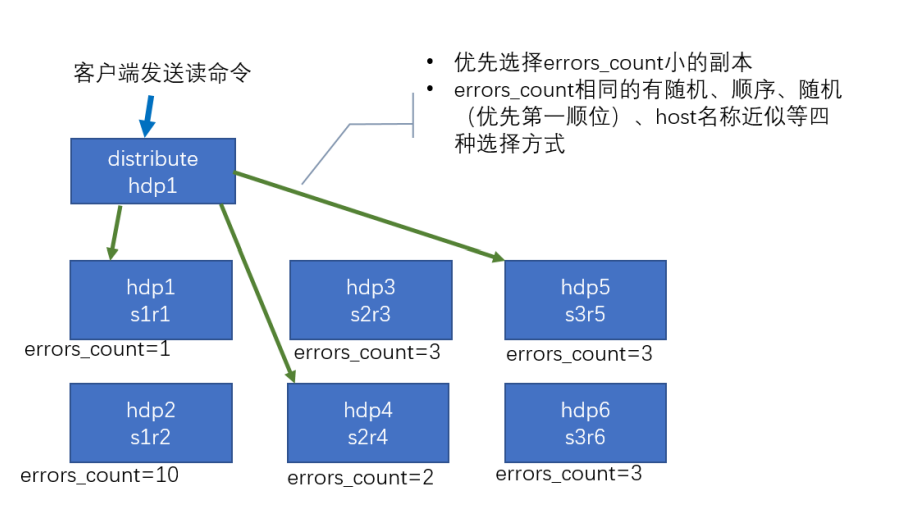
7.2 集群读取流程(3分片2副本共6个节点)
7.3 分片2副本共6个节点集群配置
在/etc/clickhouse-server/config.d/metrika.xml,内容如下:
注:也可以不创建外部文件,直接在config.xml的中指定。
1 | <yandex> |
7.4 配置三节点版本集群及副本
7.4.1 集群及副本规划(2个分片,只有第一个分片有副本)
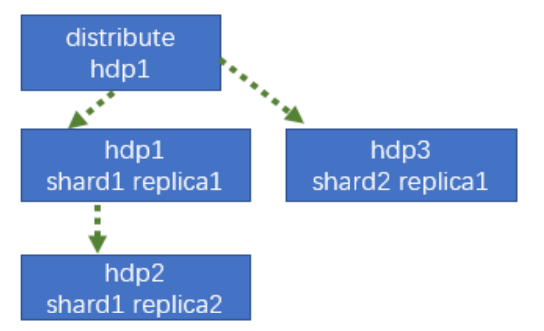
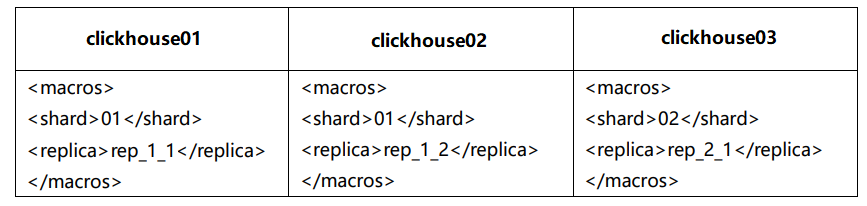
7.4.2 配置步骤
在/data/udata/clickhouse01/conf目录下创建metrika-shard.xml文件,内容如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
<yandex>
<remote_servers>
<gmall_cluster> <!-- 集群名称-->
<shard> <!--集群的第一个分片-->
<internal_replication>true</internal_replication>
<replica> <!--该分片的第一个副本-->
<host>clickhouse01</host>
<port>9000</port>
<user>default</user>
<password>123456</password>
</replica>
<replica> <!--该分片的第二个副本-->
<host>clickhouse02</host>
<port>9000</port>
<user>default</user>
<password>123456</password>
</replica>
</shard>
<shard> <!--集群的第二个分片-->
<internal_replication>true</internal_replication>
<replica> <!--该分片的第一个副本-->
<host>clickhouse03</host>
<port>9000</port>
<user>default</user>
<password>123456</password>
</replica>
</shard>
</gmall_cluster>
</remote_servers>
<zookeeper-servers>
<node index="1">
<host>192.168.200.129</host>
<port>2181</port>
</node>
</zookeeper-servers>
<macros>
<shard>01</shard> <!--不同机器放的分片数不一样-->
<replica>rep_1_1</replica> <!--不同机器放的副本数不一样-->
</macros>
</yandex>修改/data/udata/clickhouse01/conf目录下的config.xml文件,添加如下内容:
1
2<zookeeper incl="zookeeper-servers" optional="true" />
<include_from>/etc/clickhouse-server/metrika-shard.xml</include_from>将clickhouse01的配置文件复制到clickhouse02上并修改metrika-shard.xml文件:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44[root@izbp149369l18v794wqfxaz ~]# cp /data/udata/clickhouse01/conf/metrika-shard.xml /data/udata/clickhouse02/conf/metrika-shard.xml
[root@izbp149369l18v794wqfxaz ~]# cp /data/udata/clickhouse01/conf/config.xml /data/udata/clickhouse02/conf/config.xml
[root@izbp149369l18v794wqfxaz ~]# vim /data/udata/clickhouse02/conf/metrika-shard.xml
<?xml version="1.0"?>
<yandex>
<remote_servers>
<gmall_cluster> <!-- 集群名称-->
<shard> <!--集群的第一个分片-->
<internal_replication>true</internal_replication>
<replica> <!--该分片的第一个副本-->
<host>clickhouse01</host>
<port>9000</port>
<user>default</user>
<password>123456</password>
</replica>
<replica> <!--该分片的第二个副本-->
<host>clickhouse02</host>
<port>9000</port>
<user>default</user>
<password>123456</password>
</replica>
</shard>
<shard> <!--集群的第二个分片-->
<internal_replication>true</internal_replication>
<replica> <!--该分片的第一个副本-->
<host>clickhouse03</host>
<port>9000</port>
<user>default</user>
<password>123456</password>
</replica>
</shard>
</gmall_cluster>
</remote_servers>
<zookeeper-servers>
<node index="1">
<host>192.168.200.129</host>
<port>2181</port>
</node>
</zookeeper-servers>
<macros>
<shard>01</shard> <!--不同机器放的分片数不一样-->
<replica>rep_1_2</replica> <!--不同机器放的副本数不一样-->
</macros>
</yandex>将clickhouse01的配置文件复制到clickhouse03上并修改metrika-shard.xml文件:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46[root@izbp149369l18v794wqfxaz ~]# mkdir -p /data/udata/clickhouse03/conf /data/udata/clickhouse03/data /data/udata/clickhouse03/log
[root@izbp149369l18v794wqfxaz ~]# cp /data/udata/clickhouse01/conf/users.xml /data/udata/clickhouse03/conf/users.xml
[root@izbp149369l18v794wqfxaz ~]# cp /data/udata/clickhouse01/conf/metrika-shard.xml /data/udata/clickhouse03/conf/metrika-shard.xml
[root@izbp149369l18v794wqfxaz ~]# cp /data/udata/clickhouse01/conf/config.xml /data/udata/clickhouse03/conf/config.xml
[root@izbp149369l18v794wqfxaz ~]# vim /data/udata/clickhouse03/conf/metrika-shard.xml
<?xml version="1.0"?>
<yandex>
<remote_servers>
<gmall_cluster> <!-- 集群名称-->
<shard> <!--集群的第一个分片-->
<internal_replication>true</internal_replication>
<replica> <!--该分片的第一个副本-->
<host>clickhouse01</host>
<port>9000</port>
<user>default</user>
<password>123456</password>
</replica>
<replica> <!--该分片的第二个副本-->
<host>clickhouse02</host>
<port>9000</port>
<user>default</user>
<password>123456</password>
</replica>
</shard>
<shard> <!--集群的第二个分片-->
<internal_replication>true</internal_replication>
<replica> <!--该分片的第一个副本-->
<host>clickhouse03</host>
<port>9000</port>
<user>default</user>
<password>123456</password>
</replica>
</shard>
</gmall_cluster>
</remote_servers>
<zookeeper-servers>
<node index="1">
<host>192.168.200.129</host>
<port>2181</port>
</node>
</zookeeper-servers>
<macros>
<shard>02</shard> <!--不同机器放的分片数不一样-->
<replica>rep_2_1</replica> <!--不同机器放的副本数不一样-->
</macros>
</yandex>启动zookeeper:
1
2[root@izbp149369l18v794wqfxaz ~]# docker run -d -p 2181:2181 --name single-zookeeper zookeeper:3.5.7
b2682b4798a510ab3ad6b18bcbcecd27736e99191602836bb57c52d517d5c0ba启动clickhouse01:
1
2[root@izbp149369l18v794wqfxaz ~]# docker run -d --name clickhouse01 -e TZ="Asia/Shanghai" --network cknet --ip 172.18.0.2 --hostname clickhouse01 -p 8123:8123 -p 9009:9009 -p 9000:9000 --ulimit nofile=262144:262144 --volume=/data/udata/clickhouse01/data:/var/lib/clickhouse --volume=/data/udata/clickhouse01/log:/var/log/clickhouse-server --volume=/data/udata/clickhouse01/conf/config.xml:/etc/clickhouse-server/config.xml --volume=/data/udata/clickhouse01/conf/metrika-shard.xml:/etc/clickhouse-server/metrika-shard.xml --volume=/data/udata/clickhouse01/conf/users.xml:/etc/clickhouse-server/users.xml yandex/clickhouse-server:21.12.4.1
a34db3915434305d9dd944425d83a0624bd940c805aa16237ac9005e8beca9c1启动clickhouse02:
1
2[root@izbp149369l18v794wqfxaz ~]# docker run -d --name clickhouse02 -e TZ="Asia/Shanghai" --network cknet --ip 172.18.0.3 --hostname clickhouse02 -p 8124:8123 -p 9010:9009 -p 9001:9000 --ulimit nofile=262144:262144 --volume=/data/udata/clickhouse02/data:/var/lib/clickhouse --volume=/data/udata/clickhouse02/log:/var/log/clickhouse-server --volume=/data/udata/clickhouse02/conf/config.xml:/etc/clickhouse-server/config.xml --volume=/data/udata/clickhouse02/conf/metrika-shard.xml:/etc/clickhouse-server/metrika-shard.xml --volume=/data/udata/clickhouse02/conf/users.xml:/etc/clickhouse-server/users.xml yandex/clickhouse-server:21.12.4.1
5acc6fef60ec348e461d6d927abf368b6620311ab0e3e3efbda27e47a962fa93启动clickhouse03:
1
2[root@izbp149369l18v794wqfxaz ~]# docker run -d --name clickhouse03 -e TZ="Asia/Shanghai" --network cknet --ip 172.18.0.4 --hostname clickhouse03 -p 8125:8123 -p 9011:9009 -p 9002:9000 --ulimit nofile=262144:262144 --volume=/data/udata/clickhouse03/data:/var/lib/clickhouse --volume=/data/udata/clickhouse03/log:/var/log/clickhouse-server --volume=/data/udata/clickhouse03/conf/config.xml:/etc/clickhouse-server/config.xml --volume=/data/udata/clickhouse03/conf/metrika-shard.xml:/etc/clickhouse-server/metrika-shard.xml --volume=/data/udata/clickhouse03/conf/users.xml:/etc/clickhouse-server/users.xml yandex/clickhouse-server:21.12.4.1
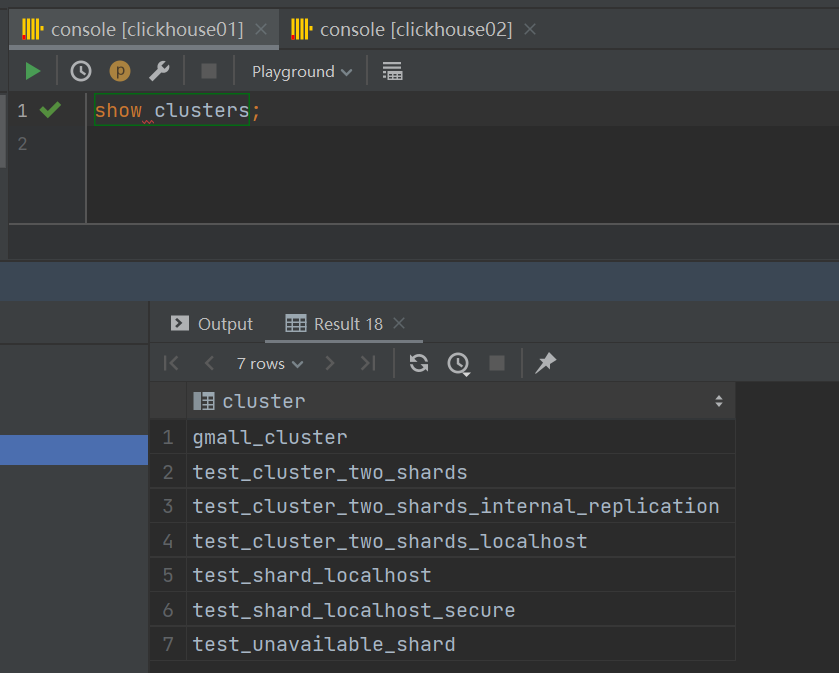
e90791027defe4922d91d191375b51016e52a9959ba8e70df01d9b651d4a6f9b可通过命令查看到部署的集群信息:
![1685261098016]()
7.4.3 集群验证
在clickhouse01上执行建表语句:
- 会自动同步到clickhouse02和clickhouse03上。
- 集群名字要和配置文件中的一致。
- 分片和副本名称从配置文件的宏定义中获取。
1
2
3
4
5
6
7
8
9
10
11-- 指定on cluster会自动在三个节点创建本地表
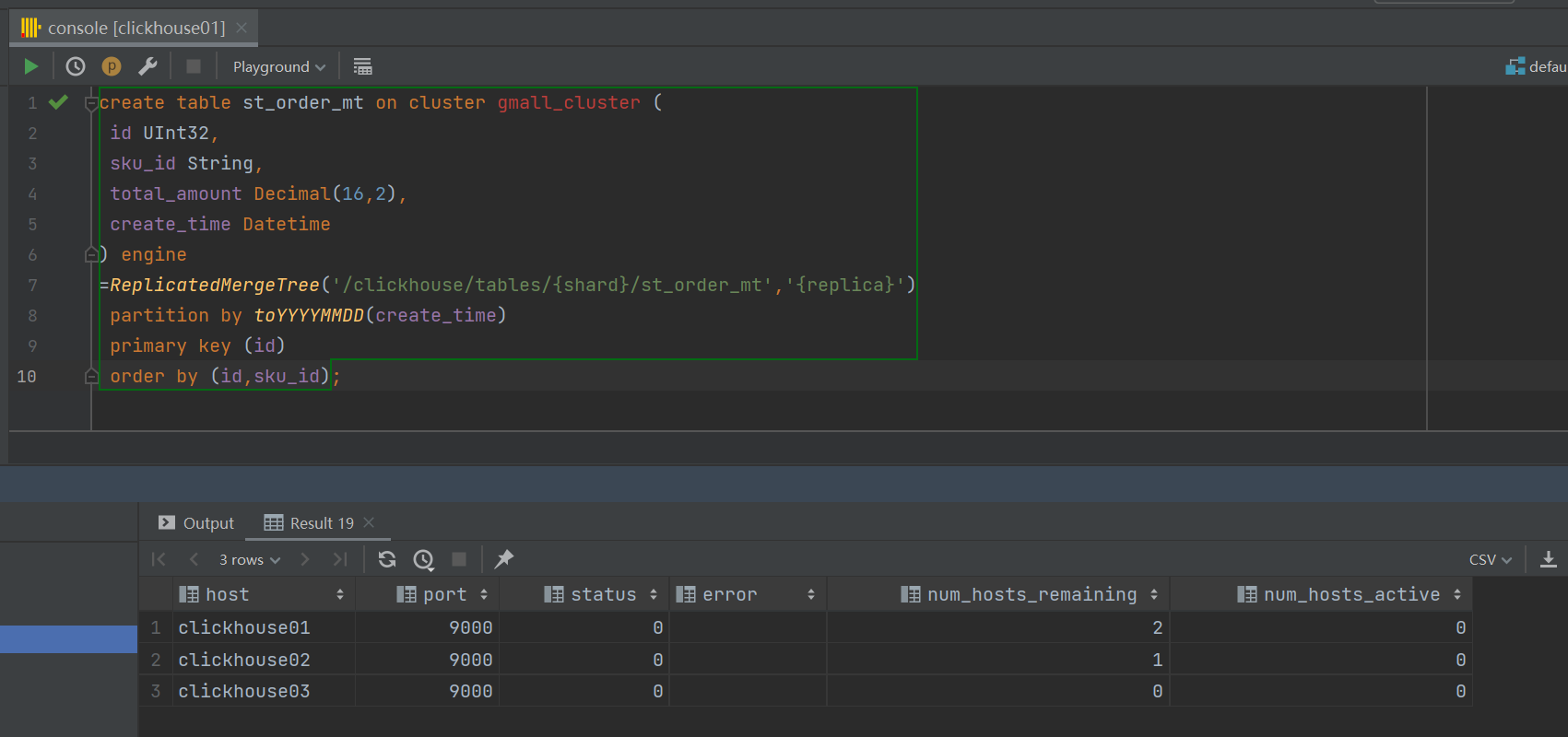
create table st_order_mt on cluster gmall_cluster (
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime
) engine
=ReplicatedMergeTree('/clickhouse/tables/{shard}/st_order_mt','{replica}')
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id,sku_id);![]()
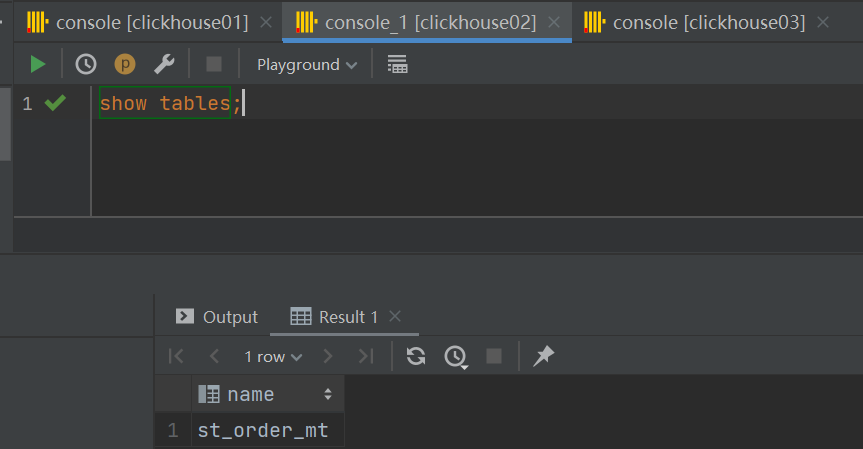
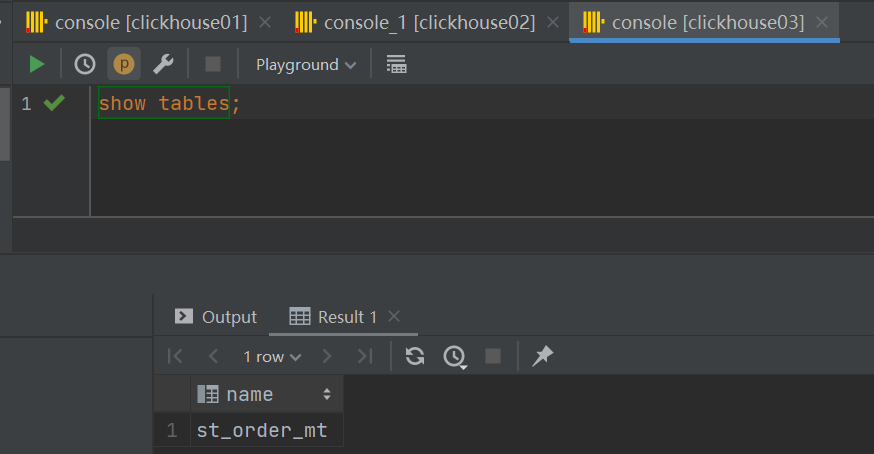
可以查看到clickhouse02和clickhouse03上查看表已经自动创建成功:
![]()
![]()
在clickhouse01上创建Distribute分布式表:
- Distributed(集群名称,库名,本地表名,分片键) 。
- 分片键必须是整型数字,所以用hiveHash函数转换,也可以rand()。
1
2
3
4
5
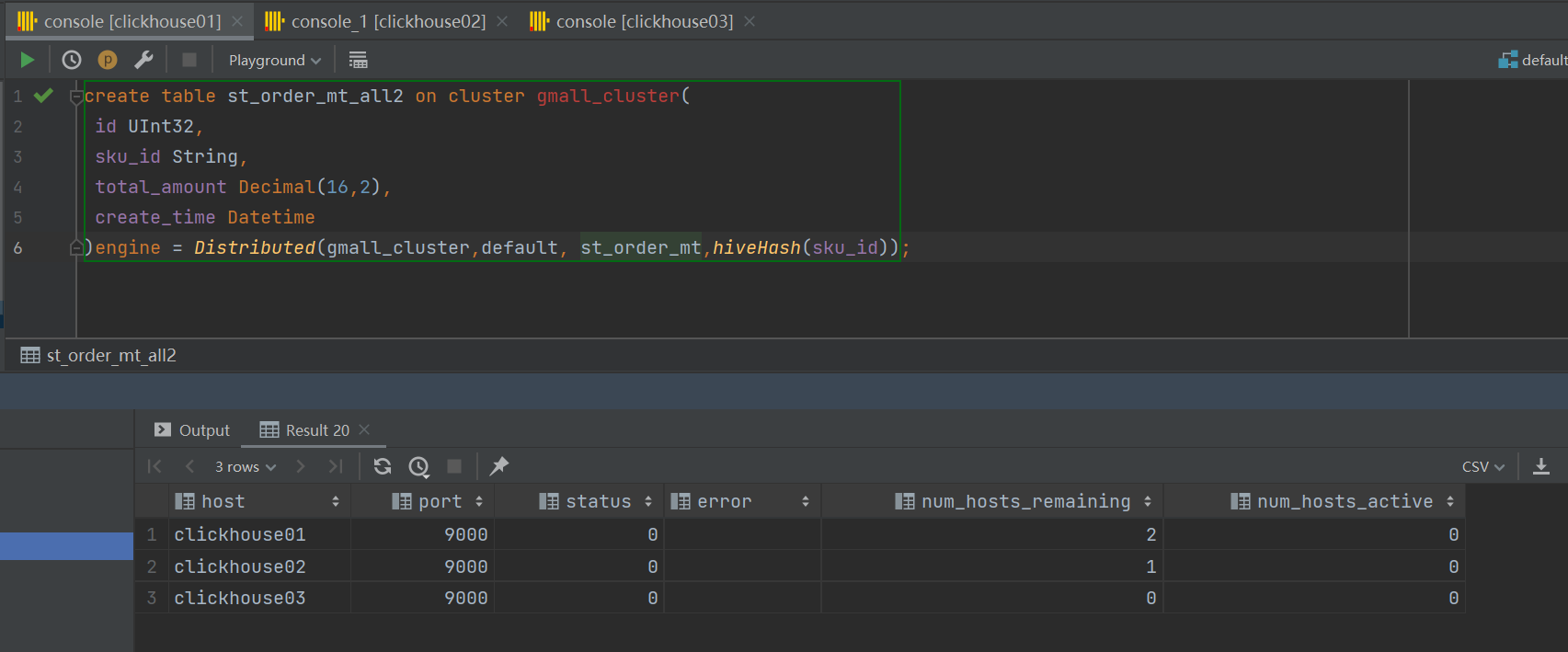
6create table st_order_mt_all2 on cluster gmall_cluster(
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime
)engine = Distributed(gmall_cluster,default, st_order_mt,hiveHash(sku_id));![]()
在clickhouse01上插入测试数据(分布式表本身不存储数据,它用于控制本地表数据的插入):
1
2
3
4
5
6insert into st_order_mt_all2 values
(201,'sku_001',1000.00,'2020-06-01 12:00:00') ,
(202,'sku_002',2000.00,'2020-06-01 12:00:00'),
(203,'sku_004',2500.00,'2020-06-01 12:00:00'),
(204,'sku_002',2000.00,'2020-06-01 12:00:00'),
(205,'sku_003',600.00,'2020-06-02 12:00:00');通过查询分布式表和本地表观察输出结果:
查看分布式表:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20clickhouse01 :) SELECT * FROM st_order_mt_all2;
SELECT *
FROM st_order_mt_all2
Query id: 8c348bd8-85b6-47f6-923e-4a913825c570
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 202 │ sku_002 │ 2000 │ 2020-06-01 12:00:00 │
│ 203 │ sku_004 │ 2500 │ 2020-06-01 12:00:00 │
│ 204 │ sku_002 │ 2000 │ 2020-06-01 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 201 │ sku_001 │ 1000 │ 2020-06-01 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 205 │ sku_003 │ 600 │ 2020-06-02 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
5 rows in set. Elapsed: 0.004 sec.查看本地表:
1
2
3
4
5
6
7
8
9
10
11
12
13
14clickhouse01 :) SELECT * FROM st_order_mt;
SELECT *
FROM st_order_mt
Query id: 93429dad-3dcc-48b3-82ff-ac1a74505377
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 202 │ sku_002 │ 2000 │ 2020-06-01 12:00:00 │
│ 203 │ sku_004 │ 2500 │ 2020-06-01 12:00:00 │
│ 204 │ sku_002 │ 2000 │ 2020-06-01 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
3 rows in set. Elapsed: 0.002 sec.1
2
3
4
5
6
7
8
9
10
11
12
13
14clickhouse02 :) SELECT * FROM st_order_mt;
SELECT *
FROM st_order_mt
Query id: 8c62441f-4747-405c-8496-e63200cb74ce
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 202 │ sku_002 │ 2000 │ 2020-06-01 12:00:00 │
│ 203 │ sku_004 │ 2500 │ 2020-06-01 12:00:00 │
│ 204 │ sku_002 │ 2000 │ 2020-06-01 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
3 rows in set. Elapsed: 0.002 sec.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15clickhouse03 :) SELECT * FROM st_order_mt;
SELECT *
FROM st_order_mt
Query id: 968d06d7-c3b1-4639-a4fa-34f714e6d4c9
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 201 │ sku_001 │ 1000 │ 2020-06-01 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 205 │ sku_003 │ 600 │ 2020-06-02 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
2 rows in set. Elapsed: 0.002 sec.